调用链跟踪基本原理
场景:
开发和运维人员从入口服务A开始查起,确认服务A没有问题,然后到服务B,在服务B中进行排查,确认服务B没有问题,在传递到服务C中进行排查,以此类推。有时查一个问题,会把服务架构中的多个应用查询一遍,而有时出问题的系统恰恰是底层系统,在排查了多个不必要的系统后才能准确的定位问题。
如何解决该问题呢?那就是服务调用链路跟踪
调用链路跟踪
谷歌在2010年发布的Dapper论文中介绍了谷歌分布式系统跟踪的基础原理和架构,介绍了谷歌以低成本实现应用级透明的遍布多个服务的调用链跟踪系统的方法。
Dapper开始仅仅是一个独立的调用链路跟踪系统,后来逐步演化为一个监控平台,并且在监控平台上孕育了许多工具。
典型的分布式系统的调用关系图: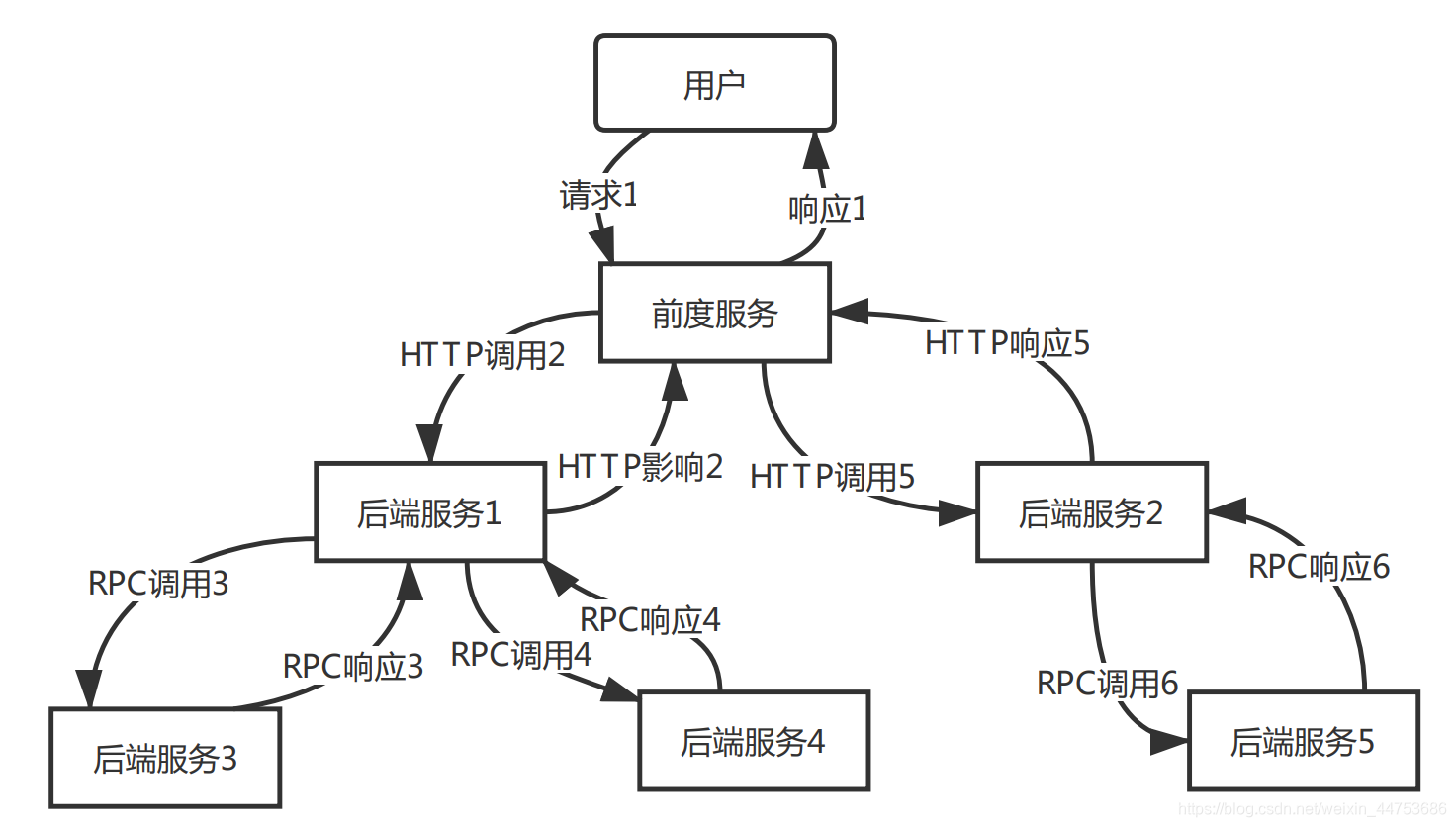
服务调用结构是一个树型结构,树节点是整个架构的基本单元,每个节点是一个独立的服务节点。在谷歌的Dapper论文中,每个节点都对应一个Span,节点之间的连线表示Span和它的父Span之间的关系,具体表现为一次调用请求和响应的调用关系。
