Java 线程池的使用详解
1、 线程池是什么?
线程池(Thread Pool)是一种基于池化思想管理线程的工具,经常出现在多线程服 务器中,如 MySQL。 线程过多会带来额外的开销,其中包括创建销毁线程的开销、调度线程的开销等等, 同时也降低了计算机的整体性能。线程池维护多个线程,等待监督管理者分配可并发 执行的任务。这种做法,一方面避免了处理任务时创建销毁线程开销的代价,另一方 面避免了线程数量膨胀导致的过分调度问题,保证了对内核的充分利用。之前我们在使用多线程都是用 Thread 的 start() 来创建启动一个线程,但是在实际开发中,如果每个请求到达就创建一个新线程,开销是相当大的。服务器在创建和销毁线程上花费的时间和消耗的系统资源都相当大,甚至可能要比在处理实际的用请求的时间和资源要多的多。除了创建和销毁线程的开销之外,活动的线程也需要消耗系统资源。如果在一个jvm里创建太多的线程,可能会使系统由于过度消耗内存或“切换过度”而导致系统资源不足。这就引入了线程池概念。
- 降低资源消耗:通过池化技术重复利用已创建的线程,降低线程创建和销毁造 成的损耗。
- 提高响应速度:任务到达时,无需等待线程创建即可立即执行。
- 提高线程的可管理性:线程是稀缺资源,如果无限制创建,不仅会消耗系统资 源,还会因为线程的不合理分布导致资源调度失衡,降低系统的稳定性。使用 线程池可以进行统一的分配、调优和监控。
- 提供更多更强大的功能:线程池具备可拓展性,允许开发人员向其中增加更多 的功能。比如延时定时线程池 ScheduledThreadPoolExecutor,就允许任 务延期执行或定期执行。
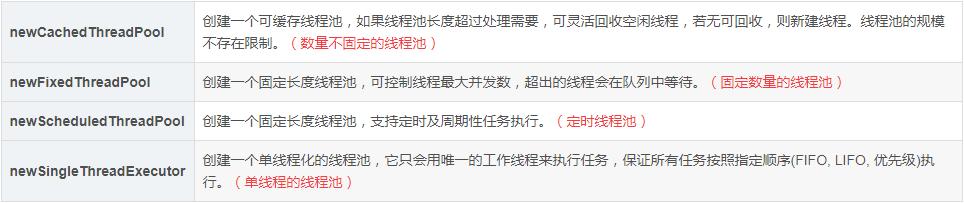
2、Executors 线程池工具提供四种线程池在(不建议使用)
3、Java 中的线程池核心实现类是 ThreadPoolExecutor
在《阿里巴巴java开发手册》中指出了线程资源必须通过线程池提供,不允许在应用中自行显示的创建线程,这样一方面是线程的创建更加规范,可以合理控制开辟线程的数量;另一方面线程的细节管理交给线程池处理,优化了资源的开销。而线程池不允许使用Executors去创建,而要通过ThreadPoolExecutor方式,这一方面是由于jdk中Executor框架虽然提供了如newFixedThreadPool()、newSingleThreadExecutor()、newCachedThreadPool()等创建线程池的方法,但都有其局限性,不够灵活;另外由于前面几种方法内部也是通过ThreadPoolExecutor方式实现,使用ThreadPoolExecutor有助于大家明确线程池的运行规则,创建符合自己的业务场景需要的线程池,避免资源耗尽的风险。
ThreadPoolExecutor 的继承关系:
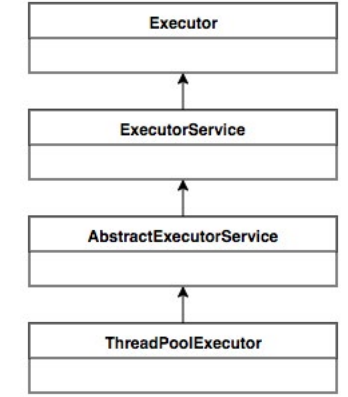
ThreadPoolExecutor 实 现 的 顶 层 接 口 是 Executor, 顶 层 接 口 Executor 提 供 了一种思想:将任务提交和任务执行进行解耦。用户无需关注如何创建线程,如 何调度线程来执行任务,用户只需提供 Runnable 对象,将任务的运行逻辑提交 到执行器 (Executor) 中,由 Executor 框架完成线程的调配和任务的执行部分。 ExecutorService 接口增加了一些能力:(1)扩充执行任务的能力,补充可以为一 个或一批异步任务生成 Future 的方法;(2)提供了管控线程池的方法,比如停止线 程池的运行。AbstractExecutorService 则是上层的抽象类,将执行任务的流程 串联了起来,保证下层的实现只需关注一个执行任务的方法即可。最下层的实现类 ThreadPoolExecutor 实现最复杂的运行部分,ThreadPoolExecutor 将会一方面 维护自身的生命周期,另一方面同时管理线程和任务,使两者良好的结合从而执行并 行任务。
