
索引的优点
- 索引大减少了服务器需要扫描的数据量。
- 索引可以帮助服务器避免排序和临时表。
- 索引可以随机
I/O变成顺序I/O。
独立的列
- 独立的列将不能使用索引,独立的列是指索引列不能是表达式的一部分,也不能是函数的参数,比如:
select actor_id from actors where actor_id + 1 = 5; - 该方式等价于
actor_id=4,但是mysql无法解析。同样函数也是一样的,所以在使用时,始终需要将索引单独放在比较符号的一侧。
前缀索引和索引选择性
-
有时候需要索引很长的字符列,这会让索引变得大且慢,一个策略是使用哈希索引,将该列进行哈希,然后将哈希值存储到一个新列中去,每次查询时就通过哈希值进行索引,提高查询效率。
-
除了哈希索引之外,还可以索引前缀的部分字符,这样能大约节约索引空间,提高索引效率。但是这样也会降低索引的选择性。索引选择性是指,不重复的索引值(也称为基数)和数据表的记录总数(total)的比值,范围从1/total到1之间。索引选择越高,查询效率越高,因为它可以让mysql过滤掉更多的行。唯一索引的选择性是1,这是最好的索引选择性,性能也是最好的。
-
一般情况下,某个列前缀选择性是足够高的,足以满足查询性能,对于
BLOB、TEXT或者很长的VARCHAR类型的列,必须使用前缀索引,因为mysql不允许索引整个列。 -
诀窍在于要选择足够长的前缀来保证较高的选择性,同时又不能太长,以便节约空间。前缀需要足够长,以使得前缀索引的选择性接近索引整个列,也就是说,前缀的“基数”应该接近于完整列的“基数”。
-
为了找到合适的前缀长度,所以需要对计算原始的表的中索引选择性,然后通过枚举前缀长度来使前缀索引的选择索引性尽可能的接近原始的字符串的索引选择性,计算原始表中索引的选择性:
select count(distinct col) / count(*) from table_; -
计算前缀索引的选择性,代码中
length就是前缀的长度:select count(distinct left(col, length)) / count(*) from table_; -
如果前缀索引的选择性比较接近原始字符串的索引选择性,并且出现的频率和原始表基本一致,基本上就可以使用了。
-
找到合适的前缀长度就可以创建前缀索引了,其中
length就是所求的前缀长度:alter table table_ add key (col(length)); -
前缀索引是一种能够使索引更小、更快的有效办法,但是也有其缺点:
mysql无法使用前缀索引做order by和group by,也无法使用前缀索引做覆盖扫描。 -
前缀索引一个很常见的的场景是对很长的十六进制唯一ID进行索引,使用长度为8位的前缀索引通常能显著提升性能,而且这种方式对上层应用是完全透明的。
-
除了前缀索引,还有后缀索引,比如可以用来查找某域名的所有电子邮件地址等。
多列索引
-
在多个列上建立独立的索引大部分情况下并不能提高
mysql的查询性能。mysql5.0和更新的版本引入一种叫索引合并的策略,可以在一定程序上使用表上的多个单个索引来定位指定的行。更早的版本只能使用其中某一个单列索引,然后在这种情况下没有哪一个独立的单列索引是非常有效的。例如,表film_actor在字段film_id和actor_id上各一个单列索引,但对下面个单列索引都不是好的选择:select film_id, actor_id from film_actor where actor_id = 1 or film_id = 1; -
在老版的
mysql版本中,会对这个查询进行全表扫描。除非你改写成如下的两个查询union的方式:select film_id, actor_id from film_actor where actor_id = 1 union all select film_id, actor_id from film_actor where film_id = 1 and acotr_id != 1; -
但是在新版本
mysql5.0和更新的版本中,查询能够同时使用这两个单列索引进行扫描,并将结果进行合并。这种算法有三个变种:or条件的联合union,and条件的相交intersection,组合前两种情况的联合和相交。比如下面的查询就是使用了两个索引扫描的联合,通过explan的extra列可以看出来:explain select film_id, actor_id from film_actor where actor_id = 1 or film_id = 1\G;
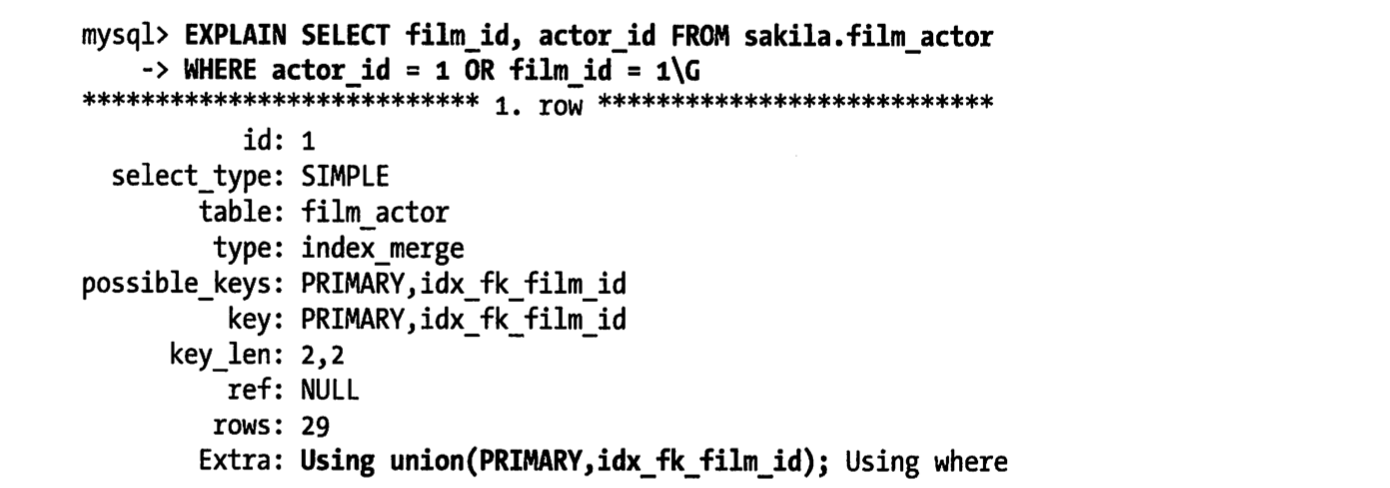
-
msyql会使用这类技术优化复杂查询,所以在某些语句的extra列中还可以看到嵌套操作。索引合并策略有时候是一种优化的结果,但实际上更多时候说明了表上索引的建得很糟糕:- 当出现服务器对多个索引做相交操作时(通常有多个
and条件),通常意味着需要一个包含所有相关列的多列索引(联合索引),而不是多个独立的单列索引。 - 当服务器需要对多个索引做联合操作时(通常有多个
or条件),通常需要耗费大量CPU和内存资源在算法的缓存、排序和合并操作上。特别是当其中有些索引的选择性不高,需要合并扫描返回的大量数据的时候。 - 更重要的是,优化器不会把这些计算到“查询成本”中,优化器只关心随机页面读取。这会使得查询的成本被“低估”,导致该执行计划还不如直接走全表扫描。这样做不但会消耗更多的
CPU和内存资源,还可能会影响查询的并发性,但如果是单独运行这样的查询则往往会忽略对并发性的影响。通常来说,还不如像在mysq4.1以前一样,将查询改写成union方式更好。
- 当出现服务器对多个索引做相交操作时(通常有多个
-
如果在
explain中看到有索引合并,应该好好检查一下查询和表的结构。也可以通过参数optimizer_switch来关闭索引合并功能。也可以使用ignore index提示让优化器忽略掉某些索引。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号