
决战圣地玛丽乔亚Day47----Redis集群
4.Redis Cluster 集群模式
如果单机吞吐量过大,我们可以横向和纵向进行扩展,横向就是加节点(scale out),纵向就是加配置(scale up)。
如果加配置,治标不治本,单机局限性和持久化问题无法解决(如轮式RDB快照还是AOF指令)
横向扩展更容易扩展,可以解决很多问题,包括单一实例节点的硬件扩容限制、成本限制,还可以分摊压力,精细化治理,精细化维护
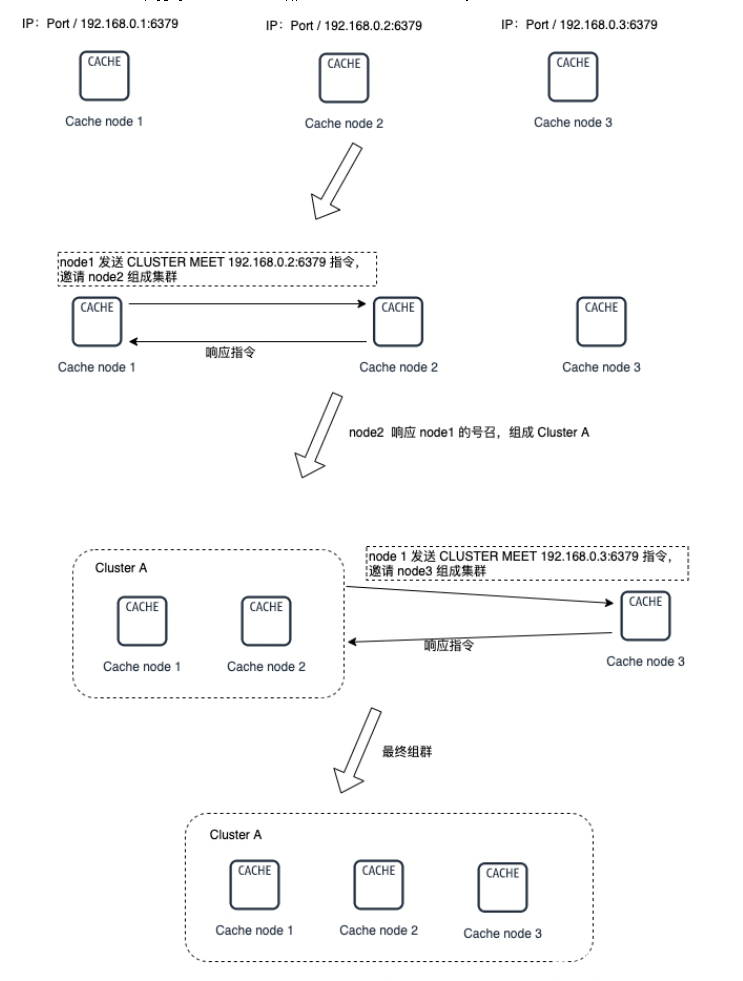
集群的组成:
CLUSTER MEET <ip> <port>
数据自动分片:
cluster create 创建,会将 16384 个slots 平均分配在我们的集群实例上
通过 addslots 命令指定哈希槽范围
cluster addslots 0,7120redis-cli -h 192.168.0.2 –p 6379
通过一致性哈希算法把数据分到2^14个哈希槽中,每个节点负责一部分的槽位数据(自定义分配),节点之间通过goosip协议进行通信,更新信息,故障转移和故障检测。
如果请求所在的节点不是负责该槽位的节点,那么请求会被转发到负责该槽位的节点上。如果请求的键名所在的槽位没有被分配到任何节点上,那么Redis Cluster会返回一个错误信息
