redis主从复制初识
一、作用
-
slave会通过被复制同步master上面的数据,形成数据副本
-
当master节点宕机时,slave可以升级为master节点承担写操作。
-
允许有一主多从,slave可以承担读操作,提高读性能,master承担写操作。即达到读写分离
二、简单性质
-
一个master可以有多个slave
-
每个slave只能有一个master
-
每个slave也可以有自己的多个slave
-
数据流是单向的,从master到slave
三、创建主从的方式
1.slaveof命令
#在希望成为slave的节点中执行以下命令
slaveof ${masterIP} ${masterPort}
此过程会异步地将master节点中的数据全量地复制到当前节点中
2.通过配置实现
| 配置项 | 含义 |
|---|---|
| salveof ${masterIP} ${masterPort} | 设置当前节点作为其他节点的slave节点 |
| slave-read-only yes | 设置当前slave节点是只读的,不会执行写操作 |
3.取消主从的方式
#在不希望作为slave的节点中执行以下命令
salveof no one
执行完成之后,该节点的数据不会被清除。而是不会再同步master中的数据
4.查看当前节点是否主从
info replication
run_id与偏移量
1.run_id
run_id是Redis 服务器的随机标识符,用于 Sentinel 和集群,服务重启后就会改变;
当slave节点复制时发现和之前的 run_id 不同时,将会对数据进行全量同步。
查看runid
redis-cli -p 6379 info server | grep run
run_id:345dda992e5064bc80e01f96ea90f729b722b2ea
2.偏移量
通过对比主从节点的复制偏移量,可以判断主从节点数据是否一致。
-
参与复制的主从节点都会维护自身的复制偏移量。主节点(master)在处理完写命令后,会把命令的字节长度做累加记录,统计信息在info replication中的master_repl_offset指标中。
-
从节点每秒上报自身的复制偏移量给主节点,因此主节点也会保存从节点的复制偏移量
-
从节点在接收到主节点发送的命令后,也会累加记录自身的偏移量。统计在info replication中的slave_repl_offset指标中
全量复制
一、全量复制流程
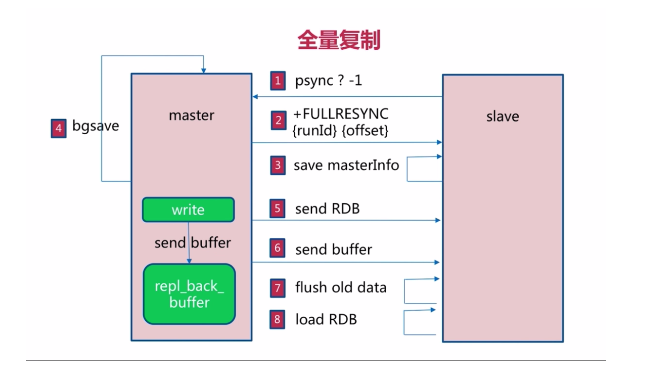
1.slave -> master : psync ? -1
-
? 代表当前slave节点不知道master节点的runid
-
-1代表当前slave节点的偏移量为-1
2.master -> slave : +FULLRESYNC runId offset
-
master通知slave节点需要进行全量复制
-
runId:master发送自身节点的runId给slave节点
-
offset:master发送自身节点的offset给slave节点
3.slave : save masterInfo
-
slave节点保存master节点的相关信息(runId与偏移量)
4.master : bgsave
-
master节点通过bgsave命令进行RDB操作
###5.master -> slave : send RDB
-
master将bgsave完的RDB结果发送给slave节点
6.master -> slave : send buffer
-
master在执行写操作时,会将写命令写入repl_back_buffer中
-
为了维护bgsave过程中执行的写操作命令,并同步给slave,master将期间的buffer发送给slave。
7.slave : flush old data
-
slave节点将之前的数据全部清空
8.load RDB
-
slave节点加载RDB
二、全量复制的开销
-
bgsave时间
-
RDB文件网络传输时间
-
slave节点清空数据时间
-
slave节点加载RDB的时间
-
