
分布式系统理论概述
分布式系统是什么
分布式系统:一个硬件或软件组件分布在不同的网络计算机上,彼此之间仅仅通过消息传递进行通信和协调的系统
这是分布式系统,在不同的硬件,不同的软件,不同的网络,不同的计算机上,仅仅通过消息来进行通讯与协调
这是他的特点,更细致的看这些特点又可以有:分布性、对等性、并发性、缺乏全局时钟、
故障随时会发生。
分布性
既然是分布式系统,最显著的特点肯定就是分布性,从简单来看,如果我们做的是个电商项目,整个项目会分成不同的功能,专业点就不同的微服务,比如用户微服务,产品微服务,订单微服务,这些服务部署在不同的tomcat中,不同的服务器中,甚至不同的集群中,整个架构都是分布在不同的地方的,在空间上是随意的,而且随时会增加,删除服务器节点,这是第一个特性
对等性
对等性是分布式设计的一个目标,还是以电商网站为例,来说明下什么是对等性,要完成一个分布式的系统架构,肯定不是简单的把一个大的单一系统拆分成一个个微服务,然后部署在不同的服务器集群就够了,其中拆分完成的每一个微服务都有可能发现问题,而导致整个电商网站出现功能的丢失。
比如订单服务,为了防止订单服务出现问题,一般情况需要有一个备份,在订单服务出现问题的时候能顶替原来的订单服务。
这就要求这两个(或者2个以上)订单服务完全是对等的,功能完全是一致的,其实这就是一种服务副本的冗余。
还一种是数据副本的冗余,比如数据库,缓存等,都和上面说的订单服务一样,为了安全考虑需要有完全一样的备份存在,这就是对等性的意思。
并发性
并发性其实对我们来说并不模式,在学习多线程的时候已经或多或少学习过,多线程是并发的基础。
但现在我们要接触的不是多线程的角度,而是更高一层,从多进程,多JVM的角度,例如在一个分布式系统中的多个节点,可能会并发地操作一些共享资源,如何准确并高效的协调分布式并发操作。
后面实战部分的分布式锁其实就是解决这问题的。
缺乏全局时钟
在分布式系统中,节点是可能反正任意位置的,而每个位置,每个节点都有自己的时间系统,因此在分布式系统中,很难定义两个事务纠结谁先谁后,原因就是因为缺乏一个全局的时钟序列进行控制,当然,现在这已经不是什么大问题了,已经有大把的时间服务器给系统调用
故障随时会发生
任何一个节点都可能出现停电,死机等现象,服务器集群越多,出现故障的可能性就越大,随着集群数目的增加,出现故障甚至都会成为一种常态,怎么样保证在系统出现故障,而系统还是正常的访问者是作为系统架构师应该考虑的。
分布式系统协调“方法论”
分布式系统带来的问题
如果把分布式系统和平时的交通系统进行对比,哪怕再稳健的交通系统也会有交通事故,分布式系统也有很多需要攻克的问题,比如:通讯异常,网络分区,三态,节点故障等。
通信异常
通讯异常其实就是网络异常,网络系统本身是不可靠的,由于分布式系统需要通过网络进行数据传输,网络光纤,路由器等硬件难免出现问题。只要网络出现问题,也就会影响消息的发送与接受过程,因此数据消息的丢失或者延长就会变得非常普遍。
网络分区
网络分区,其实就是脑裂现象,本来有一个交通警察,来管理整个片区的交通情况,一切井然有序,突然出现了停电,或者出现地震等自然灾难,某些道路接受不到交通警察的指令,可能在这种情况下,会出现一个零时工,片警零时来指挥交通。
但注意,原来的交通警察其实还在,只是通讯系统中断了,这时候就会出现问题了,在同一个片区的道路上有不同人在指挥,这样必然引擎交通的阻塞混乱。
这种由于种种问题导致同一个区域(分布式集群)有两个相互冲突的负责人的时候就会出现这种精神分裂的情况,在这里称为脑裂,也叫网络分区。
. 三态
三态是什么?三态其实就是成功,与失败以外的第三种状态,当然,肯定不叫变态,而叫超时态。
在一个jvm中,应用程序调用一个方法函数后会得到一个明确的相应,要么成功,要么失败,而在分布式系统中,虽然绝大多数情况下能够接受到成功或者失败的相应,但一旦网络出现异常,就非常有可能出现超时,当出现这样的超时现象,网络通讯的发起方,是无法确定请求是否成功处理的。