ThreadPoolExecutor 是如何运行,如何同时维护线程和执行任务的呢?其运行机制 如下图所示:
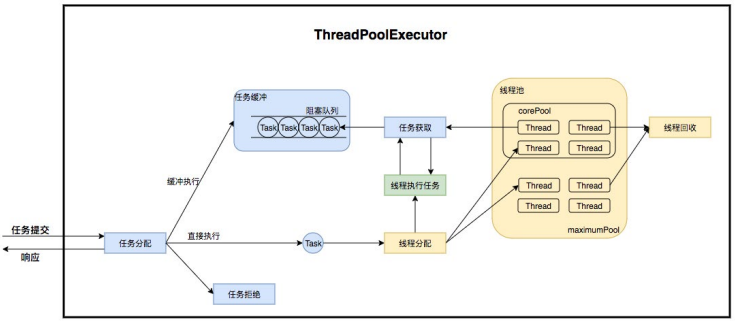
线程池在内部实际上构建了一个生产者消费者模型,将线程和任务两者解耦,并不 直接关联,从而良好的缓冲任务,复用线程。线程池的运行主要分成两部分:任务管 理、线程管理。任务管理部分充当生产者的角色,当任务提交后,线程池会判断该任 务后续的流转:(1)直接申请线程执行该任务;(2)缓冲到队列中等待线程执行;(3) 拒绝该任务。线程管理部分是消费者,它们被统一维护在线程池内,根据任务请求进 行线程的分配,当线程执行完任务后则会继续获取新的任务去执行,最终当线程获取 不到任务的时候,线程就会被回收。
ThreadPoolExecutor 的运行状态有 5 种,分别为:

ThreadPoolExcutor构造函数的定义:
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler) ;
- corePoolSize
一般线程池开始时是没有线程的,只有当任务来了并且线程数量小于corePoolSize才会创建线程。
1.核心线程会一直存活,即使没有任务需要执行。
2.当线程数小于核心线程数时,即使有线程空闲,线程池也会优先创建新线程处理。
3.设置 allowCoreThreadTimeout=true(默认false)时,核心线程会超时关闭。
- maximumPoolSize
线程池中允许的最大线程数,线程池中的当前线程数目不会超过该值。如果队列中任务已满,并且当前线程个数小于maximumPoolSize,那么会创建新的线程来执行任务。这里值得一提的是largestPoolSize,该变量记录了线程池在整个生命周期中曾经出现的最大线程个数。为什么说是曾经呢?因为线程池创建之后,可以调用setMaximumPoolSize()改变运行的最大线程的数目。
1.当线程数>=corePoolSize,且任务队列已满时。线程池会创建新线程来处理任务
2.当线程数=maxPoolSize,且任务队列已满时,线程池会拒绝处理任务而抛出异常
- keepAliveTime
在线程数量超过corePoolSize后,多余空闲线程的最大存活时间。
1.当线程空闲时间达到keepAliveTime时,线程会退出,直到线程数量=corePoolSize
2.如果allowCoreThreadTimeout=true,则会直到线程数量=0
- unit:keepAliveTime的时间单位。
- workQueue: 存放来不及处理的任务的队列,是一个BlockingQueue。
- threadFactory: 生产线程的工厂类,可以定义线程名,优先级等。
- handler: 拒绝策略,当任务来不及处理的时候,如何处理。
任务执行机制
任务调度
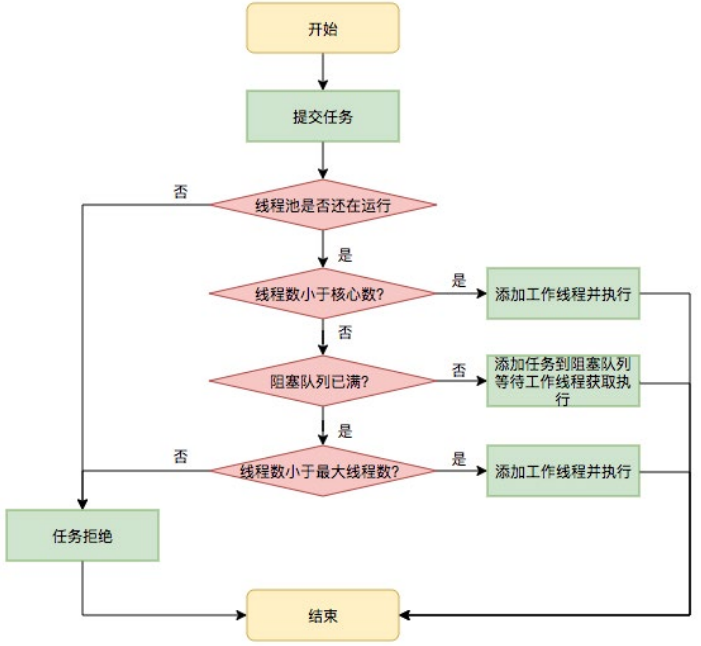
