mysql sql使用记录
mysql 查询
1: Distinct
有时需要查询出某个字段不重复的记录,这时可以使用mysql提供的distinct这个关键字来过滤重复的记录,但是实际中我们往往用distinct来返回不重复字段的条数(count(distinct id)),其原因是distinct只能去重他的目标字段(即所有查询的字段)
注意: distinct必须放在要查询字段的开头
eg:
1:select distinct user_name from xxx 这样会过滤掉user_name 重复的,
2:如果这样写: select distinct id, user_name, password from xxx mysql会认为要过滤掉 id、user_name 、 password 都重复(完全一样)的,不然只要有一个字段不一样都会被查询出来;
注意:如果查询的有时间字段只有当时间的年月日时分秒都重复时才会被过滤掉
所以一般distinct用来查询不重复记录的条数。
如果要查询不重复的记录,有时候可以用group by
2:order by
注意:Mysql5.7及以上版本group by 子查询中order by 无效
如何解决?
1: 通过limit 语句使子查询的order by生效
但是这必须保证limit的数量,所以也可以使用DISTINCT实现。
3: group by
注意:使用group by 后默认返回的是每个组中id 最小的那一条记录
问题1: 对于mysql中的group by分组后如何获取组内创建时间最大(或最小)的那行数据 ?
以最大为例:
思路: 先对要查询的数据先进行降序排序,然后在使用group by 即可,但是会使用到子查询先排序(这里需要注意上面说到的order by)
SELECT
*
FROM(
SELECT
DISTINCT
*
FROM a
ORDER BY a.start_time DESC
) AS b
GROUP BY b.id
问题2:对一个结果集分组后怎么取每个分组的两条(或多条)最大(或最小)的数据?
取最大的两条:
SELECT
*
FROM student_score AS a
WHERE (
SELECT
COUNT(*)
FROM student_score AS b
WHERE a.student_name=b.student_name AND a.score<b.score
)<2
ORDER BY a.score DESC
取最小的两条:
SELECT
*
FROM student_score AS a
WHERE (
SELECT
COUNT(*)
FROM student_score AS b
WHERE a.student_name=b.student_name AND a.score>b.score
)<2
ORDER BY a.score DESC
4: update 怎样用查询出的一张表数据更新另一张表的字段??
用表B的数据(B1列,B2)更新表A的A1,A2列
update A, B set A.A1 = B.B1,A.A2=B.B2 where A.ID1 = B.ID1 and A.ID2 = B.ID2;
--或
update A INNER JOIN B ON A.ID1 = B.ID1 AND A.ID2= B.ID2 SET A.A1 = B.B1,A.A2=B.B2;
5: sql 查询某个条件下多条数据中最新的一条数据或最老的一条数据
test_user表结构如下:
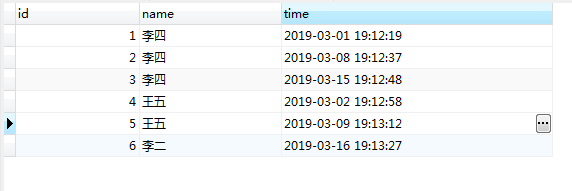
需求:查询李四、王五、李二创建的最初时间或者最新时间??
1:查询最初的创建时间:
SELECT
*
FROM(
SELECT
*
FROM test_user
) AS tu
WHERE NOT EXISTS (
SELECT * FROM(
SELECT
*
FROM test_user
) AS tu2 WHERE tu2.user_name=tu.user_name AND DATE(tu.time)>DATE(tu2.time)
)
查询结果如下:

