MySQL缓存
MySQL缓存
一、前言
在当今的各种系统中,缓存是对系统性能优化的重要手段。MySQL Query Cache(MySQL查询缓存)在MySQL Server中是默认打开的,但是网上各种资料以及有经验的DBA都建议生产环境中把MySQL Query Cache关闭。按道理,MySQL Server默认打开,是鼓励用户使用缓存,但是大拿们却建议关闭此功能,并且国内各个云厂商提供的MySQL云服务中默认都是关闭这个功能,这是为什么?他们在使用中遇到了什么坑?本文将会从以下几方面来详解MySQL Query Cache。
二、 MySQL查询缓存简介
MySQL查询缓存是MySQL中比较独特的一个缓存区域,用来缓存特定Query的整个结果集信息,且共享给所有客户端。为了提高完全相同的Query语句的响应速度,MySQL Server会对查询语句进行Hash计算后,把得到的hash值与Query查询的结果集对应存放在Query Cache中。当MySQL Server打开Query Cache之后,MySQL Server会对接收到的每一个SELECT 语句通过特定的Hash算法计算该Query的Hash值,然后通过该hashi值到Query Cache中去匹配。
- 如果没有匹配,将这个hash值存放在一个hash链表中,并将Query的结果集存放到cache中,存放hashi值链表的每个hash节点存放了相应Quey结果集在cache中的地址,以及该query所涉及到一些table相关信息;
- 如果通过hash值匹配到了一样的Query,则直接将cache中相应的Query结果集返回给客户端。
目前MySQL Query Cache只会cache select语句,其他类似show ,use的语句不会被cache MySQL 的每个Query Cache都是以SQL文本作为key来存储的,在应用Query Cache之前,SQL文本不会做任何处理。也就是说,两个SQL语句,只要相差哪怕一个字符(例如大小写不一样,多一个空格,多注释),那么这两个SQL将使用不同的Cache地址。如: 下面三条SQL将会被存储在三个不同的缓存里,虽然他们的结果都是一样的。
select * FROM people where name='surfchen';
select * FROM people where /*hey~*/ name='surfchen';
SELECT * FROM people where name='surfchen';
三、MySQL缓存机制
MySQL缓存机制简单的说就是缓存sql文本及查询结果,如果运行相同的SQL,服务器直接从缓存中取到结果,而不需要再去解析和执行SQL。如果表更改了,那么使用这个表的所有缓存查询将不再有效,查询缓存中值相关条目被清空。这里的更改指的是表中任何数据或是结构发生改变,包括INSERT、UPDATE、 DELETE、TRUNCATE、ALTER TABLE、DROP TABLE或DROP DATABASE等,也包括那些映射到改变了的表使用MERGE表的查询。显然,这对于频繁更新的表,查询缓存是不适合的,而对于一些不常改变数据且有大量相同SQL查询的表,查询缓存会节约很大的性能。
查询必须是完全相同(逐字节相同)才能够被认为是相同的。另外,同样的查询字符串由于其它原因可能认为是不同的。使用不同的数据库、不同的协议版本或者不同 默认字符集的查询被认为是不同的查询并且分别进行缓存。
需要注意的是MySQL Query Cache 是对大小写敏感的,因为Query Cache 在内存中是以 HASH 结构来进行映射,HASH 算法基础就是组成 SQL 语句的字符,所以 任何SQL语句的改变重新cache.
- 开启了缓存,MySQL Server会自动将查询语句和结果集返回到内存,下次再查直接从内存中取;
- 缓存的结果是通过sessions共享的,所以一个client查询的缓存结果,另一个client也可以使用
- MySQL Query Cache内容为 select 的结果集, cache 使用完整的SQL字符串做 key, 并区分大小写,空格等。即两个SQL必须完全一致才会导致cache命中。即检查查询缓存时,MySQL Server不会对SQL做任何处理,它精确的使用客户端传来的查询,只要字符大小写或注释有点不同,查询缓存就认为是不同的查询;
- prepared statement永远不会cache到结果,即使参数完全一样。在 5.1 之后会得到改善。
- where条件中如包含任何一个不确定的函数将永远不会被cache, 比如current_date, now等。
- date 之类的函数如果返回是以小时或天级别的,最好先算出来再传进去。
-
select * from foo where date1=current_date -- 不会被 cache
-
select * from foo where date1='2008-12-30' -- 被cache, 正确的做法
- 太大的result set不会被cache (< query_cache_limit)
- MySQL缓存在分库分表环境下是不起作用的
- 执行SQL里有触发器,自定义函数时,MySQL缓存也是不起作用的
- 在表的结构或数据发生改变时,查询缓存中的数据不再有效。如INSERT、UPDATE、 DELETE、TRUNCATE、ALTER TABLE、DROP TABLE或DROP DATABASE会导致缓存数据失效。所以查询缓存适合有大量相同查询的应用,不适合有大量数据更新的应用。
- 一旦表数据进行任何一行的修改,基于该表相关cache立即全部失效。
- FLUSH QUERY CACHE; #清理查询缓存内存碎片
- RESET QUERY CACHE;#从查询缓存中移除所有查询
- FLUSH TABLES; #关闭所有打开的表,同时该操作会清空查询缓存中的内容
当服务器启动的时候,会初始化缓存需要的内存,是一个完整的空闲块。当查询结果需要缓存的时候,先从空闲块中申请一个数据块为参数query_cache_min_res_unit配置的空间,即使缓存数据很小,申请数据块也是这个,因为查询开始返回结果的时候就分配空间,此时无法预知结果多大。
分配内存块需要先锁住空间块,所以操作很慢,MySQL会尽量避免这个操作,选择尽可能小的内存块,如果不够,继续申请,如果存储完时有空余则释放多余的。
但是如果并发的操作,余下的需要回收的空间很小,小于query_cache_min_res_unit,不能再次被使用,就会产生碎片。如图: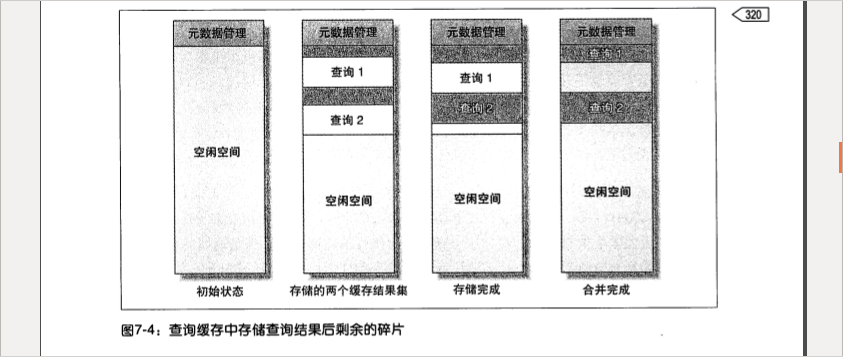
四、MySQL缓存发挥作用的情况
1、查询缓存可以降低查询执行的时间,但是却不能减少查询结果传输的网络消耗,如果网络传输消耗是整个查询过程的主要瓶颈,那么查询缓存的作用也很小。
2、对于那些需要消耗大量资源的查询通常都是非常适合缓存的,对于复杂的SELECT语句都可以使用查询缓存,不过需要注意的是,涉及表上的UPDATE、DELETE、INSERT操作相比SELECT来说要非常少才行。
3、查询缓存命中率:Qcache_hits/(Qcahce_hits+Com_select),查询缓存命中率多大才是好的命中率,需要具体情况具体分析。只要查询缓存带来的效率提升大于查询缓存带来的额外消耗,即使30%的命中率也是值得。另外,缓存了哪些查询也很重要,如果被缓存的查询本身消耗巨大,那么即使缓存命中率低,对系统性能提升仍然是有好处的。
4、任何SELECT语句没有从查询缓存中返回都称为“缓存未命中”,以如下列情况:
- 查询语句无法被缓存,可能因为查询中包含一个不确定的函数,或者查询结果太大而无法缓存。
- MySQL从未处理这个查询,所以结果也从不曾被缓存过。
- 虽然之前缓存了查询结果,但由于查询缓存的内存用完了,MYSQL需要删除某些缓存,或者由于数据表被修改导致缓存失效。