任务调度是线程池的主要入口,当用户提交了一个任务,接下来这个任务将如何执行 都是由这个阶段决定的。了解这部分就相当于了解了线程池的核心运行机制。 首先,所有任务的调度都是由 execute 方法完成的,这部分完成的工作是:检查现在 线程池的运行状态、运行线程数、运行策略,决定接下来执行的流程,是直接申请线 程执行,或是缓冲到队列中执行,亦或是直接拒绝该任务。其执行过程如下:
- 1. 首先检测线程池运行状态,如果不是 RUNNING,则直接拒绝,线程池要保 证在 RUNNING 的状态下执行任务。
- 2. 如果 workerCount < corePoolSize,则创建并启动一个线程来执行新提 交的任务。
- 3. 如果 workerCount >= corePoolSize,且线程池内的阻塞队列未满,则将任 务添加到该阻塞队列中。
- 4. 如 果 workerCount >= corePoolSize && workerCount < maximumPoolSize,且线程池内的阻塞队列已满,则创建并启动一个线程来执行新提 交的任务。
- 5. 如果 workerCount >= maximumPoolSize,并且线程池内的阻塞队列已满 , 则根据拒绝策略来处理该任务 , 默认的处理方式是直接抛异常。
其执行流程如下图所示:
任务缓冲
任务缓冲模块是线程池能够管理任务的核心部分。线程池的本质是对任务和线程的管 理,而做到这一点最关键的思想就是将任务和线程两者解耦,不让两者直接关联,才 可以做后续的分配工作。线程池中是以生产者消费者模式,通过一个阻塞队列来实现 的。阻塞队列缓存任务,工作线程从阻塞队列中获取任务。 阻塞队列 (BlockingQueue) 是一个支持两个附加操作的队列。这两个附加的操作是: 在队列为空时,获取元素的线程会等待队列变为非空。当队列满时,存储元素的线程 会等待队列可用。阻塞队列常用于生产者和消费者的场景,生产者是往队列里添加元 素的线程,消费者是从队列里拿元素的线程。阻塞队列就是生产者存放元素的容器,而消费者也只从容器里拿元素。下图中展示了线程 1 往阻塞队列中添加元素,而线程 2 从阻塞队列中移除元素:
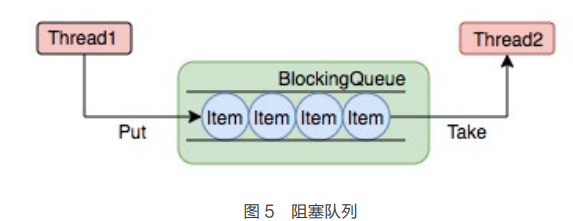
使用不同的队列可以实现不一样的任务存取策略。在这里,我们可以再介绍下阻塞队 列的成员:

任务拒绝
任务拒绝模块是线程池的保护部分,线程池有一个最大的容量,当线程池的任务缓存 队列已满,并且线程池中的线程数目达到 maximumPoolSize 时,就需要拒绝掉该任务,采取任务拒绝策略,保护线程池。 拒绝策略是一个接口,其设计如下:
public interface RejectedExecutionHandler {
void rejectedExecution(Runnable r, ThreadPoolExecutor executor);
}
用户可以通过实现这个接口去定制拒绝策略,也可以选择 JDK 提供的四种已有拒绝 策略,其特点如下:
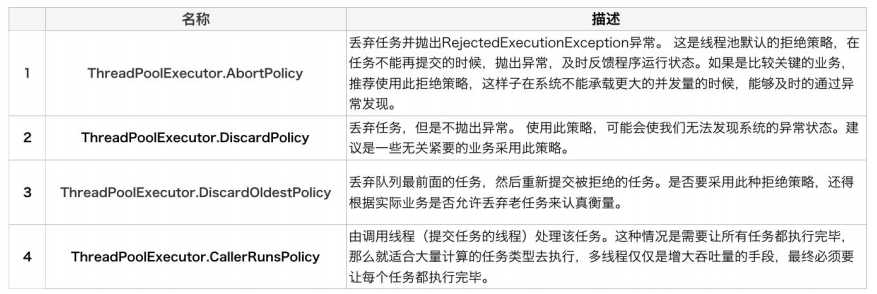
注意:ThreadPoolExecutor相当于是非公平的,比如队列满了之后提交的Runnable可能会比正在排队的Runnable先执行。
4、线程池参数的合理设置
CPU密集型任务
场景:加密解密、压缩解压、数据计算等
// 最佳线程数 = CPU核心数 + 1
int corePoolSize = Runtime.getRuntime().availableProcessors() + 1;
int maximumPoolSize = corePoolSize; // 一般等于核心线程数