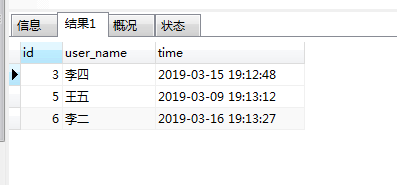
2:查询最新的记录
SELECT
*
FROM(
SELECT
*
FROM test_user
) AS tu
WHERE NOT EXISTS (
SELECT * FROM(
SELECT
*
FROM test_user
) AS tu2 WHERE tu2.user_name=tu.user_name AND DATE(tu.time)<DATE(tu2.time)
)
查询结果如下:
6、巧用 CASE WHEN 进行统计
假设我们有如下的需求,希望根据左边各个市的人口统计每个省的人口
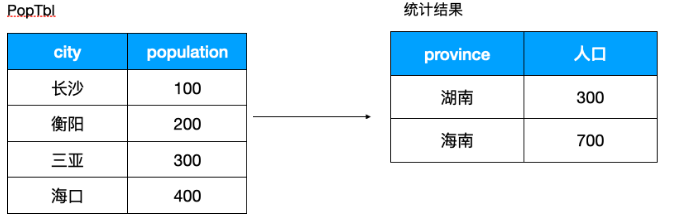
使用 CASE WHEN 如下:
SELECT CASE pref_name
WHEN '长沙' THEN '湖南'
WHEN '衡阳' THEN '湖南'
WHEN '海口' THEN '海南'
WHEN '三亚' THEN '海南'
ELSE '其他' END AS district,
SUM(population)
FROM PopTbl
GROUP BY district;
7、巧用 CASE WHEN 进行更新
现在公司出台了一个奇葩的规定
- 对当前工资为 1 万以上的员工,降薪 10%。
- 对当前工资低于 1 万的员工,加薪 20%。
一些人不假思索可能写出了以下的 SQL:
--条件1
UPDATE Salaries
SET salary = salary * 0.9 WHERE salary >= 10000;
--条件2
UPDATE Salaries
SET salary = salary * 1.2
WHERE salary < 10000;
这么做其实是有问题的, 什么问题,对小明来说,他的工资是 10500,执行第一个 SQL 后,工资变为 10500 * 0.9 = 9450, 紧接着又执行条件 2, 工资变为了 9450 * 1.2 = 11340,反而涨薪了!
如果用 CASE WHEN 可以解决此类问题,如下:
UPDATE Salaries
SET salary = CASE WHEN salary >= 10000 THEN salary * 0.9
WHEN salary < 10000 THEN salary * 1.2
ELSE salary END;
8、巧用 HAVING 子句
一般 HAVING 是与 GROUP BY 结合使用的,但其实它是可以独立使用的, 假设有如下表,第一列 seq 叫连续编号,但其实有些编号是缺失的,怎么知道编号是否缺失呢,

用 HAVING 表示如下:
SELECT '存在缺失的编号' AS gap
FROM SeqTbl
HAVING COUNT(*) <> MAX(seq);
灵活使用 HAVING 子句
修改前:
SELECT *
FROM (SELECT sale_date, MAX(quantity) AS max_qty
FROM SalesHistory
GROUP BY sale_date) TMP
WHERE max_qty >= 10;
修改后:
SELECT
sale_date,
MAX(quantity)
FROM SalesHistory
GROUP BY sale_date
HAVING MAX(quantity) >= 10;
9、自连接
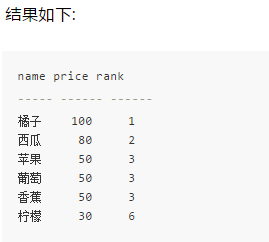
我们经常需要按分数,人数,销售额等进行排名,有 Oracle, DB2 中可以使用 RANK 函数进行排名,不过在 MySQL 中 RANK 函数未实现,这种情况我们可以使用自连接来实现,如对以下 Products 表按价格高低进行排名
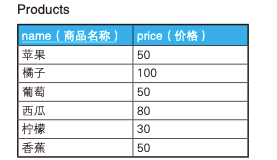
使用自连接可以这么写:
-- 排序从 1 开始。如果已出现相同位次,则跳过之后的位次
SELECT P1.name,
P1.price,
(SELECT COUNT(P2.price)
FROM Products P2
WHERE P2.price > P1.price) + 1 AS rank_1
FROM Products P1
ORDER BY rank_1;

 浙公网安备 33010602011771号
浙公网安备 33010602011771号