我们先关注两个服务之间的同学,两个服务之间有成千上万次通信,服务1与服务2进行交互时,会发送一个请求1,并接收到一个响应1,那么我们通过什么手段标示响应和请求是一对呢?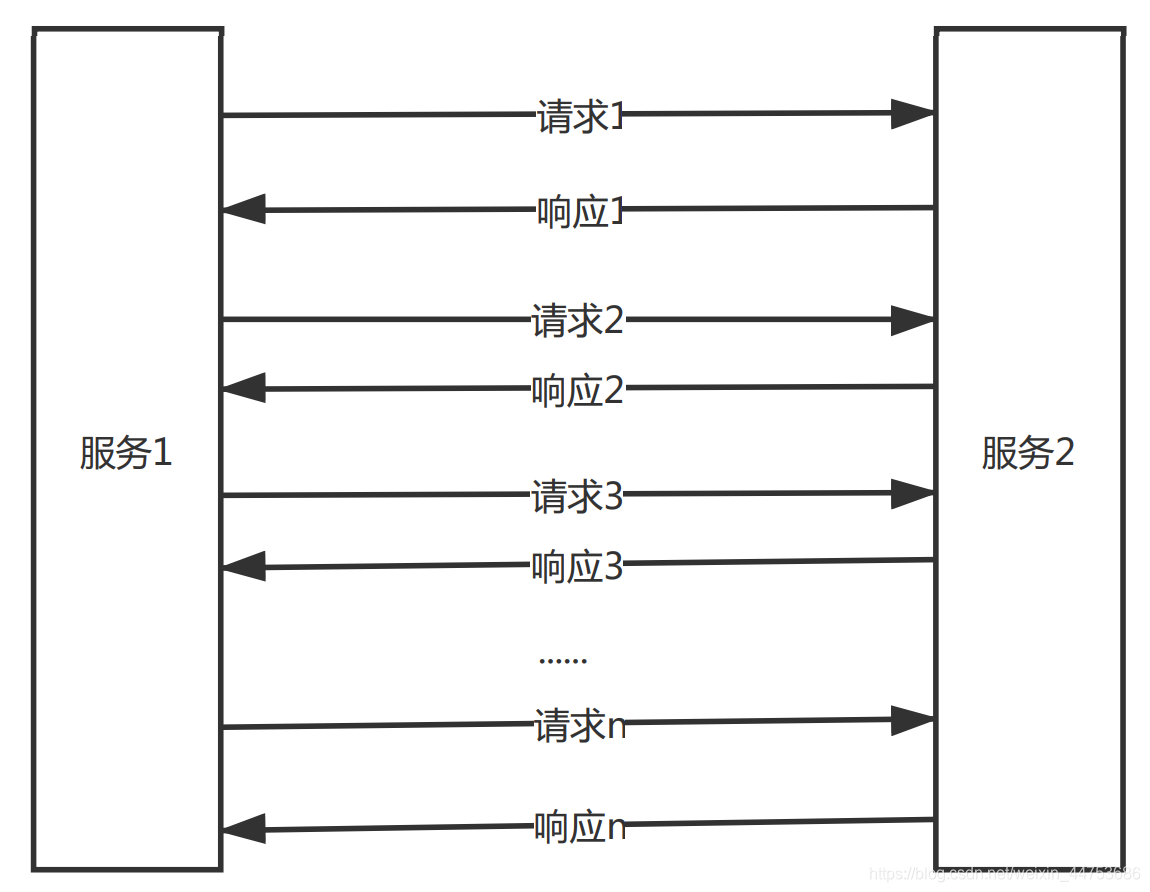
谷歌的Dapper论文通过增加应用层的标记对服务化中的请求和响应建立联系,例如通过HTTP协议头携带标记信息,标记信息包括标示调用链的唯一