BlockingQueue<Runnable> queue = new LinkedBlockingQueue<>(); // 无界队列
IO密集型任务
场景:数据库查询、文件读写、网络请求、RPC调用等
// 最佳线程数 ≈ CPU核心数 * (1 + IO等待时间/CPU计算时间)
// 经验公式:CPU核心数 * 2 到 CPU核心数 * 4
int cpuCores = Runtime.getRuntime().availableProcessors();
int corePoolSize = cpuCores * 2;
int maximumPoolSize = cpuCores * 4;
BlockingQueue<Runnable> queue = new LinkedBlockingQueue<>(100); // 有界队列
混合型任务(既有计算又有IO)
// 根据业务比例调整
int cpuCores = Runtime.getRuntime().availableProcessors();
int corePoolSize = cpuCores * 3 / 2;
int maximumPoolSize = cpuCores * 2;
BlockingQueue<Runnable> queue = new ArrayBlockingQueue<>(200);
5、全局线程池
public class GlobalThreadPool {
/**
* 核心线程大小
* 程序每秒需要处理的最大任务数量(10) * 单线程处理一个任务所需要的时间(1s)
*/
private static final Integer CORE_POOL_SIZE = 10;
/**
* 最大线程大小
*/
private static final Integer MAXIMUM_POOL_SIZE = 20;
/**
* 检测空闲线程的时间周期
*/
private static final Long KEEP_ALIVE_TIME = 20L;
/**
* 阻塞队列大小
* (corePoolSize/taskTime) * responseTime
*/
private static final Integer BLOCK_QUEUE_SIZE = 2000;
private static final ThreadPoolExecutor tpe = new ThreadPoolExecutor(
CORE_POOL_SIZE,
MAXIMUM_POOL_SIZE,
KEEP_ALIVE_TIME,
TimeUnit.SECONDS,
new LinkedBlockingQueue<>(BLOCK_QUEUE_SIZE));
public static Future submitTask(Callable task){
return tpe.submit(task);
}
public static ThreadPoolExecutor getExecutor() {
return tpe;
}
}
6、创建任务:
任务分为两种:一种是有返回值的( callable ),一种是没有返回值的( runnable ). Callable与 Future 两功能是Java在后续版本中为了适应多并法才加入的,Callable是类似于Runnable的接口,实现Callable接口的类和实现Runnable的类都是可被其他线程执行的任务。
- 无返回值的任务就是一个实现了runnable接口的类.使用run方法.
