

决战圣地玛丽乔亚Day43--SpringBoot的自动装配原理 + Redis开篇
Springboot的自动装配原理:
@SpringBootApplication
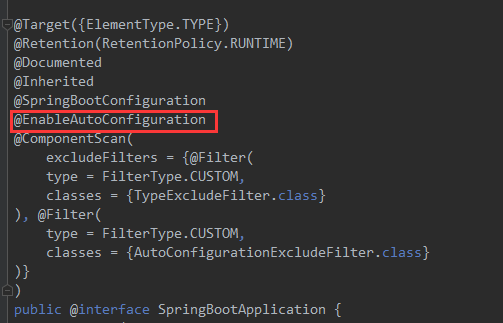
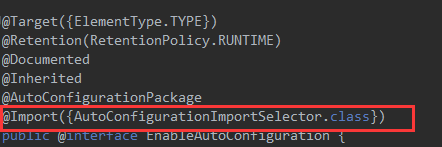
进入 AutoConfigurationImportSelector类中,会调用 selectImports(方法),用于选择需要自动配置的类,并返回它们的全限定类名数组

AnnotationMetadata 是被注解修饰的类或方法的元数据
这个selectImports主要获取被@Import注解修饰的类的元数据信息。该方法的主要作用是根据一些条件,选择需要导入的自动配置类。 具体来说,该方法的实现逻辑如下:
- 首先通过isEnabled方法判断当前是否需要执行自动配置导入操作。
- 如果需要执行自动配置导入操作,则通过AutoConfigurationMetadataLoader.loadMetadata方法加载自动配置元数据,并通过getAutoConfigurationEntry方法获取自动配置实体。
- 最后,通过autoConfigurationEntry.getConfigurations方法获取需要导入的自动配置类,并转换为String数组返回。
第一步.首先看一下loadMetadata

AutoConfigurationMetadataLoader读取classpath下的所有文件的META-INF/spring-autoconfigure-metadata.properties文件,并将其中的元数据信息合成到一起加载到AutoConfigurationMetadata接口的实现类中。
在加载完成后,获得一个合并了各种自动配置元数据的AutoConfigurationMetadata就可以用于支持自动配置的各种功能,例如条件判断、自动配置类的加载等。 参数classLoder是类加载器,用于加载自动配置元数据信息。
第二步.

这个方法用于返回自动配置类的全限定类名、条件匹配器、属性源。并把他们封装在AutoConfigurationImportSelector类的内部类AutoConfigrationEntry中
看源码:
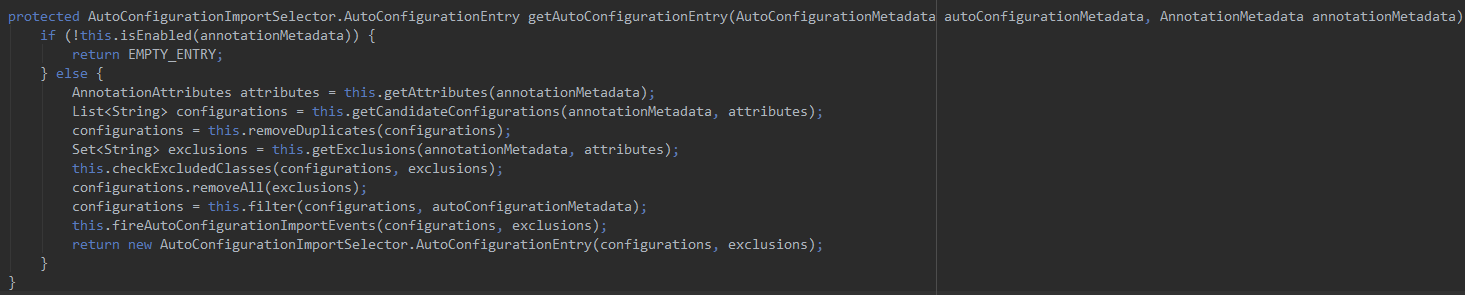

这里使用SpringFactoriesLoader来加载JAR包下面的META-INF/spring.factories文件