ID,这里叫作TraceID,以及标示调用层次和顺序的SpanID和ParentSpanID。
下面是一次调用需要保存的调用信息: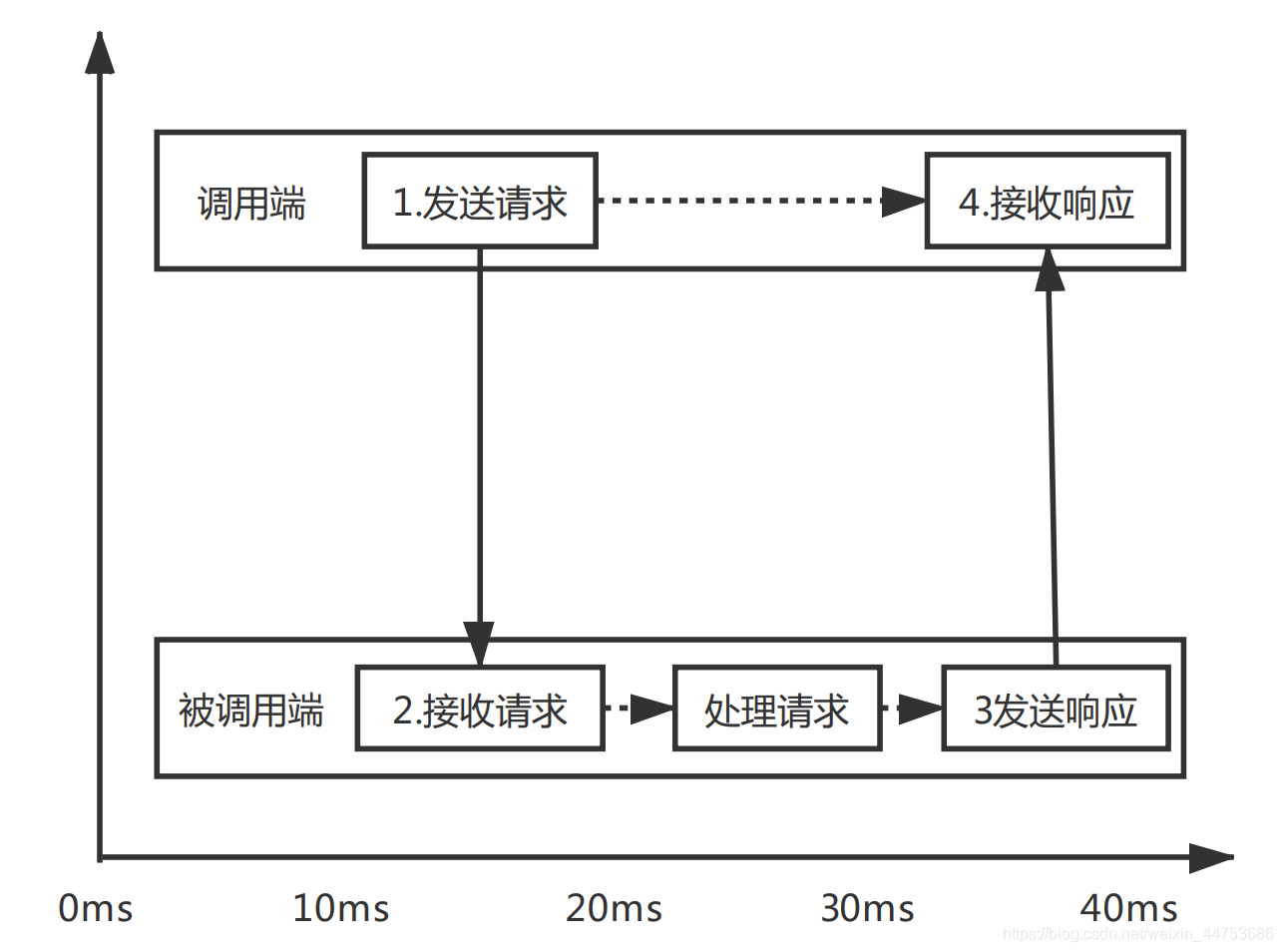
调用信息包含:调用端或者被调用端的ID、系统ID;本次请求的TraceID、SpanID和ParentSpanID;时间戳、调用的方法名称及远程调用信息的类型,等等。
TraceID
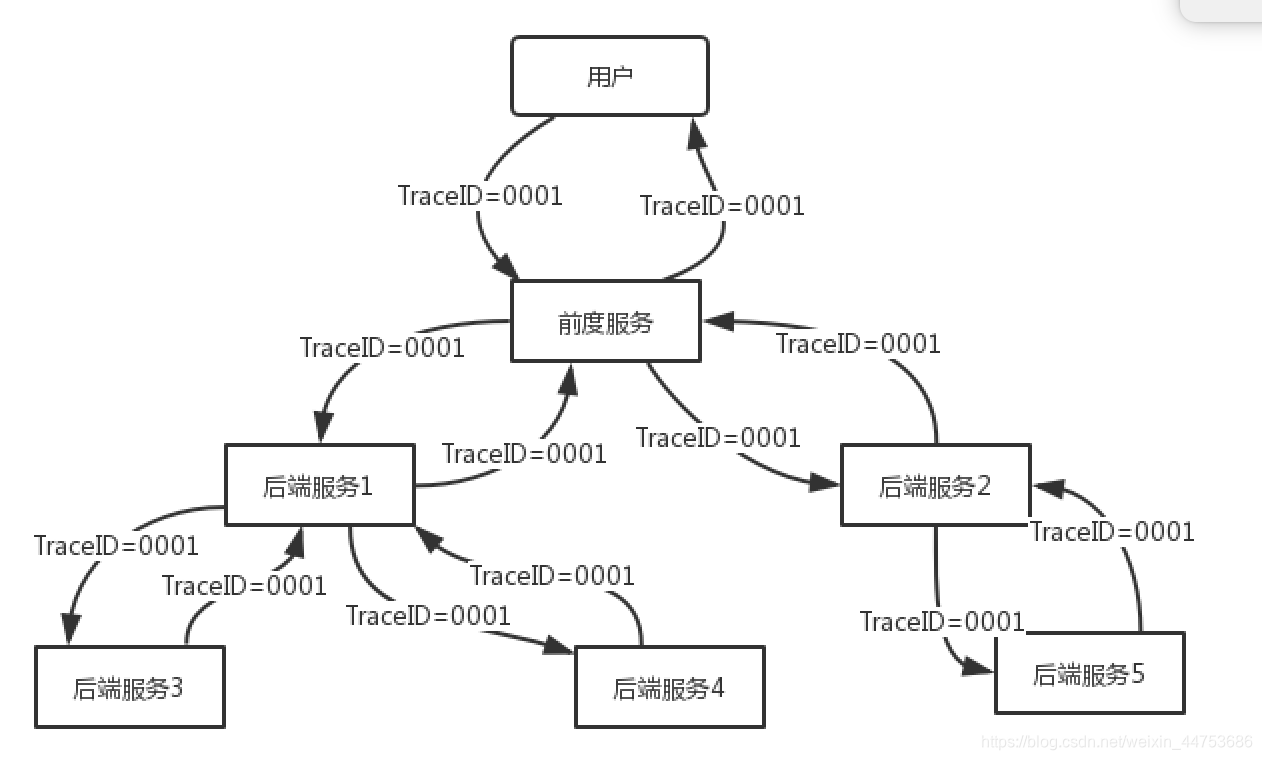