节点故障
这个其实前面已经说过了,节点故障在分布式系统下是比较常见的问题,指的是组成服务器集群的节点会出现的宕机或“僵死”的现象,这种现象经常会发生。
CAP理论
前面花费了很大的篇幅来了解分布式的特点以及会碰到很多会让人头疼的问题,这些问题肯定会有一定的理论思想来解决问题的。
接下来花点时间来谈谈这些理论,其中CAP和BASE理论是基础,也是面试的时候经常会问到的
首先看下CAP,CAP其实就是一致性,可用性,分区容错性这三个词的缩写
一致性
一致性是事务ACID的一个特性【原子性(Atomicity)、一致性(Consistency)、隔离性(Isolation)、持久性(Durability)】,学习数据库优化的时候deer老师讲过。
这里讲的一致性其实大同小异,只是现在考虑的是分布式环境中,还是不单一的数据库。
在分布式系统中,一致性是数据在多个副本之间是否能够保证一致的特性,这里说的一致性和前面说的对等性其实差不多。如果能够在分布式系统中针对某一个数据项的变更成功执行后,所有用户都可以马上读取到最新的值,那么这样的系统就被认为具有【强一致性】。
可用性
可用性指系统提供服务必须一直处于可用状态,对于用户的操作请求总是能够在有限的时间内访问结果。
这里的重点是【有限的时间】和【返回结果】
为了做到有限的时间需要用到缓存,需要用到负载,这个时候服务器增加的节点是为性能考虑;
为了返回结果,需要考虑服务器主备,当主节点出现问题的时候需要备份的节点能最快的顶替上来,千万不能出现OutOfMemory或者其他500,404错误,否则这样的系统我们会认为是不可用的。
分区容错性
分布式系统在遇到任何网络分区故障的时候,仍然需要能够对外提供满足一致性和可用性的服务,除非是整个网络环境都发生了故障。
不能出现脑裂的情况
具体描述
来看下CAP理论具体描述:
一个分布式系统不可能同时满足一致性、可用性和分区容错性这三个基本需求,最多只能同时满足其中的两项
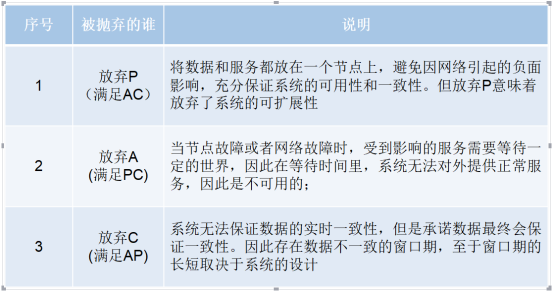
TIPS:不可能把所有应用全部放到一个节点上,因此架构师的精力往往就花在怎么样根据业务场景在A和C直接寻求平衡;
BASE理论
根据前面的CAP理论,架构师应该从一致性和可用性之间找平衡,系统短时间完全不可用肯定是不允许的,那么根据CAP理论,在分布式环境下必然也无法做到强一致性。
BASE理论:即使无法做到强一致性,但分布式系统可以根据自己的业务特点,采用适当的方式来使系统达到最终的一致性;
Basically Avaliable 基本可用
当分布式系统出现不可预见的故障时,允许损失部分可用性,保障系统的“基本可用”;体现在“时间上的损失”和“功能上的损失”;
e.g:部分用户双十一高峰期淘宝页面卡顿或降级处理;
Soft state 软状态
其实就是前面讲到的三态,既允许系统中的数据存在中间状态,既系统的不同节点的数据副本之间的数据同步过程存在延时,并认为这种延时不会影响系统可用性;
e.g:12306网站卖火车票,请求会进入排队队列;
Eventually consistent 最终一致性
所有的数据在经过一段时间的数据同步后,最终能够达到一个一致的状态;
e.g:理财产品首页充值总金额短时不一致;
其实可能发现不管是CAP理论,还是BASE理论,他们都是理论,这些理论是需要算法来实现的,今天讲的2PC、3PC、Paxos算法,ZAB算法就是干这事情。
所以解决的问题全部都是在分布式环境下,怎么让系统尽可能的高可用,而且数据能最终能达到一致。
1.1.1. 两阶段提交 two-phase commit (2PC)
首先来看下2PC,翻译过来叫两阶段提交算法,它本身是一致强一致性算法,所以很适合用作数据库的分布式事务。其实数据库的经常用到的TCC本身就是一种2PC.
