机器学习第四讲
第四讲、模型提升
1.模型误差的来源

2.非线性模型
从线性模型到非线性模型;
线性回归:多项式回归;
支持向量机:给定的核函数组合,基本属于"猜测”;
决策树:空间划分的思想来处理非线性数据。
3.深度学习
感知机:线性回归+简单的非线性映射;
多层感知机:多层神经元的组合,多个简单非线性函数的复合;
深度学习:层数很大。
4.模型集成
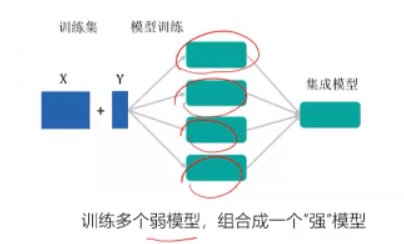
“三个臭皮匠,赛过诸葛亮",臭皮匠之间要各有所长。
目的:降低误差

5.决策树
①把问题问到点子上
流感诊断:望闻问切——头痛?发热?等等,诊断结果为感冒或流感;
银行放贷决策:借贷人基本信息——收入?教育程度?婚姻状况?等。
②空间的方块划分
③决策树生成
核心问题:如何选择节点属性和属性分割点。
不纯度(impurity):表示落在当前节点的样本类别分布的均衡程度;
节点分裂后,节点不纯度应该更低(类分布更不均衡);
选择特征及对应分割点,使得分裂前后的不纯度(impurity)下降最大。
⑤Gini指数

⑥误分率
含义:当按照多数类来预测当前节点样本的类别时,被错误分类的数据的比例; 节点t的误分率为_Error(t)=1-max(p(1|t), p(2|t),...,p(Clt))。
⑦随机森林算法流程

6.AdaBoost