前端接收用户请求后会为用户分配一个TraceID,在内部服务调用时,会通过应用层的协议将TraceID传递到下层服务,直到整个调用链的每个节点都拥有TraceID,这样在系统出现问题时,可以使用这个唯一TraceID迅速问题发生的节点。
SpanID
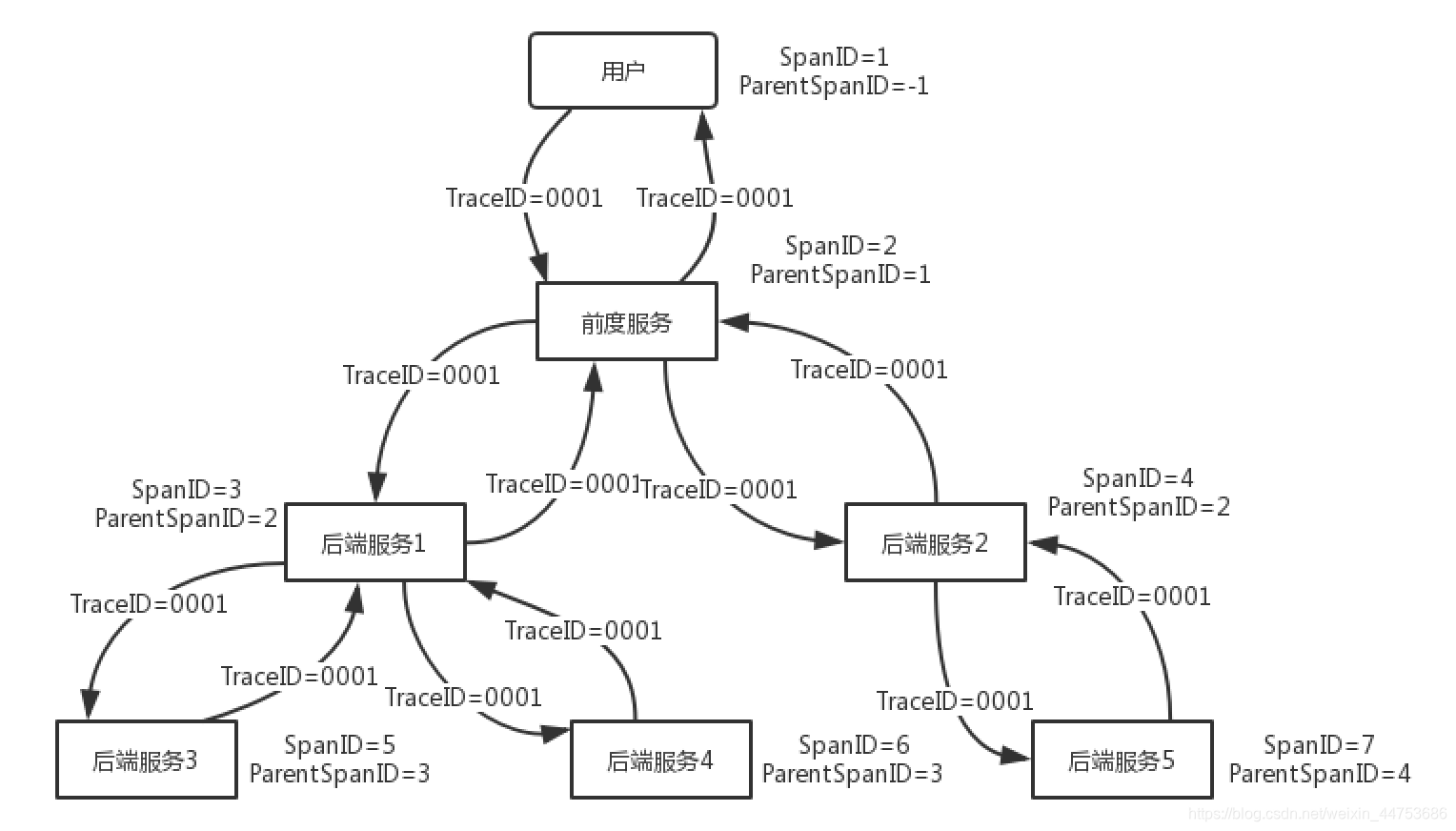
TraceID解决了系统串联的问题,但是我们无法标识和恢复这些请求和响应调用时的顺序和层级关系.