MySQL innodb存储引擎,对数据库的修改都会写到undo和redo中,不只是数据库,很多需要事务支持的都会用到这个思路。
对一条数据的修改操作首先写undo日志,记录的数据原来的样子,接下来执行事务修改操作,把数据写到redo日志里面,万一捅娄子,事务失败了,可从undo里面回复数据。
不只是数据库,在很多企业里面,比如华为等提交数据库修改都回要求这样,你要新增一个字段,首先要把修改数据库的字段SQL提交给DBA(redo),这不够,还需要把删除你提交字段,把数据还原成你修改之前的语句也一并提交者叫(undo)
数据库通过undo与redo能保证数据的强一致性,要解决分布式事务的前提就是当个节点是支持事务的。
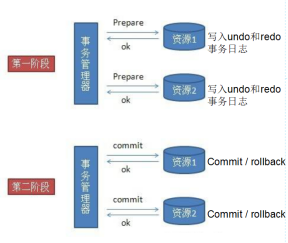
这在个前提下,2pc借鉴这失效,首先把整个分布式事务分两节点,首先第一阶段叫准备节点,事务的请求都发送给一个个的资源,这里的资源可以是数据库,也可以是其他支持事务的框架,他们会分别执行自己的事务,写日志到undo与redo,但是不提交事务。
当事务管理器收到了所以资源的反馈,事务都执行没报错后,事务管理器再发送commit指令让资源把事务提交,一旦发现任何一个资源在准备阶段没有执行成功,事务管理器会发送rollback,让所有的资源都回滚。这就是2pc,
优点:原理简单,实现方便
缺点:同步阻塞,单点问题,数据不一致,容错性不好
同步阻塞
在二阶段提交的过程中,所有的节点都在等待其他节点的响应,无法进行其他操作。这种同步阻塞极大的限制了分布式系统的性能。
单点问题
协调者在整个二阶段提交过程中很重要,如果协调者在提交阶段出现问题,那么整个流程将无法运转。更重要的是,其他参与者将会处于一直锁定事务资源的状态中,而无法继续完成事务操作。
数据不一致
假设当协调者向所有的参与者发送commit请求之后,发生了局部网络异常,或者是协调者在尚未发送完所有 commit请求之前自身发生了崩溃,导致最终只有部分参与者收到了commit请求。这将导致严重的数据不一致问题。
.容错性不好
二阶段提交协议没有设计较为完善的容错机制,任意一个节点是失败都会导致整个事务的失败。
三阶段提交 three-phase commit (3PC)
由于二阶段提交存在着诸如同步阻塞、单点问题,所以,研究者们在二阶段提交的基础上做了改进,提出了三阶段提交。
第一阶段canCommit
确认所有的资源是否都是健康、在线的,以约女孩举例,你会打个电话问下她是不是在家,而且可以约个会。
如果女孩有空,你在去约她。
就因为有了这一阶段,大大的减少了2段提交的阻塞时间,在2段提交,如果有3个数据库,恰恰第三个数据库出现问题,其他两个都会执行耗费时间的事务操作,到第三个却发现连接不上。3段优化了这种情况
第二阶段PreCommit
如果所有服务都ok,可以接收事务请求,这一阶段就可以执行事务了,这时候也是每个资源都回写redo与undo日志,事务执行成功,返回ack(yes),否则返回no
第三阶段doCommit
这阶段和前面说的2阶段提交大同小异,这个时候协调者发现所有提交者事务提交者事务都正常执行后,给所有资源发送commit指令。
和二阶段提交有所不同的是,他要求所有事务在协调者出现问题,没给资源发送commit指令的时候,三阶段提交算法要求资源在一段时间超时后回默认提交做commit操作。
这样的要求就减少了前面说的单点故障,万一事务管理器出现问题,事务也回提交。
但回顾整个过程,不管是2pc,还是3pc,同步阻塞,单点故障,容错机制不完善这些问题都没本质上得到解决,尤其是前面说得数据一致性问题,反而更糟糕了。
所有数据库的分布式事务一般都是二阶段提交,而者三阶段的思想更多的被借鉴扩散成其他的算法。
Paxos算法

身这算法的提出者莱斯利·兰伯特在前面几篇论文中都不是以严谨的数学公式进行的。
paxos算法也分成两阶段。首先这个图有2个角色,提议者与接收者
第一阶段
提议者对接收者吼了一嗓子,我有个事情要告诉你们,当然这里接受者不只一个,它也是个分布式集群
相当于星期一开早会,可耻的领导吼了句:“要开会了啊,我要公布一个编号为001的提案,收到请回复”。
这个时候领导就会等着,等员工回复1“好的”,如果回复的数目超过一半,就会进行下一步。
如果由于某些原因(接收者死机,网络问题,本身业务问题),导通过的协议未超过一半,
这个时候的领导又会再吼一嗓子,当然气势没那凶残:“好了,怕了你们了,我要公布一个新的编号未002的提案,收到请回复1”
第二阶段
接下来到第二阶段,领导苦口婆心的把你们叫来开会了,今天编号002提案的内容是:“由于项目紧张,今天加班到12点,同意的请举手”这个时候如果绝大多少的接收者都同意,那么好,议案就这么决定了,如果员工反对或者直接夺门而去,那么领导又只能从第一个阶段开始:“大哥,大姐们,我有个新的提案003,快回会议室吧。。”
上面那个故事描绘的是个苦逼的领导和凶神恶煞的员工之间的斗争,通过这个故事你们起码要懂paxos协议的流程是什么样的(paxos的核心就是少数服从多数)。
上面的故事有两个问题:
苦逼的领导(单点问题):有这一帮凶残的下属,这领导要不可能被气死,要不也会辞职,这是单点问题。
凶神恶煞的下属(一致性问题):如果员工一种都拒绝,故意和领导抬杆,最终要产生一个一致性的解决方案是不可能的。
所以paxos协议肯定不会只有一个提议者,作为下属的员工也不会那么强势
协议要求:如果接收者没有收到过提案编号,他必须接受第一个提案编号
如果接收者没有收到过其他协议,他必须接受第一个协议。
举一个例子:
有2个Proposer(老板,老板之间是竞争关系)和3个Acceptor(政府官员):
. 阶段一
1.现在需要对一项议题来进行paxos过程,议题是“A项目我要中标!”,这里的“我”指每个带着他的秘书Proposer的Client老板。
2.Proposer当然听老板的话了,赶紧带着议题和现金去找Acceptor政府官员。
3.作为政府官员,当然想谁给的钱多就把项目给谁。
4.Proposer-1小姐带着现金同时找到了Acceptor-1~Acceptor-3官员,1与2号官员分别收取了10比特币,找到第3号官员时,没想到遭到了3号官员的鄙视,3号官员告诉她,Proposer-2给了11比特币。不过没关系,Proposer-1已经得到了1,2两个官员的认可,形成了多数派(如果没有形成多数派,Proposer-1会去银行提款在来找官员们给每人20比特币,这个过程一直重复每次+10比特币,直到多数派的形成),满意的找老板复命去了,但是此时Proposer-2保镖找到了1,2号官员,分别给了他们11比特币,1,2号官员的态度立刻转变,都说Proposer-2的老板懂事,这下子Proposer-2放心了,搞定了3个官员,找老板复命去了,当然这个过程是第一阶段提交,只是官员们初步接受贿赂而已。故事中的比特币是编号,议题是value。
这个过程保证了在某一时刻,某一个proposer的议题会形成一个多数派进行初步支持(初步达成共识)
1.1.1.3.2. 阶段二
5. 现在进入第二阶段提交,现在proposer-1小姐使用分身术(多线程并发)分了3个自己分别去找3位官员,最先找到了1号官员签合同,遭到了1号官员的鄙视,1号官员告诉他proposer-2先生给了他11比特币,因为上一条规则的性质proposer-1小姐知道proposer-2第一阶段在她之后又形成了多数派(至少有2位官员的赃款被更新了);此时她赶紧去提款准备重新贿赂这3个官员(重新进入第一阶段),每人20比特币。刚给1号官员20比特币, 1号官员很高兴初步接受了议题,还没来得及见到2,3号官员的时候
这时proposer-2先生也使用分身术分别找3位官员(注意这里是proposer-2的第二阶段),被第1号官员拒绝了告诉他收到了20比特币,第2,3号官员顺利签了合同,这时2,3号官员记录client-2老板用了11比特币中标,因为形成了多数派,所以最终接受了Client2老板中标这个议题,对于proposer-2先生已经出色的完成了工作;
这时proposer-1小姐找到了2号官员,官员告诉她合同已经签了,将合同给她看,proposer-1小姐是一个没有什么职业操守的聪明人,觉得跟Client1老板混没什么前途,所以将自己的议题修改为“Client2老板中标”,并且给了2号官员20比特币,这样形成了一个多数派。顺利的再次进入第二阶段。由于此时没有人竞争了,顺利的找3位官员签合同,3位官员看到议题与上次一次的合同是一致的,所以最终接受了,形成了多数派,proposer-1小姐跳槽到Client2老板的公司去了。
总结:Paxos过程结束了,这样,一致性得到了保证,算法运行到最后所有的proposer都投“client2中标”所有的acceptor都接受这个议题,也就是说在最初的第二阶段,议题是先入为主的,谁先占了先机,后面的proposer在第一阶段就会学习到这个议题而修改自己本身的议题,因为这样没职业操守,才能让一致性得到保证,这就是paxos算法的一个过程。原来paxos算法里的角色都是这样的不靠谱,不过没关系,结果靠谱就可以了。该算法就是为了追求结果的一致性。
集群一致性协议ZAB解析
懂了paxos算法,其实zab就很好理解了。很多论文和资料都证明zab其实就是paxos的一种简化实现,但Apache 自己的立场说zab不是paxos算法的实现,这个不需要去计较。

