Python爬取《少年的你》豆瓣短评
周末,看到朋友在朋友圈发了一条心情,是关于最新上映的电影《少年的你》,刚好前段时间又学习了一下爬虫,于是心血来潮,想爬一下这部电影的短评,看看口碑如何。此笔记仅用于学习,不得商业获利!如有侵害任何公司利益,请告知删除!
本文记录使用request,以及正则表达式re爬取影评的过程,关于request的安装,可以使用:pip3 install requests
1)登录。注册账号,因为要爬取所有的短评内容的话,必须要登录才可以,这也算是一种反爬虫的手段,注册账号之后,我们首先要解决的就是登录问题。
在获取登录的Url的时候,我们故意输入一个错的账号和密码,就能轻松拿到这个Url以及相应的请求参数了:https://accounts.douban.com/j/mobile/login/basic

拿到这些信息之后,就是发请求,登录了,代码如下:
def login_douban(): try: login_url = 'https://accounts.douban.com/j/mobile/login/basic' headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 6.3; Win64; x64; rv:70.0) Gecko/20100101 Firefox/70.0', 'Referer': 'https://accounts.douban.com/passport/login_popup?login_source=anony' } data = { 'name': '你的用户名', 'password': '你的密码', 'remember': 'false' } response = session.post(login_url, headers=headers, data=data) if response.status_code == 200: return response.text return None except RequestException: print('登录失败') return None
2)爬取。登录成功之后,就可以访问《少年的你》的短评页,https://movie.douban.com/subject/30166972/comments?status=P,然后下拉到最后,通过翻页,我们会看到一个有明显规律的Url:https://movie.douban.com/subject/30166972/comments?start=0&limit=20&sort=new_score&status=P
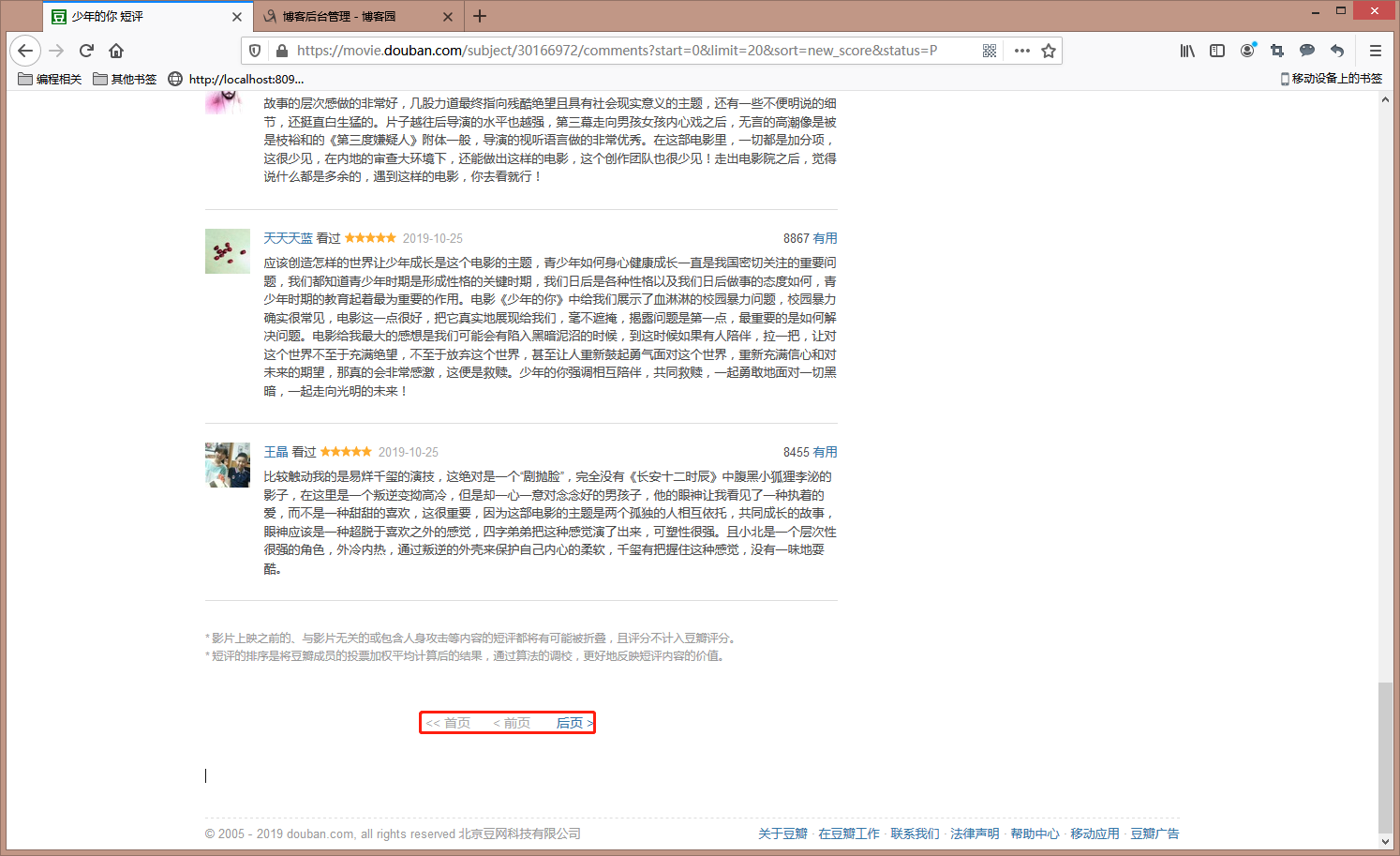
注意里边的参数,start=0&limit=20,意思就是从第0条短评开始,请求20条,也就是第0条~第20条的短评内容,那么就可以定义一个方法,来爬取短评内容,代码如下:着色部分是重点,我们用request.Session()来保存会话状态
session = requests.Session() def get_comment_one_page(page=0): start = int(page * 20) comment_url = 'https://movie.douban.com/subject/30166972/comments?start=%d&limit=20&sort=new_score&status=P' % start headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 6.3; Win64; x64; rv:70.0) Gecko/20100101 Firefox/70.0', } try: response = session.get(comment_url, headers=headers) if response.status_code == 200: return response.text return None except RequestException: print('爬取评论失败') return None
3)解析。第二步爬取到html代码之后,我们需要解析出来里边的内容,将评论的数据提取出来。

通过对网页的分析,我们可以看到每一条评论,都是用一个class="comment-item"的div包裹着,那么我们就可以将这个div中需要的内容通过正则表达式提取出来:.*?表示匹配任意字符,需要提取的内容需要加(),着色部分就是我们需要提取的内容
'<div class="comment-item".*?comment-info">.*?rating".*?title="(.*?)">.*?"comment-time.*?title="(.*?)">.*?short">(.*?)</span>.*?</div>'
<div class="comment-item" data-cid="2012951340"> <div class="avatar"> <a title="天天天蓝" href="https://www.douban.com/people/182748049/"> <img src="https://img3.doubanio.com/icon/u182748049-1.jpg" class=""> </a> </div> <div class="comment"> <h3> <span class="comment-vote"> <span class="votes">8867</span> <input value="2012951340" type="hidden"> <a href="javascript:;" class="j a_show_login" onclick="">有用</a> </span> <span class="comment-info"> <a href="https://www.douban.com/people/182748049/" class="">天天天蓝</a> <span>看过</span> <span class="allstar50 rating" title="力荐"></span> <span class="comment-time " title="2019-10-25 09:34:22"> 2019-10-25 </span> </span> </h3> <p class=""> <span class="short">应该创造怎样的世界让少年成长是这个电影的主题...</span> </p> </div> </div>
提取内容的方法如下:
def parse_comment_one_page(html): pattern = re.compile( '<div class="comment-item".*?comment-info">.*?rating".*?title="(.*?)">.*?"comment-time.*?title="(.*?)">.*?short">(.*?)</span>.*?</div>', re.S) items = re.findall(pattern, html) for item in items: yield{ 'star': item[0], 'time': item[1], 'context': item[2] }
4)爬取所有页。这一步其实很难,因为你会发现你的账号马上就会被封了..哈哈,要解决这个问题,就要用到动态代理了,好吧!我还没来得及补习....
def get_comment_all_page(): page = 0 html = get_comment_one_page(page) condition = html is not None while condition: for item in parse_comment_one_page(html): print(item) write_to_file(item) #save_data_base(parse_comment_one_page(html)) page += 1 html = get_comment_one_page(page) time.sleep(random.random() * 3) print('爬取完毕')
爬取到内容之后,我们可以将内容写到文件中,也可以写入数据库:
def write_to_file(comments): with open(COMMENTS_FILE_PATH, 'a', encoding='utf-8') as f: f.write(json.dumps(comments, ensure_ascii=False)+'\n') f.close() def save_data_base(items): list = [] for item in items: jsonstr = json.dumps(item, ensure_ascii=False) context = json.loads(jsonstr) tup = (context['star'], context['time'], context['context']) list.append(tup) connection = pymysql.connect( host='127.0.0.1', port=10080, user='test', password='123456', db='webspider') cursor = connection.cursor() cmd = "insert into shaoniandeni (star,time,context) values (%s,%s,%s)" try: cursor.executemany(cmd, list) connection.commit() except: connection.rollback() traceback.print_exc() finally: cursor.close() connection.close()
5)分析。因为我没有爬取完,所以分析的结果是不准确的,但是呢?也能反映出来一部分问题。通过mysql中的数据分类可以看到结果如下:
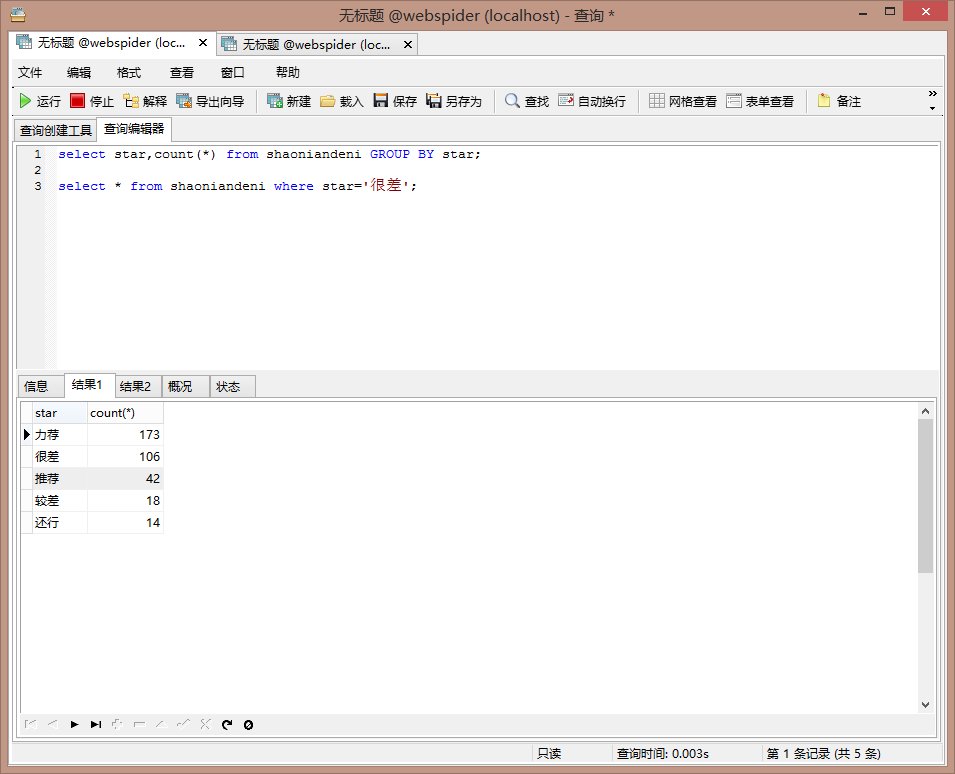
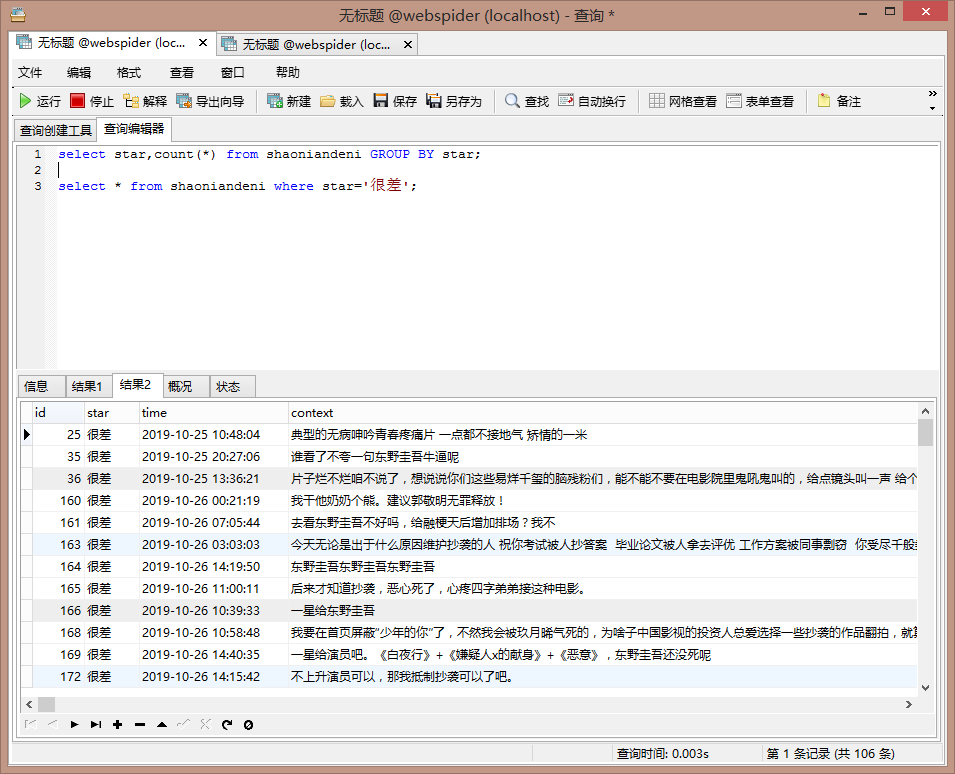
出于好奇,我很关心评分给很差的同学都写了什么,于是我又看了一下,评分为很差的内容:
6)生成词云。生成词云的时候,我过滤了一部分词,详情直接查看完整的源代码。

7)源代码。


import os import re import json import time import jieba import random import requests import traceback import pymysql import numpy as np import pymysql.cursors from PIL import Image from wordcloud import WordCloud import matplotlib.pyplot as plt from requests.exceptions import RequestException COMMENTS_FILE_PATH = 'douban_comments.txt' # 词云字体 WC_FONT_PATH = 'C:\\Windows\\fonts\\STFANGSO.TTF' # 词云形状图片 WC_MASK_IMG = 'index.jpg' session = requests.Session() def login_douban(): try: login_url = 'https://accounts.douban.com/j/mobile/login/basic' headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 6.3; Win64; x64; rv:70.0) Gecko/20100101 Firefox/70.0', 'Referer': 'https://accounts.douban.com/passport/login_popup?login_source=anony' } data = { 'name': '', 'password': '', 'remember': 'false' } response = session.post(login_url, headers=headers, data=data) if response.status_code == 200: return response.text return None except RequestException: print('登录失败') return None def get_comment_one_page(page=0): start = int(page * 20) comment_url = 'https://movie.douban.com/subject/30166972/comments?start=%d&limit=20&sort=new_score&status=P' % start headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 6.3; Win64; x64; rv:70.0) Gecko/20100101 Firefox/70.0', } try: response = session.get(comment_url, headers=headers) if response.status_code == 200: return response.text return None except RequestException: print('爬取评论失败') return None def parse_comment_one_page(html): pattern = re.compile( '<div class="comment-item".*?comment-info">.*?rating".*?title="(.*?)">.*?"comment-time.*?title="(.*?)">.*?short">(.*?)</span>.*?</div>', re.S) items = re.findall(pattern, html) for item in items: yield{ 'star': item[0], 'time': item[1], 'context': item[2] } def write_to_file(comments): with open(COMMENTS_FILE_PATH, 'a', encoding='utf-8') as f: f.write(json.dumps(comments, ensure_ascii=False)+'\n') f.close() def get_comment_all_page(): page = 0 html = get_comment_one_page(page) condition = html is not None while condition: for item in parse_comment_one_page(html): print(item) write_to_file(item) #save_data_base(parse_comment_one_page(html)) page += 1 html = get_comment_one_page(page) time.sleep(random.random() * 3) print('爬取完毕') def save_data_base(items): list = [] for item in items: jsonstr = json.dumps(item, ensure_ascii=False) context = json.loads(jsonstr) tup = (context['star'], context['time'], context['context']) list.append(tup) connection = pymysql.connect( host='127.0.0.1', port=10080, user='test', password='123456', db='webspider') cursor = connection.cursor() cmd = "insert into shaoniandeni (star,time,context) values (%s,%s,%s)" try: cursor.executemany(cmd, list) connection.commit() except: connection.rollback() traceback.print_exc() finally: cursor.close() connection.close() def cut_word(): """ 对数据分词 :return: 分词后的数据 """ with open(COMMENTS_FILE_PATH, "r", encoding="utf-8") as file: comment_txt = file.read() jieba.add_word('周冬雨') jieba.add_word('易烊千玺') jieba.add_word('白夜行') jieba.add_word('东野圭吾') wordlist = jieba.cut(comment_txt, cut_all=True) wl = " ".join(wordlist) #print(wl) return wl def create_word_cloud(): """ 生成词云 :return: """ # 设置词云形状图片 wc_mask = np.array(Image.open(WC_MASK_IMG)) # 数据清洗词列表 stop_words = ['就是', '不是', '但是', '还是','这种', '只是', '这样', '这个', '一个', '什么', '电影', '没有', '真的','周冬雨','易烊千玺','冬雨','千玺','我们','他们','少年'] # 设置词云的一些配置,如:字体,背景色,词云形状,大小 wc = WordCloud(background_color="white", max_words=50, mask=wc_mask, scale=4, max_font_size=50, random_state=42, stopwords=stop_words, font_path=WC_FONT_PATH) # 生成词云 wc.generate(cut_word()) # 在只设置mask的情况下,你将会得到一个拥有图片形状的词云 plt.imshow(wc, interpolation="bilinear") plt.axis("off") plt.figure() plt.show() def main(): #login_douban() #get_comment_all_page() create_word_cloud() if __name__ == '__main__': main()
8)爬虫相关类库:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号