因此我们需要附加的信息在系统之间的请求和响应消息中传递,它就是SpanID,这里SpanID包含SpanID和ParentSpanID
SpanID和ParentSpanID组合在一起就可以表示一个树形的调用关系,SpanID表示当前为一个调用节点,ParentSpanID表示这个调用节点的父节点。
以下通过时序的角度来看下SpanID和ParentSpanID在调用链中携带的信息和含义: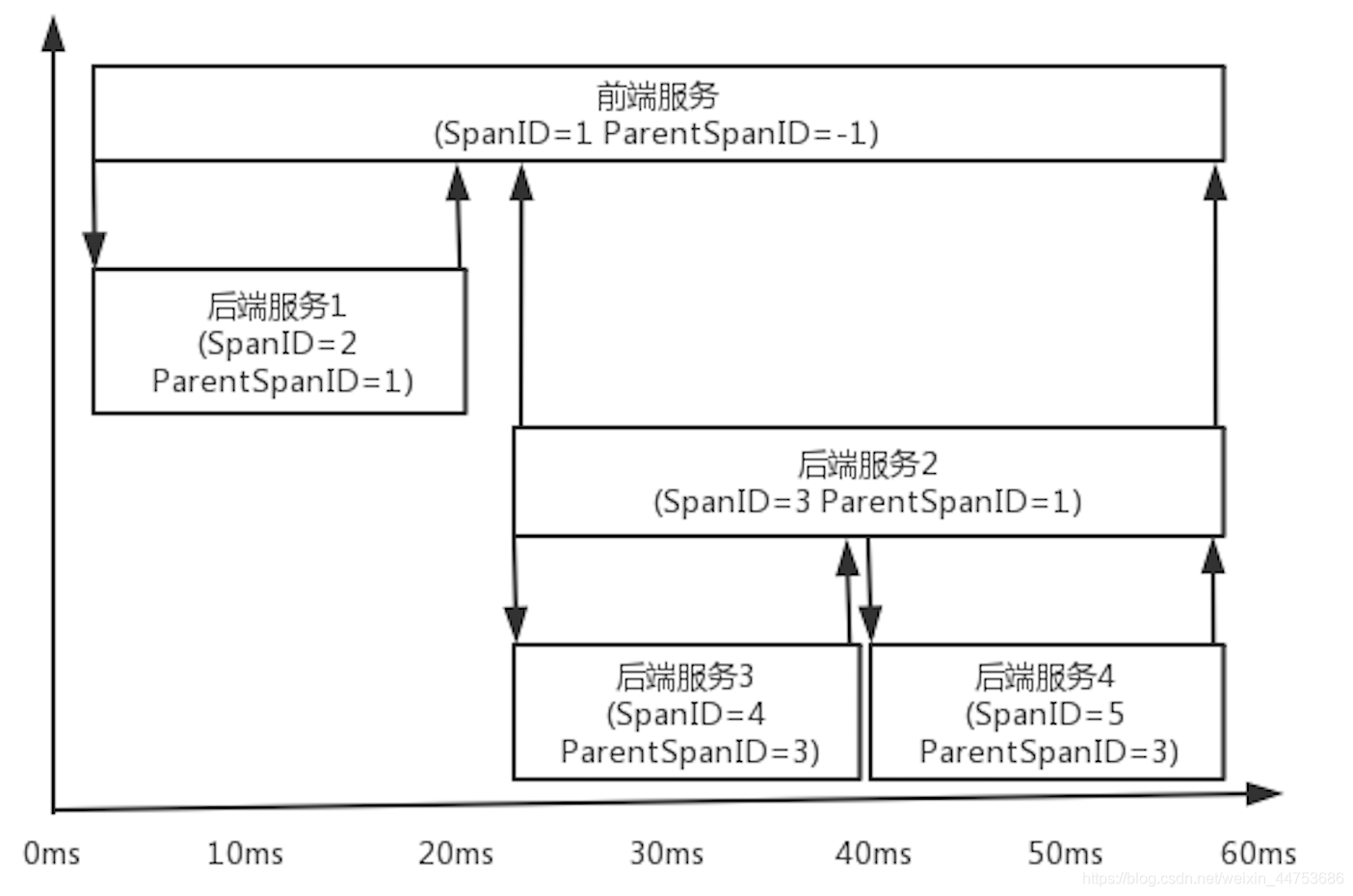
当系统出现故障时,只需4步即可:
- (1)通过TraceID把一整条调用链的所有调用信息收集到一个集合中,包括请求和响应