可能的AOF重写时间,当加载完RDB之后,如果开启了AOF重写,需要重写AOF,以保证AOF最新
三、全量复制的高版本优化
在redis4.0中,优化了psync,简称psync2,实现了即使redis实例重启的情况下也能实现部分同步
部分复制
一、部分复制流程
1.slave -> master : Connection lost
-
由于网络抖动等原因,slave对master的网络连接发生中断
2.slave -> master : Connection to master
-
slave重新建立与master节点的连接
3.slave -> master : psync runId offset
-
slave节点发送master节点的runId以及自身的offset
4.master -> slave :CONTINUE
-
在第③步中,master节点校验offset,在当前buffer的范围中,则将反馈从节点CONTINUE表示部分复制。
-
如果offset不在当前buffer的范围中,则将反馈从节点FULLRESYNC表示需要全量复制
-
buffer的大小默认为1MB,由repl_back_buffer维护
5.master -> slave : send partial data
-
发送部分数据给slave节点让slave节点完成部分复制
故障处理
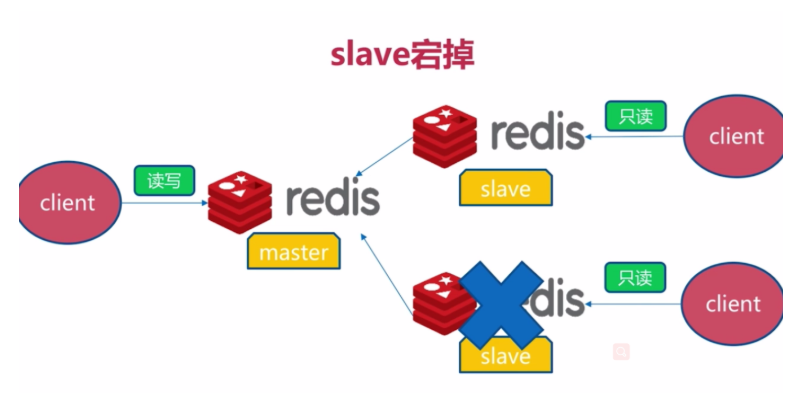
一、slave宕机故障
-
会影响redis服务的整体读性能,对系统可用性没有影响,将slave节点重新启动并执行slaveof即可。
-
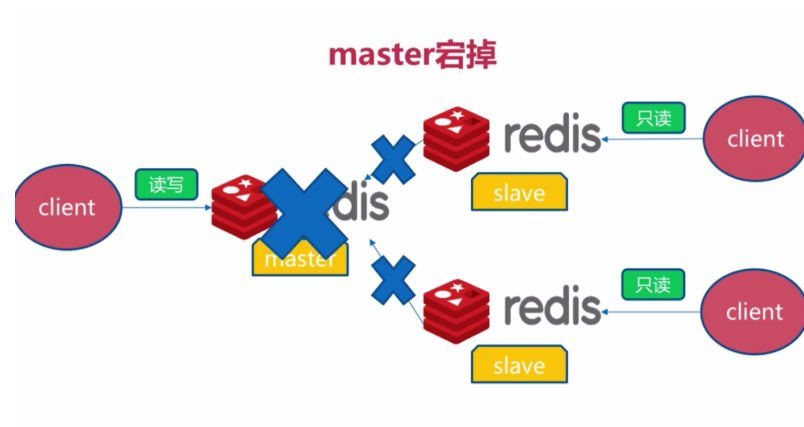
二、master宕机故障
-
redis将无法执行写请求,只有slave节点能执行读请求,影响了系统的可用性
-
方法1:
-
随机找一个节点,执行slaveof no one,使其成为master节点
-
然后对其他slave节点执行slaveof newMatserIp newMasterPort
-
-
方法2:
-
马上重启master节点,它将会重新成为master
-
开发与运维中的问题
一、读写分离
-
含义:master只承担写请求,读请求分摊到slave节点执行
-
可能遇到的问题
-
复制数据延迟
-
当写操作从master同步到slave的时候,会有很短的延迟
-
当网络原因或者slave阻塞时,会有比较长的延迟
-
在这种情况下,可以通过配置一个事务中的读写都在主库得已实现
-
可以通过偏移量对这类问题进行监控
-
-
读到过期数据(在v3.2中已经解决)
-
删除过期数据的策略1:操作key的时候校验该key是否过期,如果已经过期,则删除
-
删除过期数据的策略2:redis内部有一个定时任务定时检查key有没有过期,如果采样的速度比不上过期数据的产生速度,会导致很多过期数据没有被删除。
-
在redis集群中,有一个约定,slave节点只能读取数据,而不能操作数据
-
-
从节点故障
-
二、配置不一致
-
maxmemory不一致:可能会丢失数据
-
例如master配置为4G,从节点配置为2G。
-
-
数据结构优化参数(例如hash-max-ziplist-entries):导致内存不一致
三、规避全量复制
-
第一次全量复制
-
第一次不可避免
-
小主节点(数据分片),低峰处理(夜间)
-
-
节点运行ID不匹配
-
主节点重启(运行ID变化)
-
可以使用故障转移进行处理,例如哨兵或集群。
-
-
复制积压缓冲区不足
-
如果offset在缓冲区之内,则可以完成部分复制,否则需要全量复制
-
可以增大复制缓冲区的大小:rel_backlog_size,默认1M,可以提升为10MB
-
四、规避复制风暴
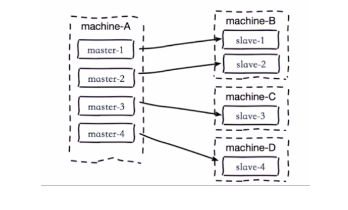
1.单主节点复制风暴
-
问题:主节点重启,多从节点复制
-
解决:更换复制拓扑,由(m-s1,s2,s3)的模式改成(m-s1-s1a,s1b)的模式,可以减轻master的压力
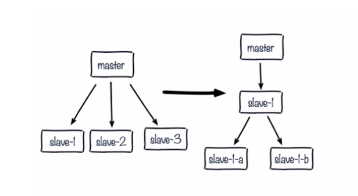
2.单机器复制风暴
-
如下图:机器宕机后,大量全量复制
-
解决:主节点分散多机器