- 有返回值的任务是一个实现了callable接口的类.使用call方法.
Callable和Runnable的区别如下:
- Callable定义的方法是call,而Runnable定义的方法是run。
- Callable的call方法可以有返回值,而Runnable的run方法不能有返回值。
- Callable的call方法可抛出异常,而Runnable的run方法不能抛出异常。
7、执行任务
通过java.util.concurrent.ExecutorService接口对象来执行任务,该对象有两个方法可以执行任务execute和submit。execute这种方式提交没有返回值,也就不能判断是否执行成功。submit这种方式它会返回一个Future对象,通过future的get方法来获取返回值,get方法会阻塞住直到任务完成。
execute与submit区别:
- 接收的参数不一样
- submit有返回值,而execute没有
- submit方便Exception处理
- execute是Executor接口中唯一定义的方法;submit是ExecutorService(该接口继承Executor)中定义的方法
8、使用线程池
(1)调用Runnablepool.execute(new Runnable() {
@Override
public void run() {
// 输出内容:MyThreadFactory_testThread_0
System.out.println(Thread.currentThread().getName());
}
});
Future<String> future = pool.submit(new Callable<String>() { @Override public String call() throws Exception { return Thread.currentThread().getName(); } });
9、Spring 提供的线程池:ThreadPoolTaskExecutor
/**
* @Author dw
* @ClassName GlobalThreadPool
* @Description 全局线程池配置
* @Date 2022/5/26 15:08
* @Version 1.0
*/
@Configuration
public class GlobalThreadPool {
private static final Logger logger = LoggerFactory.getLogger(GlobalThreadPool.class);