如果服务器上有大量缓存缓存未命中,但是实际上绝大查询都被缓存了,那么一定是有如下情况发生:
- 查询缓存还没有完成预热,即MySQL还没有机会将查询结果都缓存起来。
- 查询语句之前从未执行过。如果应用程序不会重复执行一条查询语句,那么即使完成预热仍然会有很多缓存未命中。
- 缓存失效操作太多,缓存碎片、内存不足、数据修改都会造成缓存失效。可以通过参数Com_*来查看数据修改的情况(包括Com_update,Com_delete等),还可以通过Qcache_lowmem_prunes来查看有多少次失效是由于内存不足导致的。
5、有一个直观的方法能够反映查询缓存是否对系统有好处,推荐一个指标:”命中和写入“的比率,即Qcache_hits和Qcache_inserts的比值。根据经验来看,当这个比值大于3:1时通常查询缓存是有效的,如果能达到10:1最好。
6、通常可以通过观察查询缓存内存的实际使用情况Qcache_free_memory,来确定是否需要缩小或者扩大查询缓存。
五、MySQL缓存管理和配置
-
mysql> show variables like '%query_cache%';
-
+------------------------------+---------+
-
| Variable_name | Value |
-
+------------------------------+---------+
-
| have_query_cache | YES | --查询缓存是否可用
-
| query_cache_limit | 1048576 | --可缓存具体查询结果的最大值
-
| query_cache_min_res_unit | 4096 | --查询缓存分配的最小块的大小(字节)
-
| query_cache_size | 599040 | --查询缓存的大小
-
| query_cache_type | ON | --是否支持查询缓存
-
| query_cache_wlock_invalidate | OFF | --控制当有写锁加在表上的时候,是否先让该表相关的 Query Cache失效
-
+------------------------------+---------+
-
6 rows in set (0.02 sec)
- have_query_cache
该MySQL Server是否支持Query Cache。
- query_cache_limit
MySQL能够缓存的最大查询结果,查询结果大于该值时不会被缓存。默认值是1048576(1MB)如果某个查询的结果超出了这个值,Qcache_not_cached的值会加1,如果某个操作总是超出,可以考虑在SQL中加上SQL_NO_CACHE来避免额外的消耗。
- query_cache_min_res_unit
查询缓存分配的最小块的大小(字节)。 默认值是4096(4KB)。当查询进行的时候,MySQL把查询结果保存在qurey cache中,但如果要保存的结果比较大,超过query_cache_min_res_unit的值 ,这时候mysql将一边检索结果,一边进行保存结果,所以,有时候并不是把所有结果全部得到后再进行一次性保存,而是每次分配一块query_cache_min_res_unit大小的内存空间保存结果集,使用完后,接着再分配一个这样的块,如果还不不够,接着再分配一个块,依此类推,也就是说,有可能在一次查询中,mysql要进行多次内存分配的操作。适当的调节query_cache_min_res_unit可以优化内存如果你的查询结果都是一些small result,默认的query_cache_min_res_unit可能会造成大量的内存碎片如果你的查询结果都是一些larger resule,你可以适当的把query_cache_min_res_unit调大
- query_cache_size
为缓存查询结果分配的内存的数量,单位是字节,且数值必须是1024的整数倍。默认值是0,即禁用查询缓存。请注意如果设置了该值,即使query_cache_type设置为0也将分配此数量的内存。
- query_cache_type
设置查询缓存类型,默认为ON。设置GLOBAL值可以设置后面的所有客户端连接的类型。客户端可以设置SESSION值以影响他们自己对查询缓存的使用。下面的表显示了可能的值:
- query_cache_wlock_invalidate
如果某个表被锁住,是否返回缓存中的数据,默认关闭,也是建议的。一般情况,当客户端对MyISAM表进行WRITE锁定时,如果查询结果位于查询缓存中,则其它客户端未被锁定,可以对该表进行查询。将该变量设置为1,则可以对表进行WRITE锁定,使查询缓存内所有对该表进行的查询变得非法。这样当锁定生效时,可以强制其它试图访问表的客户端来等待。
- 开启缓存
-
mysql> set global query_cache_size = 600000; --设置缓存内存大小
-
mysql> set global query_cache_type = ON; --开启查询缓存
- 关闭缓存
-
mysql> set global query_cache_size = 0; --设置缓存内存大小为0, 即初始化是不分配缓存内存
-
mysql> set global query_cache_type = OFF; --关闭查询缓存
set global时需要有SUPER权限
六、MySQL Query Cache对性能的影响
6.1 MySQL Query Cache的额外开销
如上图所示: 在MySQL Server中打开Query Cache对数据库的读和写都会带来额外的消耗:
- 1) 读查询开始之前必须检查是否命中缓存。
- 2) 如果读查询可以缓存,那么执行完查询操作后,会查询结果和查询语句写入缓存。
- 3) 当向某个表写入数据的时候,必须将这个表所有的缓存设置为失效,如果缓存空间很大,则消耗也会很大,可能使系统僵死一段时间,因为这个操作是靠全局锁操作来保护的。
- 4) 对InnoDB表,当修改一个表时,设置了缓存失效,但是多版本特性会暂时将这修改对其他事务屏蔽,在这个事务提交之前,所有查询都无法使用缓存,直到这个事务被提交,所以长时间的事务,会大大降低查询缓存的命中
6.2 MySQL Query Cache碎片优化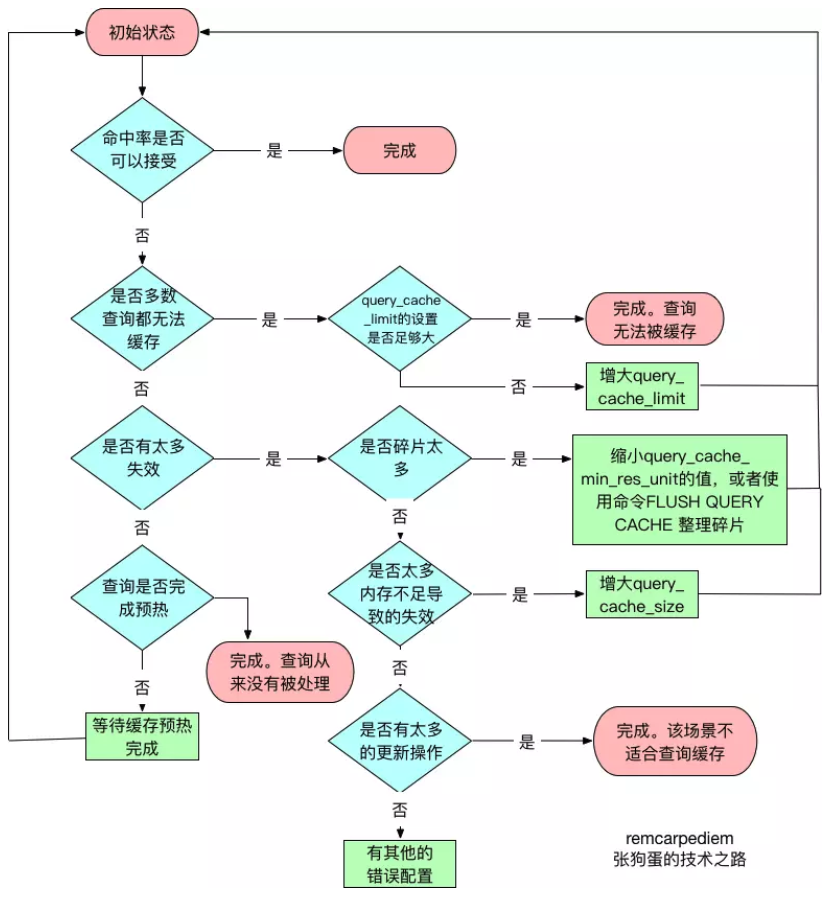
通过FLUSH_QUERY_CAHCE完成碎片整理,这个命令将所有的查询缓存重新排序,并将所有的空闲空间都聚焦到查询缓存的一块区域上。
-
mysql> SHOW STATUS LIKE 'Qcache%';
-
+-------------------------+--------+
-
| Variable_name | Value |
-
+-------------------------+--------+
-
| Qcache_free_blocks | 1 | ----在查询缓存中的闲置块,如果该值比较大,则说明Query Cache中的内存碎片可能比较多。FLUSH QUERY CACHE会对缓存中的碎片进行整理,从而得到一个较大的空闲内存块。
-
| Qcache_free_memory | 382704 | ----剩余缓存的大小
-
| Qcache_hits | 198 | ----缓存命中次数
-
| Qcache_inserts | 131 | ----缓存被插入的次数,也就是查询没有命中的次数。
-
| Qcache_lowmem_prunes | 0 | ----由于内存低而被删除掉的缓存条数,如果这个数值在不断增长,那么一般是Query Cache的空闲内存不足(通过Qcache_free_memory判断),或者内存碎片较严重(通过Qcache_free_blocks判断)。
-
| Qcache_not_cached | 169 | ----没有被缓存的条数,有三种情况会导致查询结果不会被缓存:其一,由于query_cache_type的设置;其二,查询不是SELECT语句;其三,使用了now()之类的函数,导致查询语句一直在变化。
-
| Qcache_queries_in_cache | 128 | ----缓存中有多少条查询语句
-
| Qcache_total_blocks | 281 | ----总块数
-
+-------------------------+--------+
-
8 rows in set (0.00 sec)
如果Query Cache碎片率超过20%,则可以用FLUSH QUERY CACHE整理内存碎片;如果你的查询都是小数据量的话,可以尝试减小query_cache_min_res_unit。
Query Cache利用率在25%以下的话,说明query_cache_size设置的过大,可适当减小;Query Cache利用率在80%以上,而且Qcache_lowmem_prunes > 50的话,说明query_cache_size可能有点小,或者就是内存碎片太多。
- 可缓存查询的Query Cache命中率 = Qcache_hits / (Qcache_hits + Qcache_inserts) * 100%
- 涵盖所有查询的Query Cache命中率 = Qcache_hits / (Qcache_hits + Com_select) * 100%
若命中率在50-70%的范围之内,则表明Query Cache的缓存效率较高。如果命中率明显小于50%,那么建议禁用(将query_cache_type设置为0(OFF))或按需使用(将query_cache_type设置为2(DEMAND))Query Cache,节省的内存可以用作InnoDB的缓冲池。
如果Qcache_free_blocks值比较大,表示内存碎片较多,需要使用FLUSH QUERY CACHE语句清理内存碎片。
query_cache_min_res_unit = (query_cache_size - Qcache_free_memory) / Qcache_queries_in_cache
其中,一般不建议将Query Cache的大小(也就是query_cache_size系统变量)设置超过256MB。
七、MySQL Query Cache优缺点
- 查询语句的hash计算和hash查找带来的资源消耗。如果将query_cache_type设置为1(也就是ON),那么MySQL会对每条接收到的SELECT类型的查询进行hash计算,然后查找这个查询的缓存结果是否存在。虽然hash计算和查找的效率已经足够高了,一条查询语句所带来的开销可以忽略,但一旦涉及到高并发,有成千上万条查询语句时,hash计算和查找所带来的开销就必须重视了。
- Query Cache的失效问题。如果表的变更比较频繁,则会造成Query Cache的失效率非常高。表的变更不仅仅指表中的数据发生变化,还包括表结构或者索引的任何变化。
- 查询语句不同,但查询结果相同的查询都会被缓存,这样便会造成内存资源的过度消耗。查询语句的字符大小写、空格或者注释的不同,Query Cache都会认为是不同的查询(因为他们的hash值会不同)。
- 相关系统变量设置不合理会造成大量的内存碎片,这样便会导致Query Cache频繁清理内存。
八、 生产如何设置MySQL Query Cache
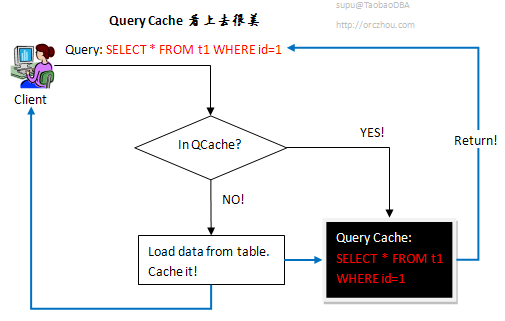
MySQL中的Query Cache是一个适用较少情况的缓存机制。如上图所示,如果缓存命中率非常高的话,有测试表明在极端情况下可以提高效率238%。但实际情况如何?Query Cache有如下规则,如果数据表被更改,那么和这个数据表相关的全部Cache全部都会无效,并删除之。这里“数据表更改”包括: INSERT, UPDATE, DELETE, TRUNCATE, ALTER TABLE, DROP TABLE, or DROP DATABASE等。举个例子,如果数据表posts访问频繁,那么意味着它的很多数据会被QC缓存起来,但是每一次posts数据表的更新,无论更新是不是影响到了cache的数据,都会将全部和posts表相关的cache清除。如果你的数据表更新频繁的话,那么Query Cache将会成为系统的负担。有实验表明,糟糕时,QC会降低系统13%的处理能力。
如果你的应用对数据库的更新很少,那么QC将会作用显著。比较典型的如博客系统,一般博客更新相对较慢,数据表相对稳定不变,这时候QC的作用会比较明显。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号