

决战圣地玛丽乔亚Day26
写入慢:
1.合并sql来降低日志量,降低日志刷盘的数据量和频率,从而提高效率。
例如: insert into 表 (对应字段) values (插入的行数据);
insert into 表 (对应字段) values (插入的行数据)
-->合并成一个sql:
insert into 表 (对应字段) values (插入的行数据1),(插入的行数据2),(插入的行数据3)
2.在事务中进行插入
start transaction;
insert into 表 (对应字段) values (插入的行数据);
insert into 表 (对应字段) values (插入的行数据)
commit;
通过事务进行插入操作,可以提高效率,因为原来一个insert都要建立一个事务进行插入操作,现在放在一个事务中进行操作。、
3.数据有序进行插入
对插入的顺序的值进行有序的插入,这样的好处是和自增id和随机uuid的区别是相同的。无序会进行更多的随机io,对性能有所消耗。
如果数据量不大可以选择用合并sql+事务的方式,如果数据量大于innodb_buffer的情况下,每次定位索引就会涉及较多的磁盘读写操作,性能下降会快。可以加一个顺序来保证顺序的存数据,减少随机io次数
可以通过max_allowed_packet参数的修改来扩大sql长度的限制。通过innodb_log_buffer_size的参数来修改事务大小的限制,如果事务过大会把innodb的数据刷到磁盘中,效率会下降。
回表相关:
回表这个概念讲的是,通过索引找到了主键,再通过主键找到对应的数据。
索引覆盖:覆盖索引,通过索引可以直接找到对应的数据,这种情况是不需要回表的。在非覆盖索引的情况下,是会回表的。例如,索引失效的情况下,没有完全覆盖索引,会回表。
索引下推:
5.6之后的优化,索引下推减少回表次数,但是扫描的行数是不会变的。
MySQL索引下推可以减少回表次数的原因是,它可以在存储引擎层面上对数据进行过滤,从而只返回满足查询条件的数据行,避免了从磁盘中读取不必要的数据,减少了IO操作,提高了查询效率。
索引下推,在查询请求到达mysql服务器时,根据查询条件生成了执行计划(判断执行计划中是否包含了索引列,如果包含了索引列,mysql会尝试把查询条件放到存储引擎层进行过滤。
存储引擎层过滤完的数据再交给mysql服务器进行剩余的处理,由于存储引擎层面对数据进行了预处理,减少了回表次数)
例如 select * from tab where name like ' %李' and age =22
索引(name,age)
如果不用索引下推,这里是会先找到满足age的数据,由于模糊查询,所以覆盖索引是失效的。找到了符合age条件的结果集后,然后再对age进行过滤
如果使用索引下推,会找到符合name和age的条件,然后返回给mysql进行剩余的groupby,orderby等处理。
B+树性质:
为什么叶子节点要设计成双向链表?
因为需要支持范围查找和排序,正向反向都支持才可以做到正序和倒叙排序,正序和倒序遍历。
为什么会出现索引偶尔命中或偶尔不命中的情况?
1.Mysql版本差异
2.优化器选择了全表而不是索引。
3.硬件问题
4.索引统计信息不准确:索引在MySQL中使用的统计信息(例如索引的区分度和基数)可能不准确,导致MySQL优化器在执行查询计划时做出错误的选择,选择了不使用索引的全表扫描而不是使用索引。
5.数据分布不均匀:当数据表中数据分布不均匀时,可能会导致查询使用索引时效果不佳。例如,在一个数据表中,某些列中的数据分布不均匀,可能导致查询使用索引时只命中部分数据,而不是全部数据。
6.数据量过大:当数据表中数据量过大时,MySQL查询优化器可能会选择全表扫描而不是使用索引,以避免索引的IO操作对性能的影响。
为什么不用跳表?
跳表的结构:
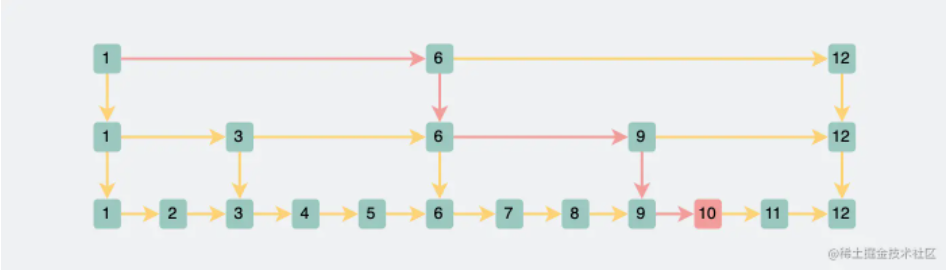
牺牲空间换时间的方式
跳表插入节点时,纯靠随机函数决定是否新增层数做索引。理论上为了达到二分的效果,每一层的结点数需要是下一层结点数的二分之一。
所以二叉树如果想要达到和B+树相同的数据量,需要更多地层数支撑。所以不选跳表,层数高代表IO次数越多。
在写入操作,跳表直接靠随机函数决定是否新增层数,直接写入不需要考虑旋转和平衡的开销,所以写入的性能比B+树好。
既然这么不好,为什么redis用跳表?
因为redis是内存数据库,不存在对磁盘的操作所以,IO的性能消耗不再被考虑,这时候写入的效果明显是跳表更优。而且少了旋转平衡的消耗。
为什么不用红黑树?
红黑树(Red-Black Trees)通过左旋和右旋来调整树高的平衡,并且加入了变色的行为,要求根节点为黑色,其他节点都是红色,也因此得名,通过加入颜色值,作为二叉树平衡度的检查标准,只要插入节点的颜色满足要求,最短树高和最长树高之差不会相差太远。
并且红黑树将树高差限制放宽了,只要最高子树的树高不超过最矮子树的树高的2倍即可,但是!红黑树仍然是二叉树,这一点是没有办法改变的事实,即使再旋转,它仍然是两个分支,比不上B+树多分支的层数更低。
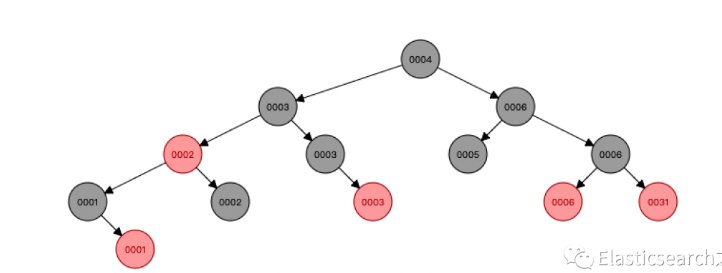
MySQL 的索引依然不采用能够精确定位和范围查询都优秀的红黑树。因为当 MySQL 数据量很大的时候,索引的体积也会很大
,可能内存放不下,所以需要从磁盘上进行相关读写,如果树的层级太高,则读写磁盘的次数(I/O交互)就会越多,性能就会越差。
树高比B+高
哈希索引和B+索引怎么选?
hash表的问题
- 随着数据量的增多,不同key经过哈希计算后结果一样,这种情况叫做hash碰撞。处理hash碰撞的一种方法是链表,但是当数据量比较大时,链表的长度还是会比较大,性能开销就在链表查询上。
- 哈希表是散列存储,因此这种结构适用于只有等值查询的场景,比如 Memcached 及其他一些 NoSQL 引擎。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
2017-03-07 常用类---String类方法.
2017-03-07 常用类---String类前言,