private static final Integer CORE_POOL_SIZE = 5;
private static final Integer QUEUE_SIZE = 10;
@Bean
public ThreadPoolTaskExecutor threadPoolTaskExecutor() {
ThreadPoolTaskExecutor threadPoolExecutor = new ThreadPoolTaskExecutor();
// 1、cpu密集型 cpu+1; 2、IO密集型 cpu*2 + 1
int maxPoolSize = Runtime.getRuntime().availableProcessors() * 2;
logger.info("ThreadPoolTaskExecutor-CORE_POOL_SIZE: {}", CORE_POOL_SIZE);
logger.info("ThreadPoolTaskExecutor-MAX_POOL_SIZE: {}", maxPoolSize);
threadPoolExecutor.setCorePoolSize(CORE_POOL_SIZE);
threadPoolExecutor.setMaxPoolSize(maxPoolSize);
threadPoolExecutor.setQueueCapacity(QUEUE_SIZE);
threadPoolExecutor.setKeepAliveSeconds(60);
threadPoolExecutor.setThreadNamePrefix("executor-custom-");
threadPoolExecutor.setAllowCoreThreadTimeOut(false);
threadPoolExecutor.setRejectedExecutionHandler(new ThreadPoolExecutor.AbortPolicy());
return threadPoolExecutor;
}
}
10、线程池参数动态配置
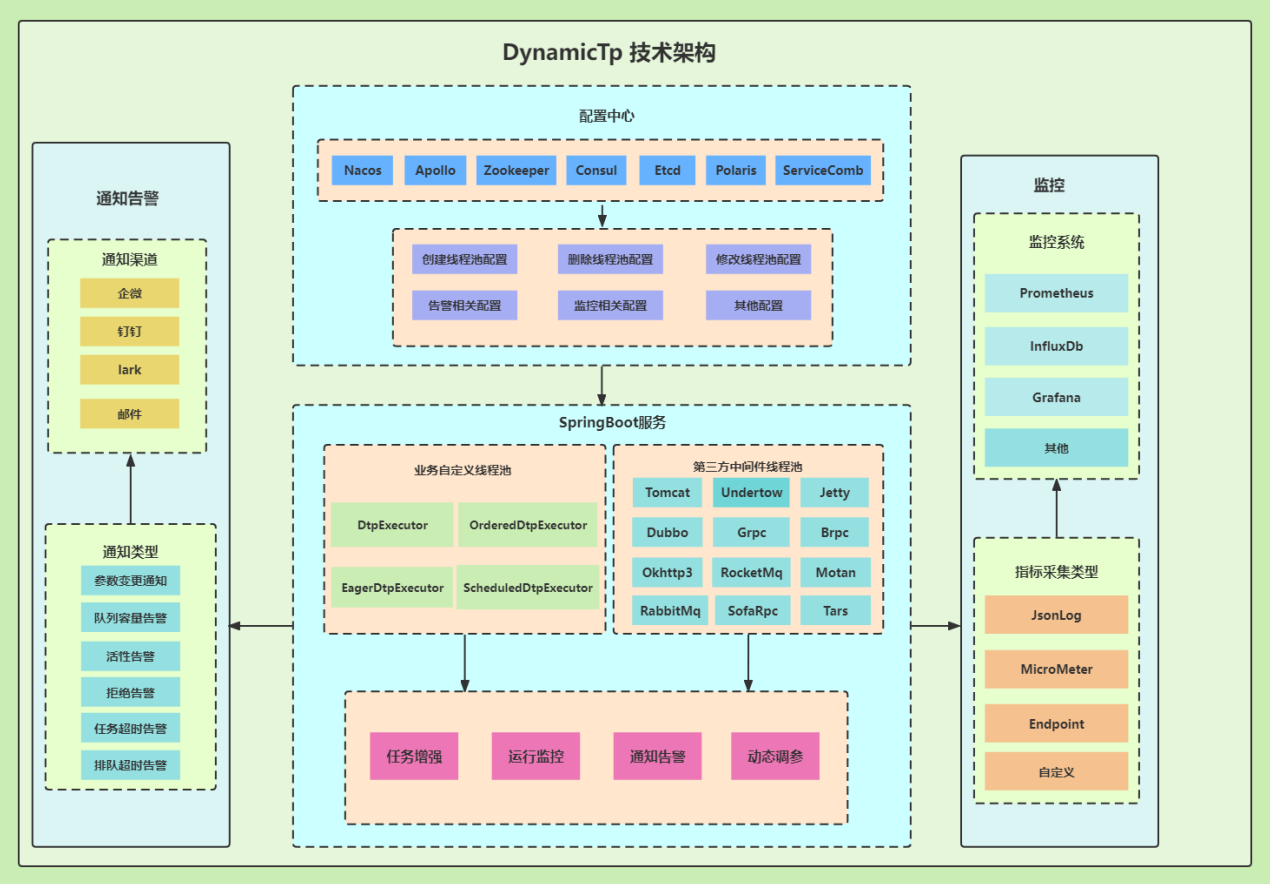
DynamicTp 是一个基于配置中心实现的轻量级动态线程池管理工具,主要功能可以总结为动态调参、 通知报警、运行监控、三方包线程池管理等几大类。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号