例如:spring-boot-autoconfigure-2.1.14.RELEASE.jar
下面的META-INF/spring.factories 很多东西。
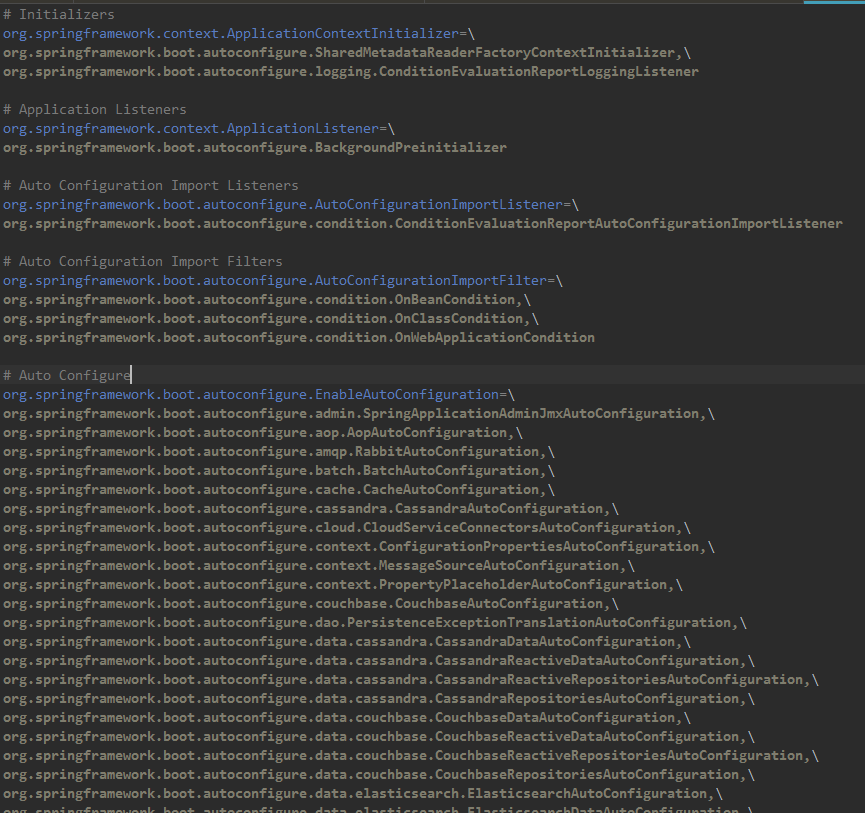


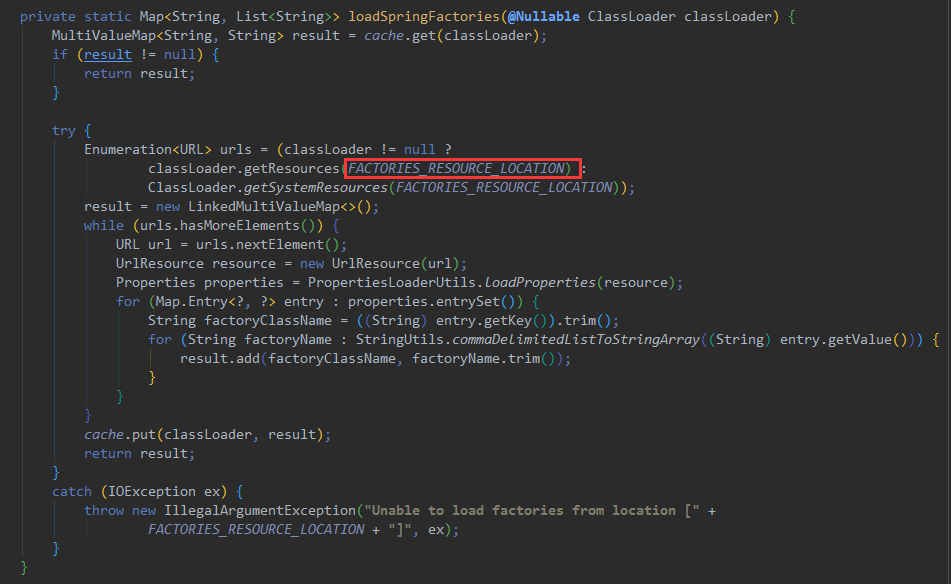
首先,该方法会从缓存中查找是否已经加载过该类加载器的spring.factories文件,如果已经加载过,则直接返回缓存中的结果。
如果缓存中没有该类加载器的结果,则会使用指定的类加载器或系统类加载器(如果指定的类加载器为null)加载META-INF/spring.factories文件,获取该文件中所有自动配置类的类名和对应的自动配置类名列表
对于每一个找到的spring.factories文件,该方法会使用PropertiesLoaderUtils.loadProperties()方法加载该文件中的所有属性,然后遍历每一个属性,将所有的属性值保存为一个列表返回。
最后,该方法会将所有自动配置类名和自动配置类名列表保存到一个MultiValueMap对象中,并将该对象缓存在cache中,以便下次使用同一个类加载器时可以直接返回缓存中的结果。 综上所述,该方法实现了从META-INF/spring.factories文件中加载自动配置类的功能,并使用缓存提高了性能。
getAutoConfigrationEntry最终返回的自动配置条目封装类:

- configurations:自动配置类的全限定类名,也就是实现自动配置的类。
- exclusions:排除自动配置的类的全限定类名数组。
- matched:是否匹配自动配置条件的标志,如果为false,则表示不需要自动配置。
- metadataReader:自动配置类的元数据读取器,用于读取自动配置类的元数据信息。
- propertySourceNames:属性源的名称数组,用于获取自动配置类的属性值。
- resource:自动配置类的资源对象,用于定位自动配置类的位置。
最后一步:

这行代码的作用是获取自动配置类的全限定类名数组,并将其转换成字符串数组返回。
其中,autoConfigurationEntry表示上面第二步获取的自动配置条目,getConfigurations()方法是AutoConfigurationEntry类中的方法,用于获取自动配置类的全限定类名数组。
最后我们就拿到了所有需要自动配置类的全限定名。
在后续Springboot用到某个功能,会检查自动配置类是否存在,如果存在会通过全限定名进行加载。
总结:
Spring Boot是通过Spring框架的@EnableAutoConfiguration注解和spring.factories文件来实现自动检查和自动加载自动配置类的。 具体来说,当我们在应用程序中使用某个特定的功能时,Spring Boot会自动检查该功能所需的自动配置类是否存在。具体的检查过程如下:
- Spring Boot会扫描classpath下所有的
META-INF/spring.factories文件,寻找其中所有实现了org.springframework.boot.autoconfigure.EnableAutoConfiguration接口的自动配置类。 - Spring Boot会根据当前应用程序的类路径和配置文件,确定需要的自动配置类,并将其传递给
spring.factories文件中所有自动配置类让他们自行检查是否满足条件(有一些是用了Conditional条件的)。 - 如果自动配置类中的
ConditionalOnXXX注解所指定的条件成立,那么该自动配置类就会被Spring Boot自动加载。 具体的自动加载过程如下:
Spring Boot会将所有需要自动配置的类的相关信息封装为AnnotationMetadata传递给EnableAutoConfigurationImportSelector类的selectImports()方法。
selectImports()方法会根据需要自动配置的功能列表和spring.factories文件中的自动配置类,生成一个自动配置类的全限定名数组。
Spring Boot会将该全限定名数组传递给AnnotationConfigApplicationContext类的构造函数,以便在应用程序启动时自动加载这些自动配置类。
cause:
AnnotationConfigApplicationContext类的构造函数可以接受一个或多个Java配置类的全限定名作为参数,这些配置类会被用来自动化配置应用程序的各个部分。在应用程序启动时,AnnotationConfigApplicationContext会读取这些配置类,然后根据其中的Bean定义来创建Bean实例,并将它们注册到应用程序上下文中。如果这些配置类中定义了一些自动配置类,那么这些自动配置类也会被加载并应用到应用程序中去。