- (2)通过SpanID和ParentSpanID恢复树形的调用树,ParentSpanID为-1的节点为根节点
- (3)识别调用链中出错或超时的节点,做出标记
- (4)把恢复的调用树和出错的节点信息通过某种图形显示到UI界面上。
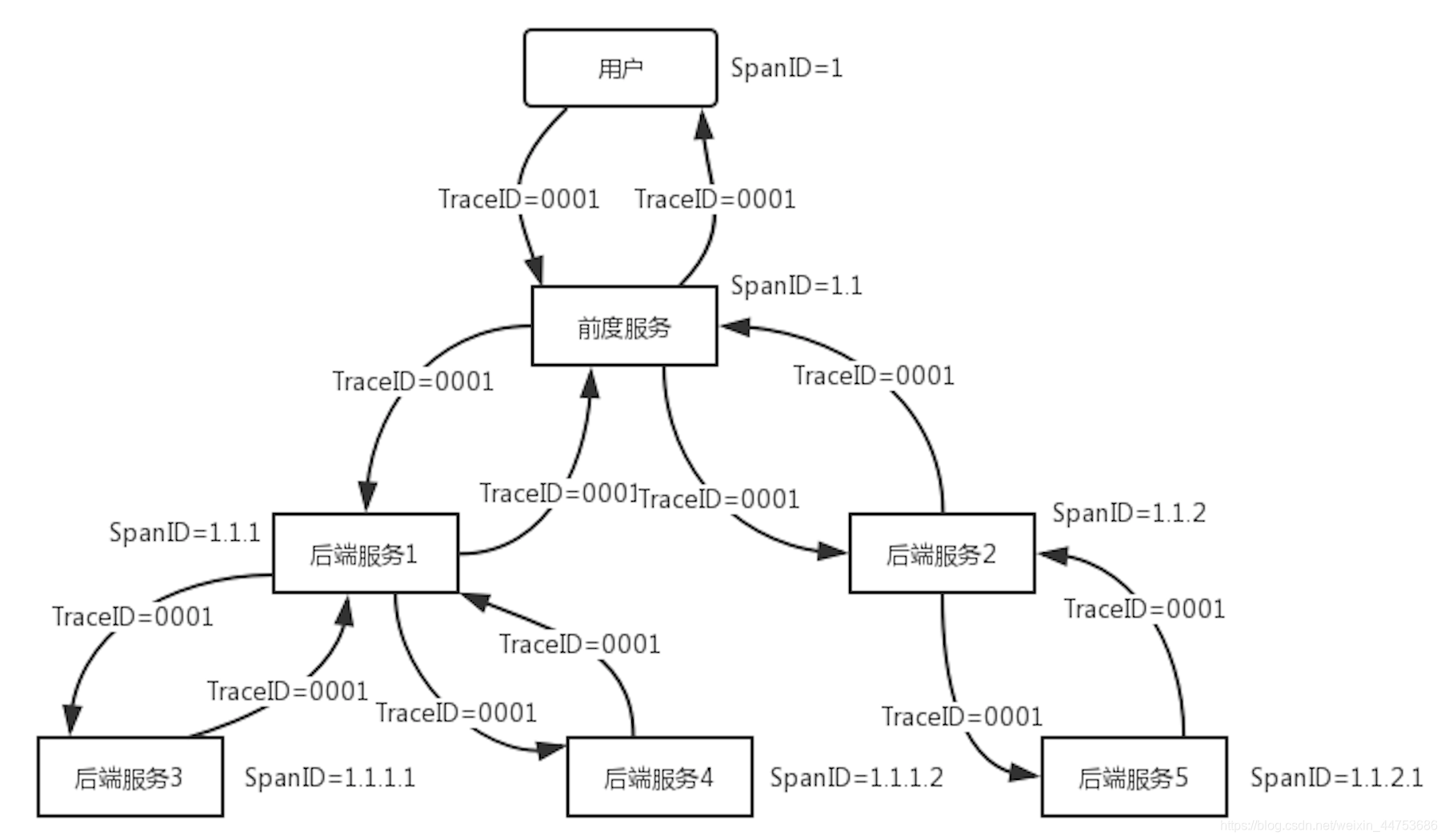
有多种策略产生SpanID
- (1)使用随机数产生SpanID,理论上有可能重复,但是由于64位长整型,重复的可能性微乎其微,并且本地生成随机数的效率高于其他方法。
- (2)使用分布式的全局唯一的流水号生成方式,可参考互联网发好器Vesta。