集群处于online状态说明数据对应的槽位都有节点进行管理,如果状态为offline说明有数据对应的槽位没有被任何节点管理。
数据复制过程和故障转移
数据复制 :
主从模式,master宕机会把从节点拿过来作为主节点。
故障检测
Redis的节点之间通过Gossip协议广播信息,每个节点定期的去ping--->主观下线和客观下线。对应前面讲的哨兵模式。
主从故障转移
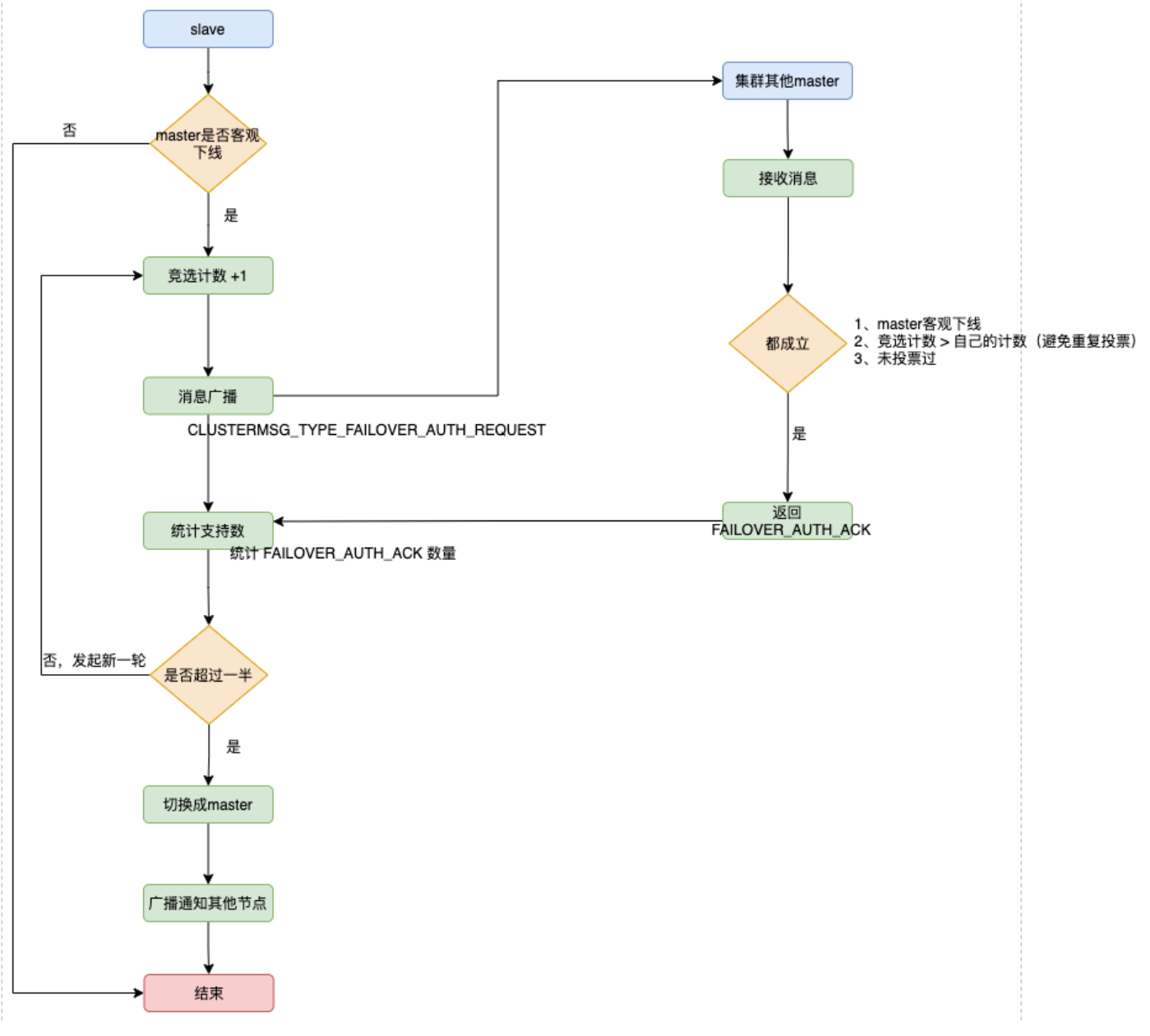
基于raft的选举模式:
-
- 集群中设立一个自增计数器,初始值为 0 ,每次执行故障转移选举,计数就会+1。
- 检测到主节点下线的从节点向集群所有master广播一条CLUSTERMSG_TYPE_FAILOVER_AUTH_REQUEST消息,所有收到消息、并具备投票权的主节点都向这个从节点投票。
- 如果收到消息、并具备投票权的主节点未投票给其他从节点(只能投一票哦,所以投过了不行),则返回一条CLUSTERMSG_TYPE_FAILOVER_AUTH_ACK消息,表示支持。
- 参与选举的从节点都会接收CLUSTERMSG_TYPE_FAILOVER_AUTH_ACK消息,如果收集到的选票 大于等于 (n/2) + 1 支持,n代表所有具备选举权的master,那么这个从节点就被选举为新主节点。
- 如果这一轮从节点都没能争取到足够多的票数,则发起再一轮选举(自增计数器+1),直至选出新的master。
-
新的主节点会撤销所有对已下线主节点的slots指派,并将这些slots全部指派给自己。
-
新的主节点向集群广播一条PONG消息,这条PONG消息可以让集群中的其他节点立即知道这个节点已经由从节点变成了主节点,并且这个主节点已经接管了原本由已下线节点负责处理的槽。
-
新的主节点开始接收和自己负责处理的槽有关的命令请求,故障转移完成。
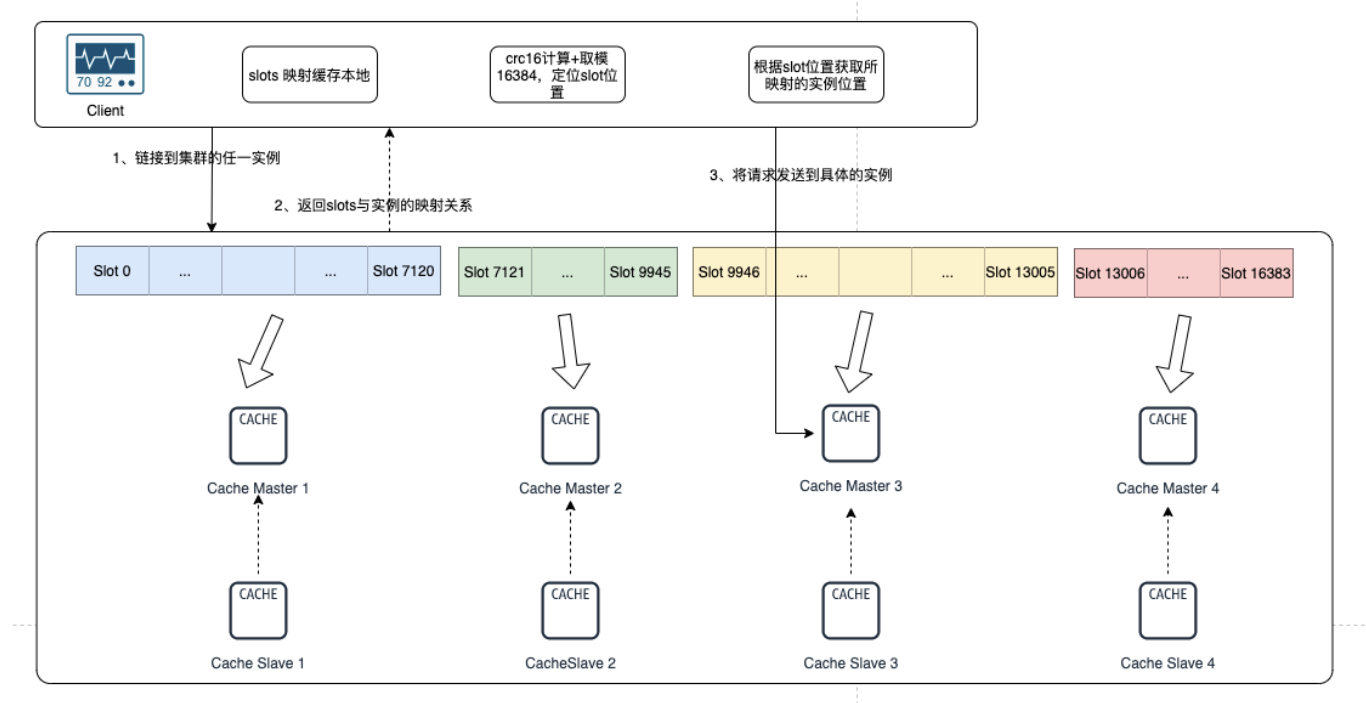
client 访问 数据集群的过程
Redis每个实例节点会通过Gossip协议把哈希槽的分配信息进行扩散。相当于每个集群都有一个集群哈希槽对应哪个实例的注册表。
客户端连接任一实例,获取到slots与实例节点的映射关系,并将该映射关系的信息缓存在本地。
将需要访问的redis信息的key,经过CRC16计算后,再对16384 取模得到对应的 Slot 索引。
通过slot的位置进一步定位到具体所在的实例,再将请求发送到对应的实例上。
Redis集群和主从复制+哨兵机制这种模式有什么区别?
Redis集群通过把Redis数据进行分片存储在多个Redis节点来实现横向扩展和高可用性,适合大规模的Redis部署。
如果是小规模,用主从复制+哨兵模式就可以。
另外注意纯主从+哨兵的模式用的是读写分离,而redis集群技术的从节点就是一个主的备用,合理的来说应该是主备模式。
Redis6.0后的多线程:
为什么要用多线程?多线程相比单线程解决了什么问题?
Redis对CPU计算力的要求并不迫切,相反单线程机制让 Redis 内部实现的复杂度大大降低,同时降低了因为上下文切换和资源竞争造成的性能损耗。那既然单线程这么好用,为什么要引入多线程模式?
Redis的性能瓶颈逐渐体现在网络IO的读写上,单个线程处理网络 I/O 读写的速度跟不上底层网络硬件执行的速度。
6.0之前:
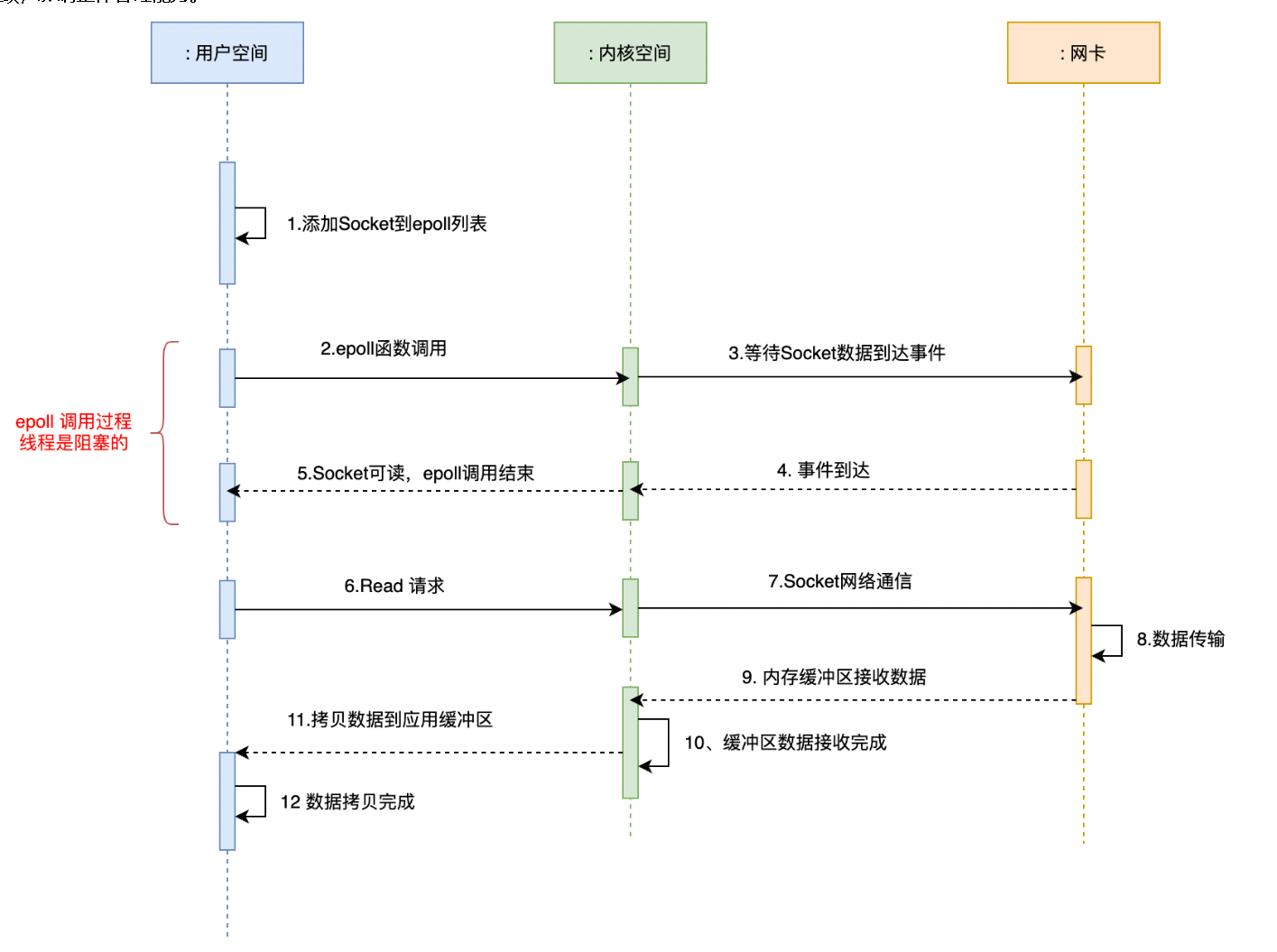
6.0之后:
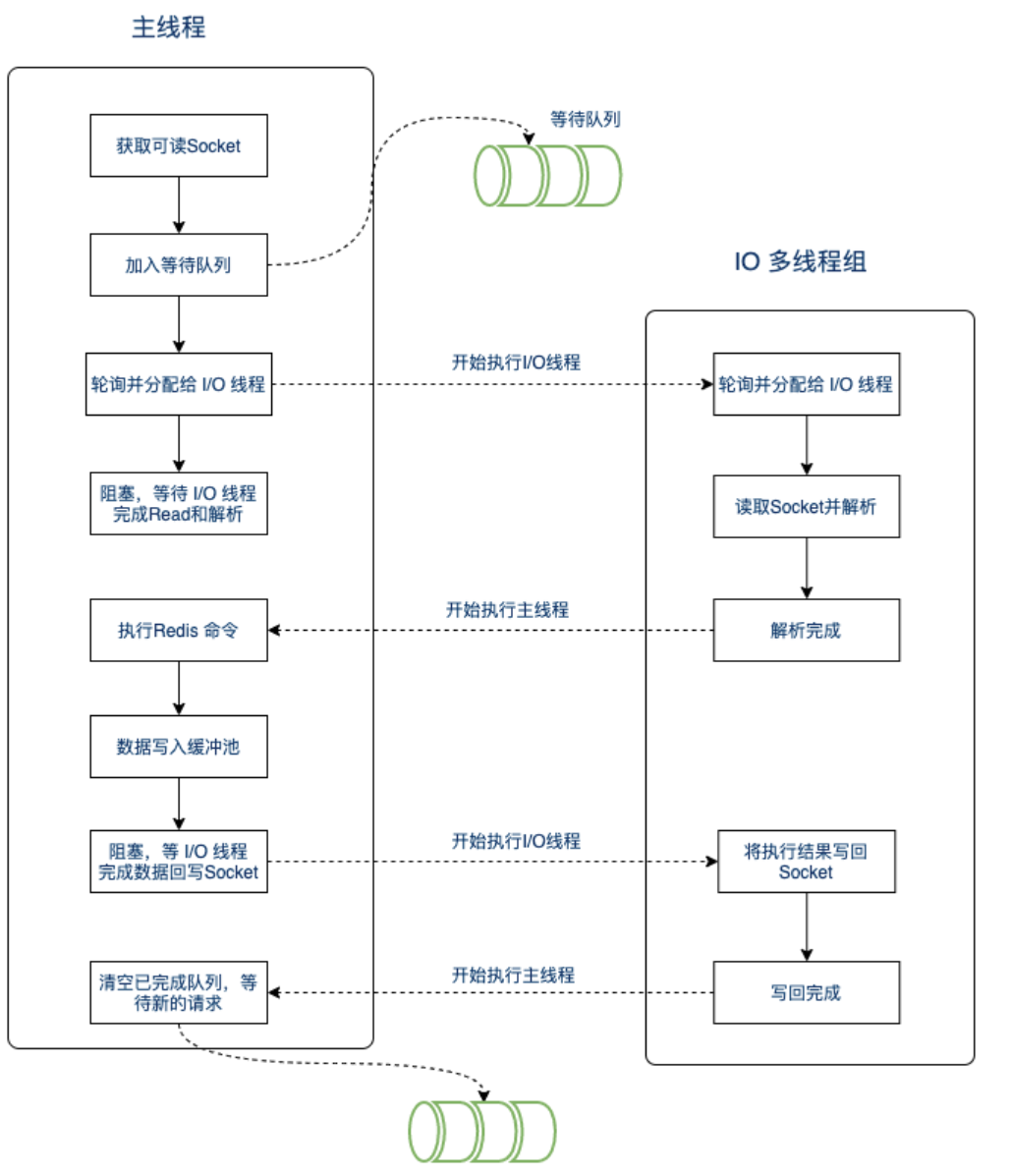
具体步骤如下:
- 主线程建立连接,并接受数据,并将获取的 socket 数据放入等待队列;
- 通过轮询的方式将 socket读取出来并分配给 IO 线程;
- 之后主线程保持阻塞,一直等到 IO 线程完成 socket 读取和解析;
- I/O 线程读取和解析完成之后,返回给主线程 ,主线程开始执行 Redis 命令;
- 执行完Redis命令后,主线程阻塞,直到IO 线程完成 结果回写到socket 的工作;
- 主线程清空已完成的队列,等待客户端新的请求。
本质上是将主线程 IO 读写的这个操作 独立出来,单独交给一个I/O线程组处理。
这样多个 socket 读写可以并行执行,整体效率也就提高了。同时注意 Redis 命令还是主线程串行执行。
Redis6.0的多线程默认是禁用的,只使用主线程。如需开启需要修改redis.conf配置文件:
# io-threads-do-reads no io-threads-do-reads yes
# 假设你的CPU核数是8核,尽量配置成 5~6
io-threads 5
官方有一个建议:4 核的机器建议设置为 2 或 3 个线程,8核的建议设置为 6 个线程,线程数一定要小于机器核数。
线程数并不是越大越好,官方认为超过了 8 个就很难继续提效了,没什么意义。
同时6.0官方退出了redis-cluster-proxy,
redis cluster是redis的官方集群方案,但是他要求客户端自己做重定向,所以连接单机redis和集群redis的客户端会有些不同,连接集群版redis的时候要客户端连接6个redis实例。
官方为了屏蔽这种差异,做了一个redis-cluster-proxy,经过这个proxy的代理后,连接redis集群就和连接单机redis一样了。
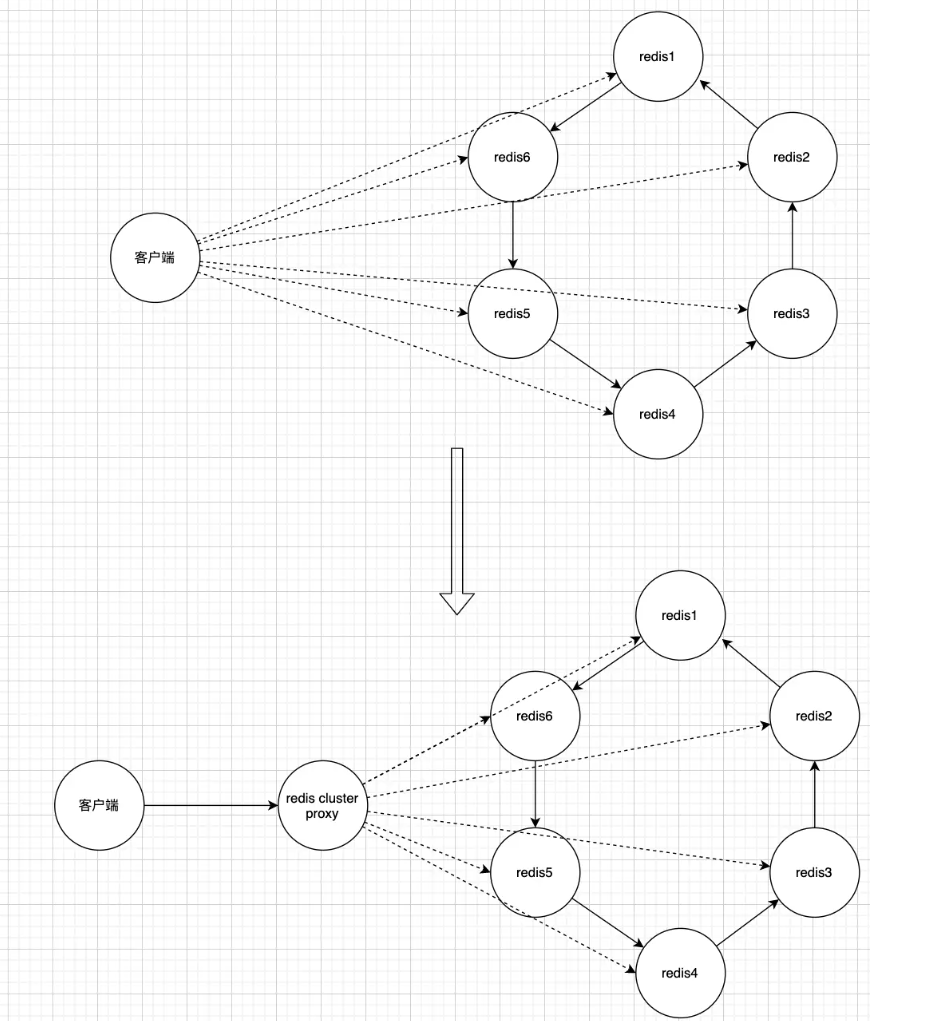
这个redis-cluster-proxy不是很稳定,很多命令的支持有缺陷。慎用,知道即可。
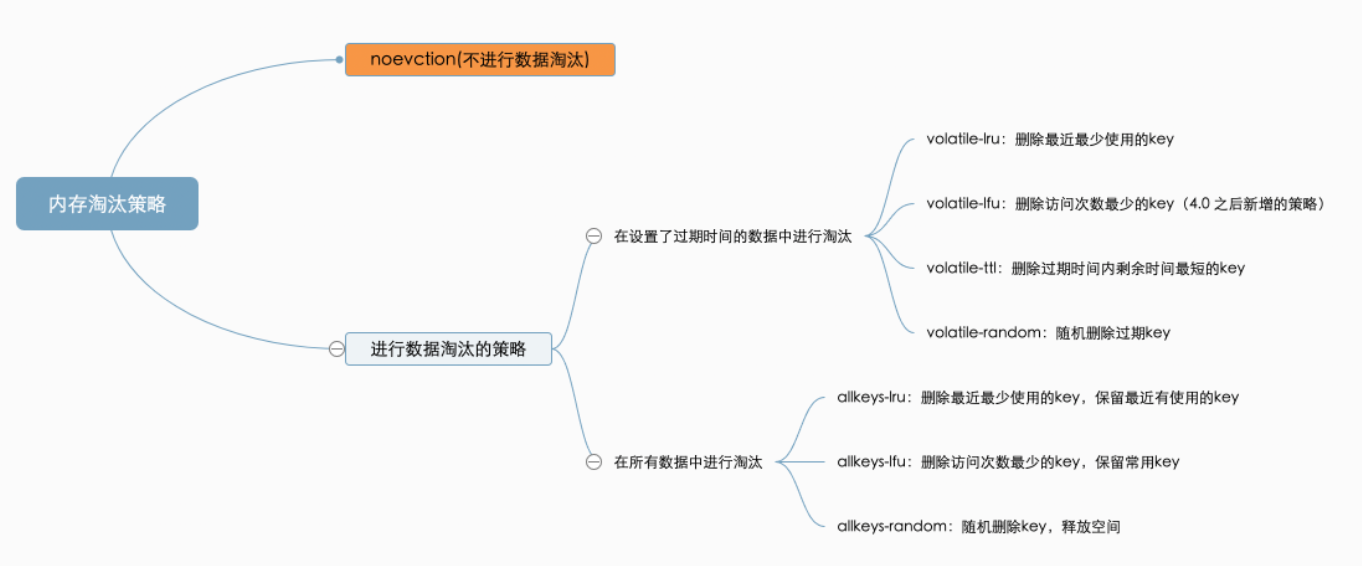
内存淘汰策略:


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 单元测试从入门到精通
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 上周热点回顾(3.3-3.9)
· winform 绘制太阳,地球,月球 运作规律