综上所述,Spring Boot是通过@EnableAutoConfiguration注解和spring.factories文件来实现自动检查和自动加载自动配置类的。通过这种方式,Spring Boot可以根据当前应用程序的需求,自动加载所需的自动配置类,从而简化了应用程序的配置过程。
Redis缓存部分
一、缓存的高性能
首先要了解Redis的存储基本都是通过键值对json形式来存东西。
数据类型
String:
Redis的String是在内存存储,JAVA的String是在堆存储。
原因:1.存在内存上方便持久化 2.更快 3.内存数据存储空间更小,因为内存存储方式更紧凑
key对应的value用字节数组来存储
支持自增、自减、位运算等操作。
线程安全,可以多线程并发。
(因为Redis是单线程处理所有请求,保证以原子性方式处理每个请求)
但是要注意:Redis在执行命令的时候是单线程。在一些其他的方面通过多线程提高效率
如:Redis Cluster分布式实现,数据放在不同节点,使用多线程来处理读写请求
lua脚本的执行,多线程执行不同脚本
RDB和AOF:RDB时fork子线程持久化、AOF持久化时,使用异步I/O和事件驱动的方式实现多线程。
应用场景:缓存、计数器、分布式锁。
Hash:
数据结构 String:Hash表[field1:value1,field2:value2......]
我们可以使用HMSET key field1 value1 [field2 value2 ...]
来对一个key 对应的hash表设置不同的field对应的value
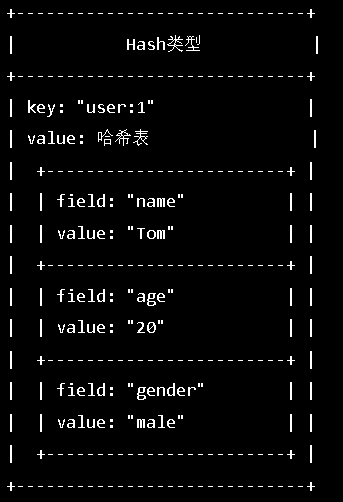
我们可以通过HGET user:1 name 取出Tom
使用场景:存储对象属性、计数器、缓存、聚合操作
由于Hash的value是一个hash表,天然适合存储对象,所以对象的存储操作可以考虑用Hash
List:
双向链表,支持头尾节点的操作(插入,删除),可以使用Sort命令对元素排序。
list:<key> = {<element_1> <element_2> ... <element_n>}
例如 RPUSH mylist 1 2 3
代表往mylist双向链表插入1 2 3三个,同时创建一个名为mylist的List数据结构
使用场景:
消费队列:将消息以List的形式存储在Redis中,生产者向列表尾部插入消息,消费者从列表头部弹出消息,实现类似于队列的功能
最新消息:将最新的消息以List的形式存储在Redis中,每次插入新消息时,将旧消息从列表头部删除,保持列表长度不超过指定值