- (3)每个SpanID包含所有父亲及前辈节点的SpanID,使用圆点符号作为分隔符,不再需要ParentSpanID字段,如下图,这种方案实现起来简单,但是如果调用链有太多的节点和层次时,SpanID会携带太多的冗余信息,导致服务间调用的性能下降。
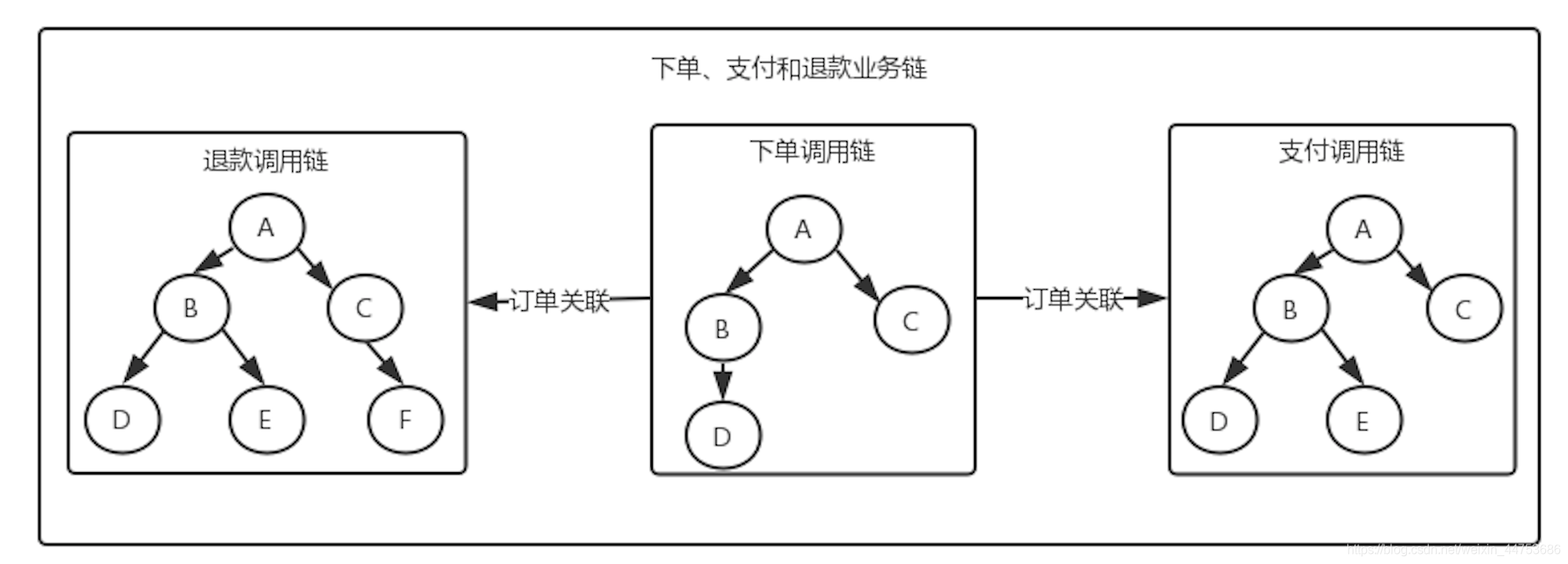
业务链
在实践中,由于业务流程的复杂性,一个业务流程的完成由用户的多次请求组成,这些请求之间是有关联的,我们在串联调用链滞后,会根据业务的数学,将不同的调用链聚合在一起形成业务链。
我们需要在多次请求之间建立联系,可以通过业务的业务ID(如:订单ID)来串联业务链,如果调用链是一个简单的树形结构,而业务链就是一个森林结构: