tensorflow2.0——指数衰减学习率、激活函数、损失函数、L2正则化、优化器
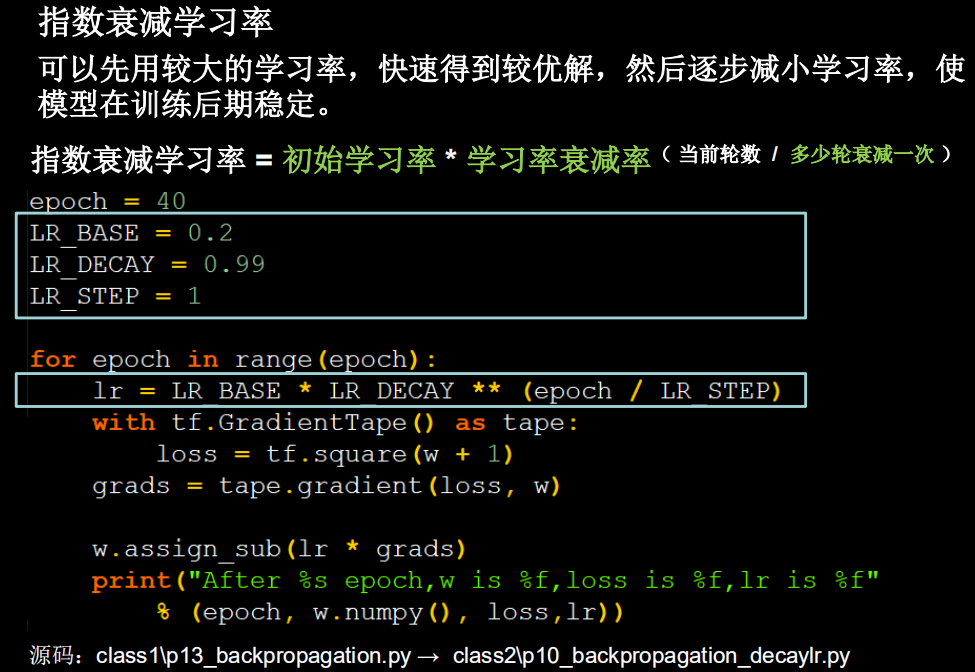
一、指数衰减学习率
为什么使用指数衰减学习率,在进行模型训练时,学习率如果固定不变,可能在接近最小值时,由于学习率过大一直在最小值范围震荡,若学习率逐步减小,开始时可以设置较大学习率,可以先快速拟合最优解,最后使参数的拟合区域稳定。
二、激活函数
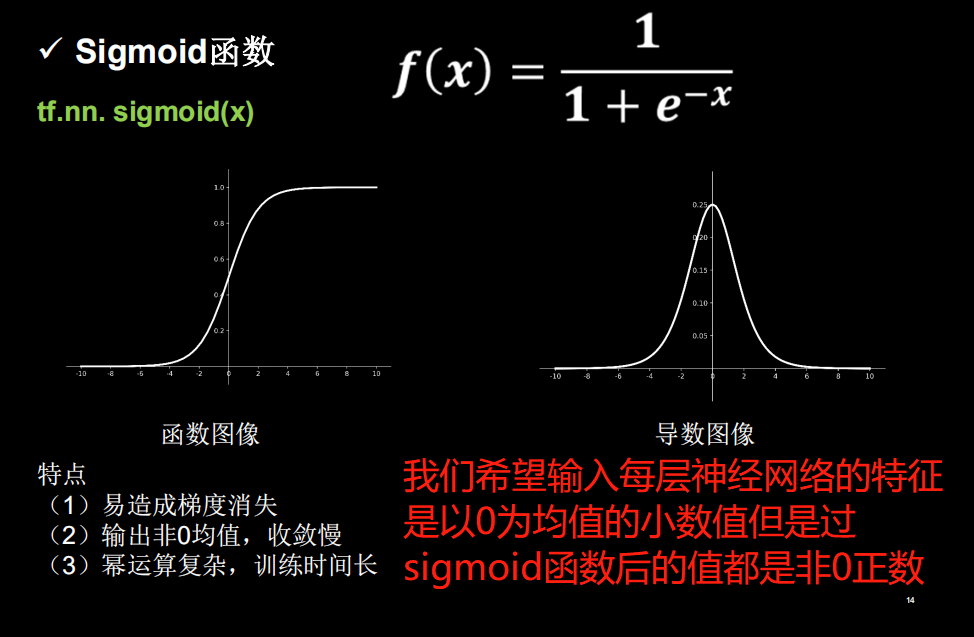
1、sigmod激活函数
- tf.nn.sigmoid()
sigmod激活函数,导数的范围是在0-0.25之间的,当多个0-0.25之前的梯度相乘时,梯度可能趋于0,会导致梯度消失。可作为输出层的激活函数,一般用于二分类。
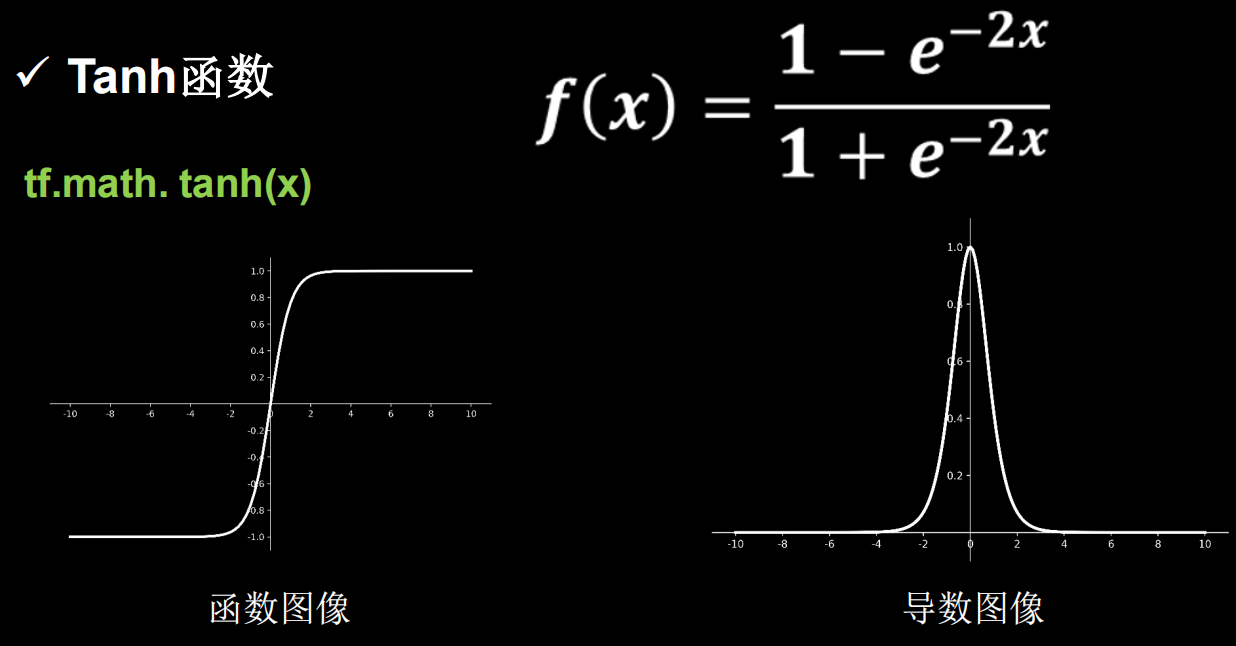
2、tanh函数
- tf.nn.tanh()
tanh函数好处是输出的均值为0,但是同样有梯度消失的可能,且同样涉及幂运算,训练计算比较复杂。
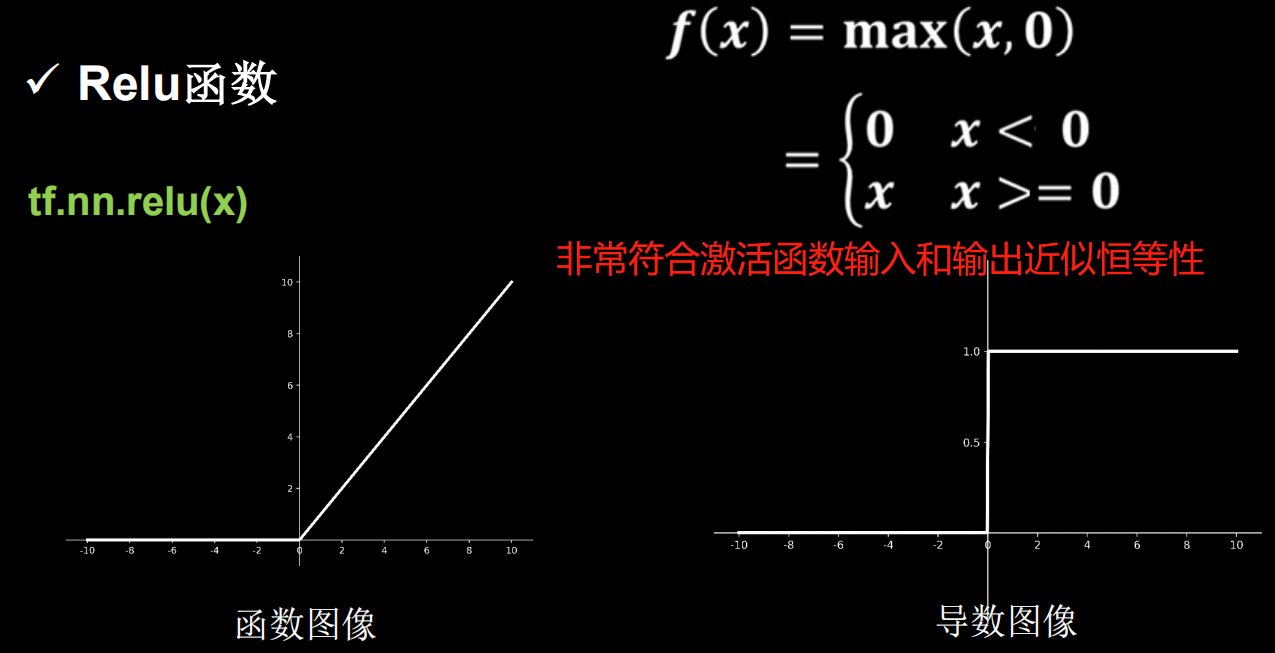
3、Relu函数
-
tf.nn.relu
Relu函数的梯度要么是0要么是1,而对于$f(x)>0$的部分由于梯度为1不会出现梯度消失,而对输出值$f(x)<=0$的部分不会进行参数优化,也就导致可能有的参数无法被更新,造成了Dead Relu。
造成Dead Relu是因为,送入激活函数的输入特征是负数时,激活函数的输出为0,反向传播得到的梯度是0,导致参数无法更新,造成神经元死亡。
可以尝试以下方法避免Dead Relu:
- 较小的学习率
- 输入的X的特征标准化
- 参数W、b初始化设置时,设置均值为0,方差为$\sqrt{\frac{2}{当前输入特征个数}}$

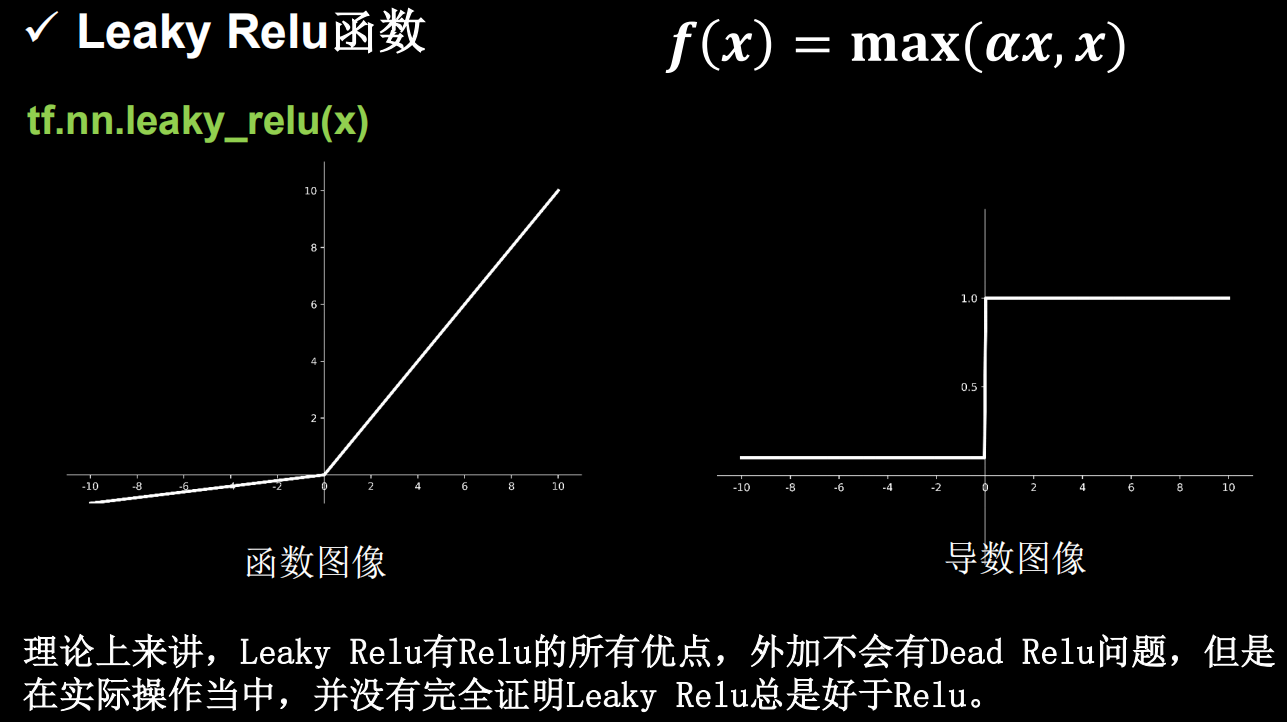
4、leaky relu
这个函数是在relu的基础上,当f(x)<=0时设置一个固定的梯度,来避免某些Dead Relu问题,但实际应用中还是比较多用Relu作为激活函数。
三、损失函数
1、均方误差
- tf.losses.mean_squared_error()
2、交叉熵
- tf.losses.categorical_crossentropy
3、sfotmax与交叉熵结合
-
tf.nn.softmax_cross_entropy_with_logits
这个函数是先将数据y通过softmax函数之后再利用交叉熵计算损失,所以我们当我们用这个函数的时候,激活函数可以不需要设置。
4、损失函数正则化
- tf.nn.l2_loss(W) w为需要正则化的参数3

 浙公网安备 33010602011771号
浙公网安备 33010602011771号