计数器:将计数器的值以List的形式存储在Redis中,每次对计数器进行增减操作时,向列表尾部插入相应的值,获取计数器的值时,可以通过对列表元素进行求和得到。
排行榜:将用户的得分以List的形式存储在Redis中,每次用户得分变化时,更新对应的列表元素,获取排行榜时,可以通过对列表元素进行排序得到。
Set:
key:String类型的键名称
value:无序不重复元素集合
Hash表实现的无序集合。元素不允许重复,类型可以是字符串,数字,二进制数据等元素。
每个元素都被存储在哈希表中的一个桶(bucket)中,通过哈希函数将元素映射到不同的桶中,然后在桶中进行查找和操作
操作:
SISMEMBER命令:判断一个元素是否在Set中
SADD命令:向Set中添加一个或多个元素;
SREM命令:从Set中删除一个或多个元素
SINTER命令:获取多个Set的交集;
SUNION命令:获取多个Set的并集;
SDIFF命令:获取多个Set的差集
SCARD命令用于获取Set中元素的数量
使用场景:
去重:由于元素不重复,可以快速判断某个元素是否已经存在于SET中,避免重复数据产生。
标签和分类:Set可以用于存储对象的标签和分类信息。例如,可以将文章的标签存储在Set中,每个标签作为一个元素,然后通过SINTER命令获取包含所有标签的文章列表。同样可以将用户的兴趣分类信息存储在Set中,每个分类作为一个元素,然后通过SUNION命令获取共同兴趣的用户列表
点赞和收藏:Set可以用于实现点赞和收藏功能。例如,可以将一篇文章的点赞用户列表存储在一个Set中,每个用户作为一个元素,然后通过SCARD命令获取点赞总数,通过SISMEMBER命令判断某个用户是否已经点赞
排序:Set可以用于实现排序功能。例如,可以将商品的销售量、价格等信息存储在Set中,每个商品作为一个元素,然后通过SORT命令对Set进行排序,获取销售量最高、价格最低的商品列表。可以实现但是还是用sorted set更方便实现。
集合运算:Set可以用于实现集合运算。例如,可以将用户关注的用户列表存储在一个Set中,每个关注对象作为一个元素,然后通过SUNION、SINTER和SDIFF命令实现多个用户之间的关系运算
Sorted Set:
基于SkipList和HashTable的数据结构,有序存储元素及其分值。
Skip List用于存储元素及其分值,保证元素按照分值从小到大排序。
而Hash Table则用于存储元素和分值之间的映射关系,保证通过元素可以快速找到对应的分值
分值可以重复,但是成员唯一value
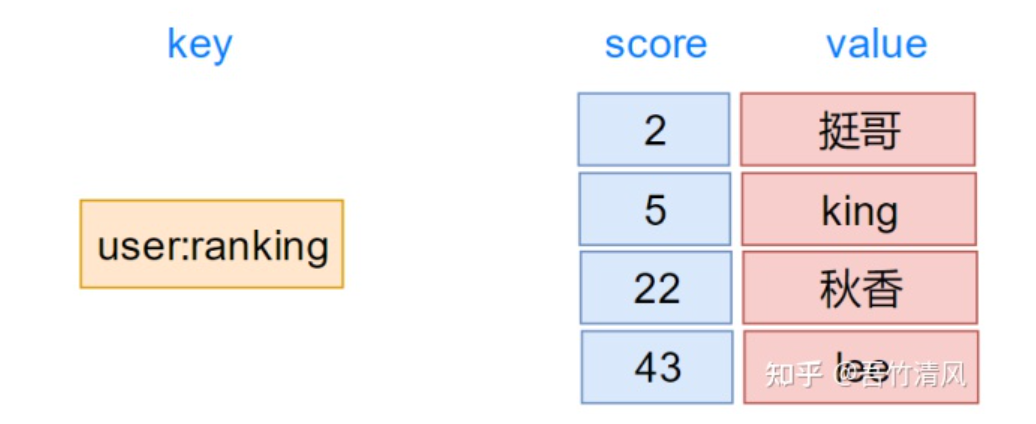
使用场景:
排行榜、计分板、任务队列
例如用sortedset实现排行榜功能:
使用ZADD命令向Sorted Set中添加成员和分值,其中成员可以是排名对象的唯一标识,分值可以是对象的得分、时间等信息
1 2 3 | ZADD rank 10001 "Tom"ZADD rank 20005 "Jerry"ZADD rank 30002 "Bob" |
rank是key,三个成员是10001,20005,30002
使用ZRANGE或ZRANGEBYSCORE命令获取排行榜数据,可以指定获取的范围和排序方式。
例如: ZRANGE rank 0 2 WITHSCORES
可以获取前三名分值
ZINCRBY rank 100 "Tom" 可以进行分值的增加
ZREVRANGE rank 0 2 WITHSCORES 获取倒序排名
ZREM rank "Tom" 删除排行榜的某个数据
在实际应用中,可以根据需要调整具体的实现方案,例如使用ZUNIONSTORE和ZINTERSTORE命令计算多个Sorted Set的并集和交集,实现更复杂的排行榜功能
存储方式
SDS特点
简单动态字符串:
兼容了一部分C语言的做法,并封装了自己的方法。
Int free; buf当前空闲空间长度
Int lines; 目前已经存储的空间; 查串长O1,降了时间复杂度
Char buff[]; free+lines+1个空串
动态扩展(空间预分配):
1.首先判断是否需要扩展:
字符串大小<=1MB,SDS扩展空间大小为当前字符串两倍
字符串大小>1MB,SDS扩展空间大小为1MB
2.判断空间是否足够进行扩展:
如果不够用,开辟一块大小为当前字符串长度+扩展空间大小
够用,直接用。
3.复制移动
如果是字符串大小大于1MB,扩展1MB的情况下。可能会出现原有的字符串长度大于需要扩展的长度,那么只把前N个长度移动到新内存中。(N为扩展长度)
如果是字符串小于扩展新内存,直接都移过去。
4.释放原有内存空间
SDS会释放原有的内存空间,将原有内存空间返回给内存管理器。
通过动态扩展,可以减少减少内存分配的次数,减少内存碎片。
惰性删除策略:
在进行缩容操作时,Redis会将SDS多余的内存空间标记为可用空间,并将可用空间的长度保存在SDS头部的free属性中。
此时,SDS的实际长度会变成缩容后的长度,而多余的空间并不会立即释放,而是等待被下一次扩容操作使用
当SDS需要进行扩容操作时,Redis会先检查SDS头部的free属性,看是否有可用空间可以使用。如果有可用空间,则Redis会将可用空间的长度加入到扩容后SDS需要分配的内存空间中,并将多余的空间保留下来,以备后续使用。如果没有可用空间,则Redis会按照SDS的空间预分配策略分配新的内存空间。
二进制存储:安全。即SDS本身并不关心存储的数据是字符串还是二进制数据,而是将存储的数据当作无符号字符序列来处理
无符号字符序列可以保证二进制安全的原因是,无符号字符序列可以表示任何二进制数据,而且不会将二进制数据中的任何字节解释为特殊字符,从而保证了数据的完整性和安全性。
跳跃表
Zset就是跳表+hash表来实现的。
跳表通过索引层来减少IO的次数,上层节点的个数是下层节点个数的一半,且尽量是随机均匀的,这样就可以节省一半的遍历次数。
跳表是典型的空间换时间的数据结构。
Redis的优化:
Redis引入了压缩跳表节点的优化方案,将节点的空间占用减小为16字节
Redis采用了自己的内存分配器,称为jemalloc。在跳表中,每次插入新节点时,Redis会从jemalloc中分配一段连续的内存空间,然后将这段空间划分为多个跳表节点。这种设计可以减少内存碎片,提高内存使用效率。
在插入和删除节点时,需要更新跳表索引中的指针。为了提高更新效率,Redis采用了一种延迟更新的策略。即在插入和删除节点时,先不更新跳表索引中的指针,而是将更新操作缓存起来,等到需要访问索引时再进行更新。这种设计可以避免频繁的索引更新,提高了插入和删除操作的效率。
Redis的跳表结构中,有一些参数可以进行优化。例如,跳表的最大层数、跨度节点的数量等等。通过调整这些参数,可以优化跳表的性能和空间占用。在Redis中,这些参数都是可以通过配置文件或命令行参数进行设置的。
IO模型的选择:
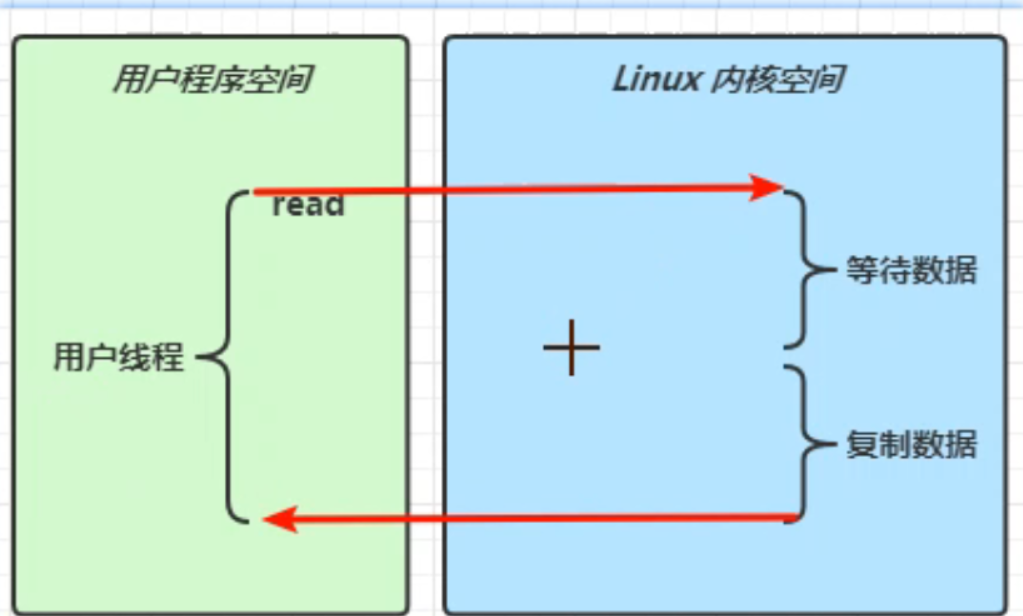
同步阻塞 IO 模型(同步阻塞 I/O Model,Blocking IO Model): Redis 默认采用的是同步阻塞 IO 模型。在这种模型下,Redis 服务器使用一个线程来处理所有客户端的请求,所有的 I/O 操作都是同步的,即当服务器接收到客户端请求后,会一直等待 I/O 操作的返回结果,直到返回结果后才会处理下一个请求。这种模型实现简单,但是在处理大量的并发请求时,会出现阻塞,导致性能瓶颈。
相比于IO多路复用,同步阻塞IO需要为每个客户端请求都创建一个线程来处理,线程的创建和销毁等操作会消耗大量的 CPU 时间,因此在处理大量并发请求时性能会有瓶颈。
非阻塞式IO:
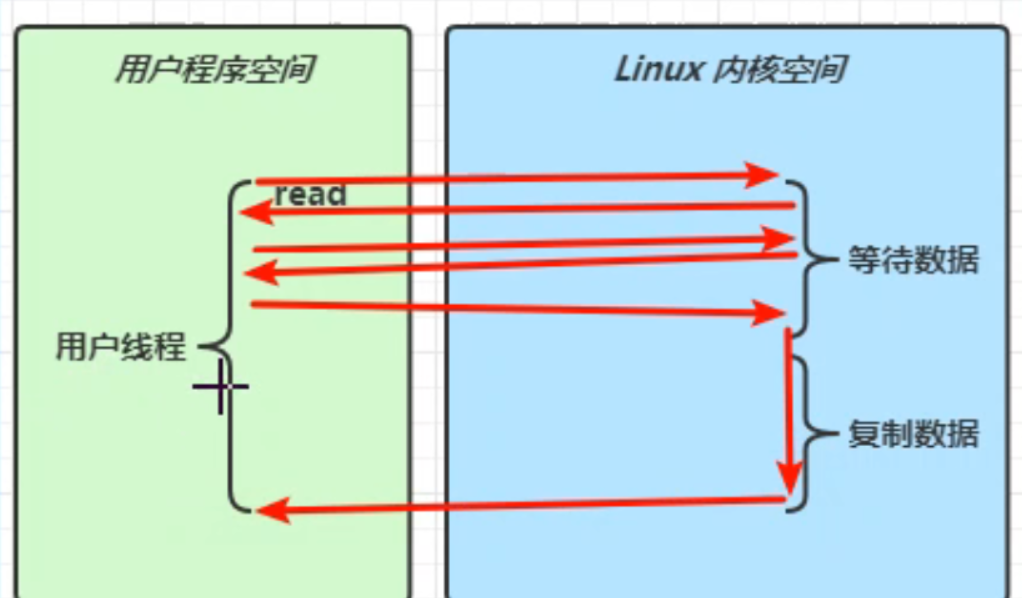
太频繁的调用,浪费大量CPU资源,
IO多路复用:
IO 多路复用模型(I/O Multiplexing Model): Redis 服务器使用一个线程来处理多个客户端的请求,所有的 I/O 操作都是异步的非阻塞的,即当服务器接收到客户端请求后,会注册到一个事件处理器中,
等待轮询 I/O 操作,操作完成后立即返回结果,然后继续处理其它请求。
在 IO 多路复用模型中,Redis 支持以下两种事件处理器:
select:select 是一种比较古老的事件处理器,它可以监听多个 I/O 事件,但是在处理大量事件时,性能会有瓶颈。
epoll:epoll 是一种新的事件处理器,它可以高效地处理大量事件。在使用 epoll 时,Redis 会将所有客户端的 socket 都加入到一个 epoll 实例中,然后通过事件循环机制来监听所有事件的发生。当有事件发生时,epoll 实例会立即通知 Redis 服务器,从而实现快速处理事件的能力。 综上所述,Redis 支持同步阻塞 IO 模型和 IO 多路复用模型。在大量并发请求的场景下,IO 多路复用模型可以提高服务器的并发处理能力。
对于详细理解,可以参考https://www.jianshu.com/p/4609a64fb29a
多个socket连接复用一个线程。这种模式下,内核不会去监视应用程序的连接,而是监视文件描述符。
当客户端发起请求的时候,会生成不同事件类型的套接字。而在服务端,因为使用了 I/O 多路复用技术,所以不是阻塞式的同步执行,而是将消息放入 socket 队列(参考下图的 I/O Multiplexing module),然后通过 File event Dispatcher 将其转发到不同的事件处理器上,如accept、read、send。
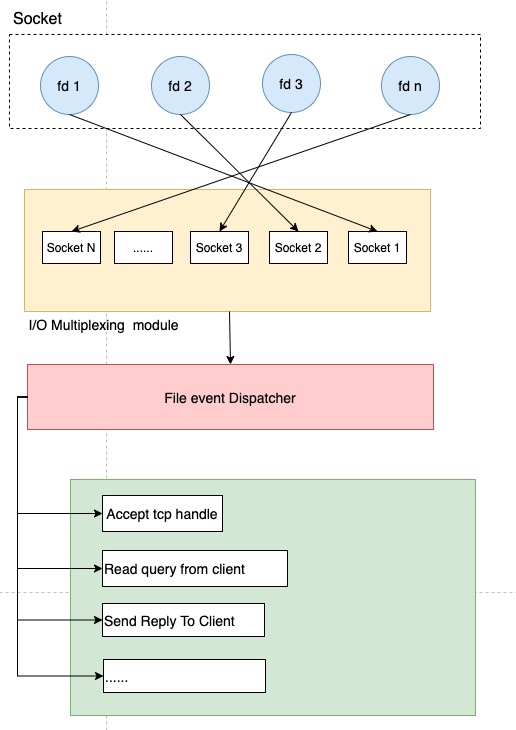
综上,我们得出如下特性:
- 单线程模式,内核持续监听 socket 上的连接及数据请求,一监听就交予Redis线程处理,达到单个线程处理多个I/O 流的效果。
- epoll 提供了基于事件的回调机制。不同事件调用对应的事件处理器。Redis可以持续性的高效处理事件,性能同步提升。
- Redis 不阻塞任一客户端发起的请求,所以可以同时和多个客户端连接并处理请求,具备并发执行的能力。
内存:
Redis的String的实现方式式是什么


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY