


mysql,存储引擎,事务,锁,慢查询,执行计划分析,sql优化
基础篇:MySql架构与存储引擎
逻辑架构图:

连接层:
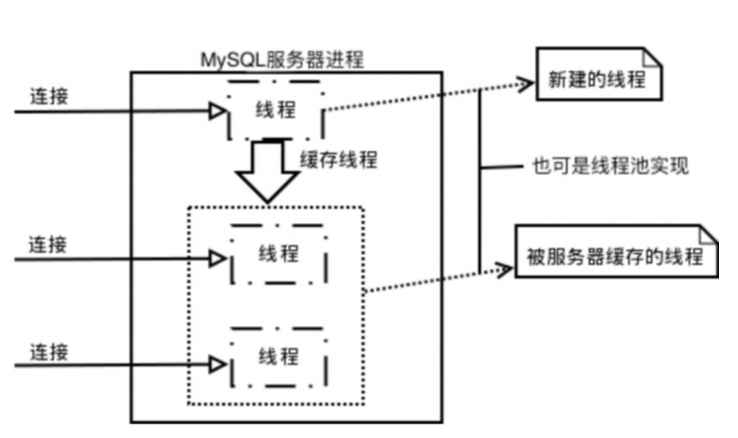
mysql启动后(可以把mysql类比为一个后台的服务器),等待客户端请求,当请求到来后,mysql建立一个一个线程处理(线程池则分配一个空线程,当然也可使用nio线程模型。),每个线程独立,拥有独自内存空间。当请求为select请求则没有关系,但是请求为update时,多线程同时修改一块内存,就会引发一系列问题,由此引出 “锁“的概念。
查看mysql当前连接数:
show VARIABLES like '%max_connections%'
修改mysql连接数为200
set GLOBAL max_connections = 200
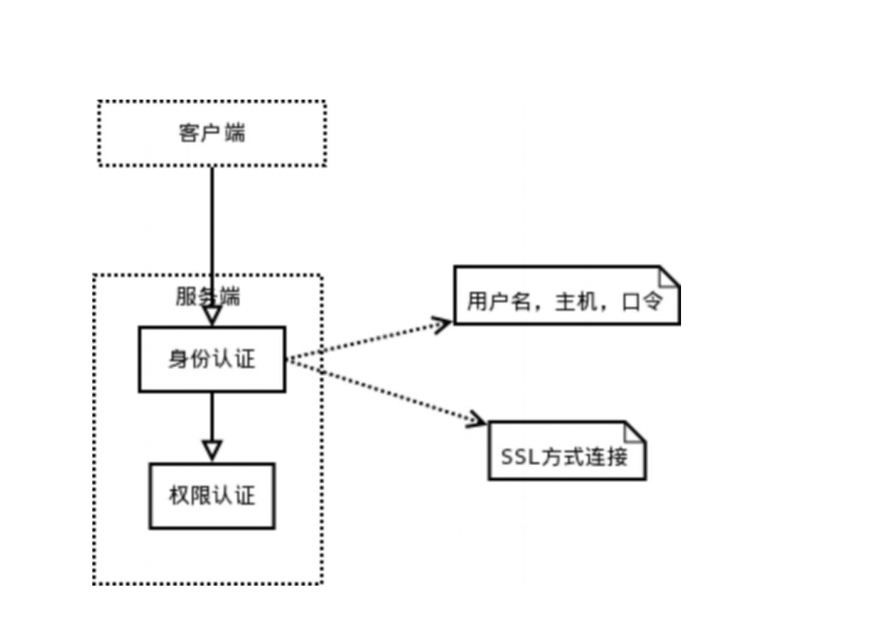
同时当客户端连接到mysql服务器时,服务器会对其进行权限验证,包括,ip,用户名,密码的验证,同时还要验证是否有对操作某一个库,表的权限。
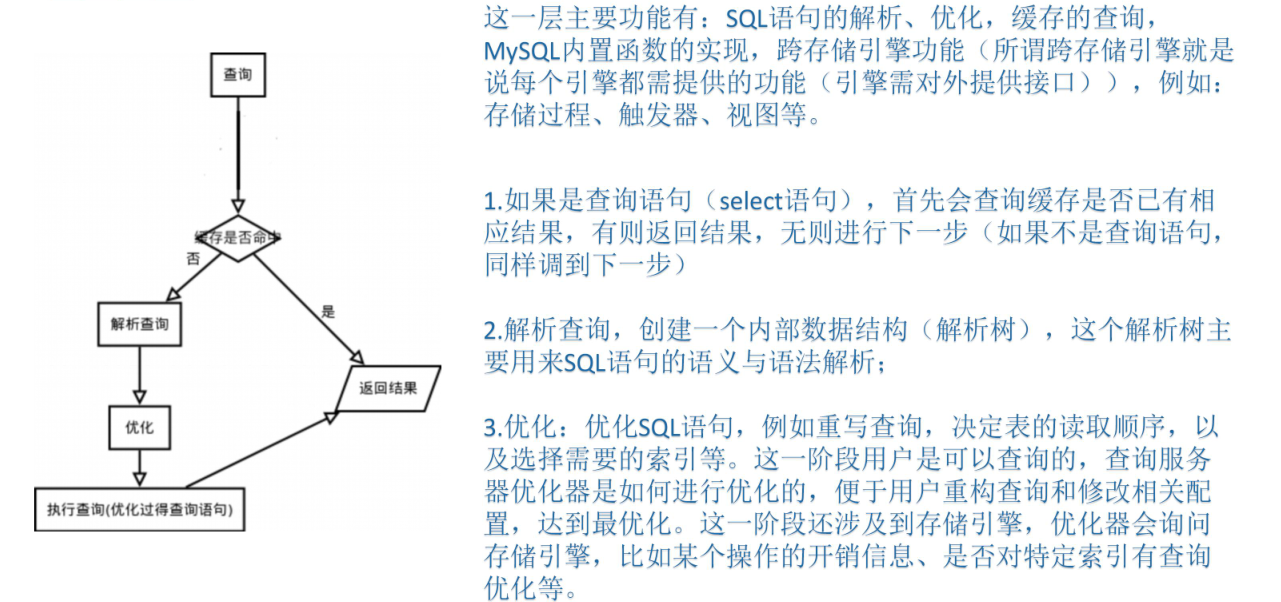
SQL处理层:
show variables like '%query_cache_type%'
SET GLOBAL query_cache_size = 188888888;
是否打开mysql查询结果缓存,默认关闭,打开后,mysql会对查询出来的结果进行缓存,实际应用中业务数据一般不在db层缓存
mysql默认打开sql解析缓存;平时我们说的sql缓存,一般指的sql解析缓存。
解析查询:

mysql对客户端传入的sql语句会按照一定的规则进行sql解析,而后进行sql优化,最后执行优化过的sql语句。而不是直接执行。
存储引擎:
show engines;查看存储引擎
MyISAM

进入show VARIABLES like 'datadir' 查看mysql数据文件所在路径,发现myisam引擎会生产三个数据文件,xxx.frm存储表结构文件,所有引擎都有此文件,xxx.MYD存储表数据文件,xxx.MYI存储表索引文件
特性:
并发性
支持表级锁,
支持全文检索,
支持数据文件压缩
试用场景:
只读类应用;
非事物行应用(数据仓库,报表,数据)
空间类应用(坐标)
Innodb

show VARIABLES like 'innodb_file_per_table' 查看innodb表空间类型
set global innodb_file_per_table=off 设置innodb使用系统表空间
mysql5.6以前默认使用系统表空间
系统表空间无法简单的收缩文件大小。
独立表空可以通过optimize table 收缩系统文件
系统表空间会产生io瓶颈
独立表空间可以同时向多个文件刷新数据
推荐使用独立表空间
特性:
Innodb是一种事务性存储引擎
完全支持事物的acid特性
redo Log和Undo Log
Innodb支持行级锁(并发度更高)
试用场景
适合大多数的oltp应用。

csv

特点:
以csv格式进行数据存储,
所有列都不能为空,
不支持索引,
可以直接对数据文件直接编辑(直接修改文本文件,达到修改表的目的)。
create table mycsv(id int not null,c1 VARCHAR(10) not null,c2 char(10) not null)
engine=csv;
insert into mycsv values(1,'aaa','bbb'),(2,'cccc','dddd');
修改文本数据
flush TABLES;
select * from mycsv
create index idx_id on mycsv(id)
应用场景:
需要频繁导入导出表数据的场景,如财务报表类
Archive

应用场景:日志以及数据采集。
Memory

show VARIABLES like 'max_heap_table_size' 查看memory引擎最大空间。

使用场景:
hash索引用于查找或者是映射表(邮编和地区对应)
用于保存数据分析中产生的中间表
用于缓存周期性聚合数据的结果表
memory数据容易丢失,所以要求数据可再生。
Ferderted
特点:提供了远程访问mysql服务器上表的方法
本地不存储数据,数据全部放到远程服务器上
本地需要保存表结构和远程服务器的连接信息
使用场景:边界数据库,表 同步
该引擎默认禁止,启用时需增加federated参数
表明,列名需要与远程表相同
CREATE TABLE `local_fed` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`c1` varchar(10) NOT NULL DEFAULT '',
`c2` char(10) NOT NULL DEFAULT '',
PRIMARY KEY (`id`)
) ENGINE=federated CONNECTION
='mysql://root:123456@127.0.0.1:3306/remote/remote_fed'
应用篇:锁,事物,索引
锁

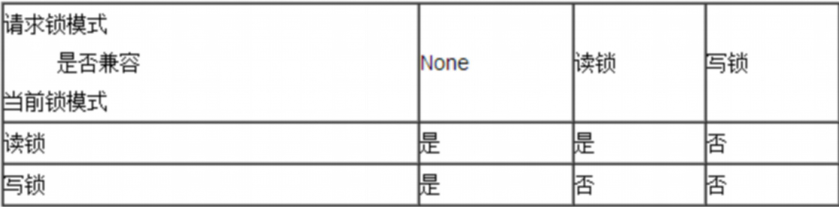
MyISAM表级锁的两种模式:table read lock 表共享读锁;table write Lock 表独占写锁;
加共享表级读锁: lock table 表名 read
1. lock table testmysam READ
启动另外一个session select * from
testmysam 可以查询
2. insert into testmysam value(2);
update testmysam set id=2 where id=1;
报错
3.在另外一个session中
insert into testmysam value(2); 等待
4.在同一个session中
insert into testdemo value(2,'2','3'); 报错
select * from testdemo ; 报错
5.在另外一个session中
insert into testdemo value(2,'2','3'); 成功
6.加锁在同一个session 中 select s.* from testmysam s 报错
lock table 表名 as 别名 read;
查看 show status LIKE 'table_locks_waited' 表被锁过几次
加独占表级写锁:lock table 表名 write
1.lock table testmysam WRITE
在同一个session中
insert testmysam value(3);
delete from testmysam where id = 3
select * from testmysam
2.对不同的表操作(报错)
select s.* from testmysam s
insert into testdemo value(2,'2','3');
3.在其他session中 (等待)
select * from testmysam

Innodb行锁
共享行锁又称读锁;当一个事务对某几行上读锁时,允许其他事务对这几行读操作,但是不予许其进行写操作,也不予许其他事务给这几行上排它锁,但允许上读锁。
排它锁又称写锁;当一个事务对某几行上写锁时,允许其他事务对这几行读操作,不予许其进行写操作,更不予许其他事务给这几行上锁,包括读锁。
注意:1.两个事务不能锁同一个索引。
2.insert,delete,update在事务中会默认加上排它锁
3.行锁必须有索引才能实现,否则会自动写全表,那么就不是行锁了

1.
BEGIN
select * from testdemo where id =1 for update
在另外一个session中
update testdemo set c1 = '1' where id = 2 成功
update testdemo set c1 = '1' where id = 1 等待
2.BEGIN
update testdemo set c1 = '1' where id = 1
在另外一个session中
update testdemo set c1 = '1' where id = 1 等待
3.
BEGIN
update testdemo set c1 = '1' where c1 = '1'
在另外一个session中
update testdemo set c1 = '2' where c1 = '2' 等待
为什么需要事务
现在的很多软件都是多用户,多程序,多线程的,对同一个表可能同时有很多人在用,为保持数据的一致性,所以提出了事务的概念。
事务的特性
事务应该具有4个属性:原子性、一致性、隔离性、持久性。这四个属性通常称为ACID特性。
原子性(atomicity)。一个事务是一个不可分割的工作单位,事务中包括的诸操作要么都做,要么都不做。
一致性(consistency)。事务必须是使数据库从一个一致性状态变到另一个一致性状态。一致性与原子性是密切相关的。
隔离性(isolation)。一个事务的执行不能被其他事务干扰。即一个事务内部的操作及使用的数据对并发的其他事务是隔离的,并发执行的各个事务之间不能互相干扰。
持久性(durability)。持久性也称永久性(permanence),指一个事务一旦提交,它对数据库中数据的改变就应该是永久性的。接下来的其他操作或故障不应该对其有任何影响。
事务隔离级别
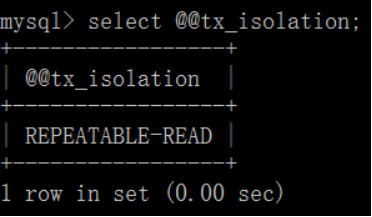
mysql默认的事务隔离级别为repeatable-read
show variables like '%tx_isolation%';
脏读:(同时操作都没提交的读取)
脏读又称无效数据读出。一个事务读取另外一个事务还没有提交的数据叫脏读。
例如:事务T1修改了一行数据,但是还没有提交,这时候事务T2读取了被事务T1修改后的数据,之后事务T1因为某种原因Rollback了,那么事务T2读取的数据就是脏的。
解决办法:把数据库的事务隔离级别调整到READ_COMMITTED
不可重复读:(同时操作,事务一分别读取事务二操作时和提交后的数据,读取的记录内容不一致)
不可重复读是指在同一个事务内,两个相同的查询返回了不同的结果。
例如:事务T1读取某一数据,事务T2读取并修改了该数据,T1为了对读取值进行检验而再次读取该数据,便得到了不同的结果。 解决办法:把数据库的事务隔离级别调整到REPEATABLE_READ
幻读:(和可重复读类似,但是事务二的数据操作仅仅是插入和删除,不是修改数据,读取的记录数量前后不一致)
例如:系统管理员A将数据库中所有学生的成绩从具体分数改为ABCDE等级,但是系统管理员B就在这个时候插入(注意时插入或者删除,不是修改))了一条具体分数的记录,当系统管理员A改结束后发现还有一条记录没有改过来,就好像发生了幻觉一样。这就叫幻读。
解决办法:把数据库的事务隔离级别调整到SERIALIZABLE_READ
未提交读(READ UNCOMMITED) 解决的障碍:无; 引入的问题:脏读
set SESSION TRANSACTION ISOLATION LEVEL READ UNCOMMITTED;
测试:
启动两个session
一个session中
start TRANSACTION
update account set balance = balance -50 where id = 1
另外一个session中查询
select * from account
回到第一个session中 回滚事务
ROLLBACK
在第二个session种
update account set balance = balance -50 where id = 1
查询结果还是 400
第二个session以为结果是350,但前面的400数据为脏读数据,导致最后的结果和意料中的结果并不一致。
已提交读 (READ COMMITED) 解决的障碍:脏读; 引入的问题:不可重复读
测试
show variables like '%tx_isolation%';
set SESSION TRANSACTION ISOLATION LEVEL read committed;
一个session中
start TRANSACTION
update account set balance = balance -50 where id = 1
另外一个session中查询 (数据并没改变)
select * from account
回到第一个session中 回滚事务
commit
在第二个session种
select * from account (数据已经改变)
可重复读(REPEATABLE READ)解决的障碍:不可重复读; 引入的问题:幻读
测试
show variables like '%tx_isolation%';
set SESSION TRANSACTION ISOLATION LEVEL repeatable read;
一个session中
start TRANSACTION
update account set balance = balance -50 where id = 1
另外一个session中查询 (数据并没改变)
select * from account
回到第一个session中 回滚事务
commit
在第二个session种
select * from account (数据并未改变)
可串行化(SERIALIZABLE)解决的障碍:可重复读; 引入的问题:锁全表,性能低下
测试
show variables like '%tx_isolation%';
set SESSION TRANSACTION ISOLATION LEVEL repeatable read;
account 表有3条记录,业务规定,最多允许4条记录。
开启一个事务
begin
select * from account 发现3条记录
开启另外一个事务
begin
select * from account 发现3条记录 也是3条记录
insert into account VALUES(4,'deer',500)
查询 4条记录
select * from account
回到第一个session
insert into account VALUES(5,'james',500)
select * from account 4条记录
session1 与 session2 都提交事务
set SESSION TRANSACTION ISOLATION LEVEL serializable; 重新上面的测试发现插入报错
总结:
事务隔离级别为可重复读时,如果有索引(包括主键索引)的时候,以索引列为条件更新数据,会存在间隙锁间、行锁、页锁的问题,从而锁住一些行;如果没有索引,更新数据时会锁住整张表
事务隔离级别为串行化时,读写数据都会锁住整张表
隔离级别越高,越能保证数据的完整性和一致性,但是对并发性能的影响也越大,对于多数应用程序,可以优先考虑把数据库系统的隔离级别设为Read Committed,它能够避免脏读取,而且具有较好的并发性能。
索引是什么
MySQL官方对索引的定义为:索引(Index)是帮助MySQL高效获取数据的数据结构。
可以得到索引的本质:索引是数据结构。
平时我们到图书馆,首先看到的都是目录,通过目录去查询想要的书籍会非常的迅速。
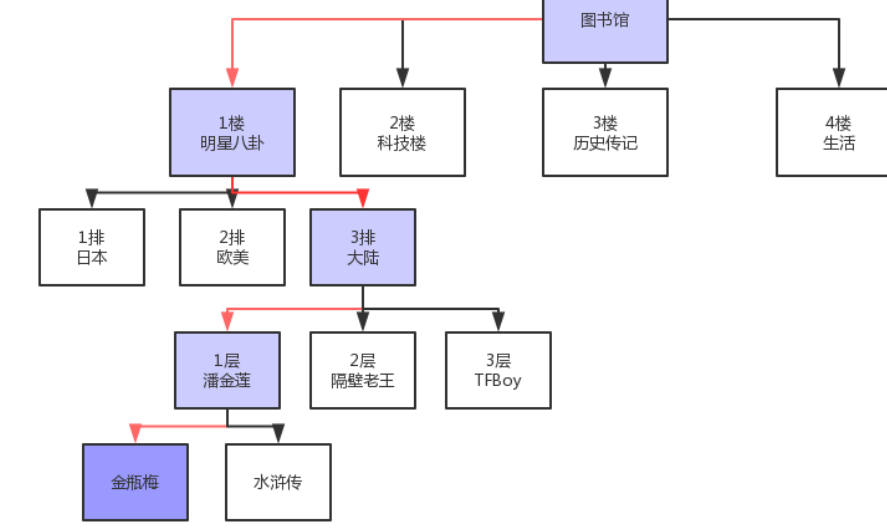
我们要去图书馆找一本书,这图书馆的书肯定不是线性存放的,它对不同的书籍内容进行了分类存放,整索引由于一个个节点组成,根节点有中间节点,中间节点下面又由子节点,最后一层是叶子节点,
可见,整个索引结构是一棵倒挂着的树,其实它就是一种数据结构,这种数据结构比前面讲到的线性目录更好的增加了查询的速度。
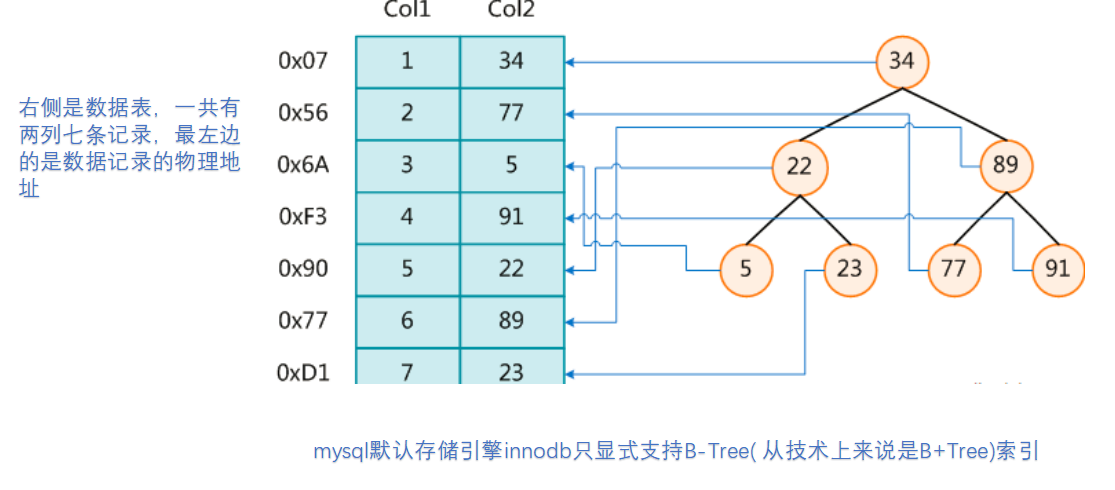
MySql中的索引其实也是这么一回事,我们可以在数据库中建立一系列的索引,比如创建主键的时候默认会创建主键索引,上图是一种BTREE的索引。每一个节点都是主键的Id
当我们通过ID来查询内容的时候,首先去查索引库,在到索引库后能快速的定位索引的具体位置。
索引得分类
普通索引:即一个索引只包含单个列,一个表可以有多个单列索引
唯一索引:索引列的值必须唯一,但允许有空值
复合索引:即一个索引包含多个列
聚簇索引(聚集索引):并不是一种单独的索引类型,而是一种数据存储方式(索引与数据放在同一个文件里)。具体细节取决于不同的实现,InnoDB的聚簇索引其实就是在同一个结构中保存了B-Tree索引(技术上来说是B+Tree)和数据行。
非聚簇索引:不是聚簇索引,就是非聚簇索引
查看索引
SHOW INDEX FROM table_name\G
创建索引
CREATE [UNIQUE ] INDEX indexName ON mytable(columnname(length));
ALTER TABLE 表名 ADD [UNIQUE ] INDEX [indexName] ON (columnname(length))
删除索引
DROP INDEX [indexName] ON mytable;
优化篇:慢查询 ,执行计划,sql优化
什么是慢查询
慢查询日志,顾名思义,就是查询慢的日志,是指mysql记录所有执行超过long_query_time参数设定的时间阈值的SQL语句的日志。该日志能为SQL语句的优化带来很好的帮助。默认情况下,慢查询日志是关闭的,要使用慢查询日志功能,首先要开启慢查询日志功能。
慢查询基本配置
slow_query_log 启动停止技术慢查询日志
slow_query_log_file 指定慢查询日志得存储路径及文件(默认和数据文件放一起)
long_query_time 指定记录慢查询日志SQL执行时间得伐值(单位:秒,默认10秒)
log_queries_not_using_indexes 是否记录未使用索引的SQL
log_output 日志存放的地方【TABLE】【FILE】【FILE,TABLE】
配置了慢查询后,它会记录符合条件的SQL
包括:
查询语句
数据修改语句
已经回滚得SQL
实操:
通过下面命令查看下上面的配置:
show VARIABLES like '%slow_query_log%'
show VARIABLES like '%slow_query_log_file%'
show VARIABLES like '%long_query_time%'
show VARIABLES like '%log_queries_not_using_indexes%'
show VARIABLES like 'log_output'
set global long_query_time=0; ---默认10秒,这里为了演示方便设置为0
set GLOBAL slow_query_log = 1; --开启慢查询日志
set global log_output='FILE,TABLE' --项目开发中日志只能记录在日志文件中,不能记表中
设置完成后,查询一些列表可以发现慢查询的日志文件里面有数据了。

慢查询解读
从慢查询日志里面摘选一条慢查询日志,数据组成如下

第一行:用户名 、用户的IP信息、线程ID号
第二行:执行花费的时间【单位:毫秒】
第三行:执行获得锁的时间
第四行:获得的结果行数
第五行:扫描的数据行数
第六行:这SQL执行的具体时间
第七行:具体的SQL语句
执行计划
使用EXPLAIN关键字可以模拟优化器执行SQL查询语句,从而知道MySQL是如何处理你的SQL语句的。分析你的查询语句或是表结构的性能瓶颈。
执行计划作用
表的读取顺序
数据读取操作的操作类型
哪些索引可以使用
哪些索引被实际使用
表之间的引用
每张表有多少行被优化器查询
执行计划的语法
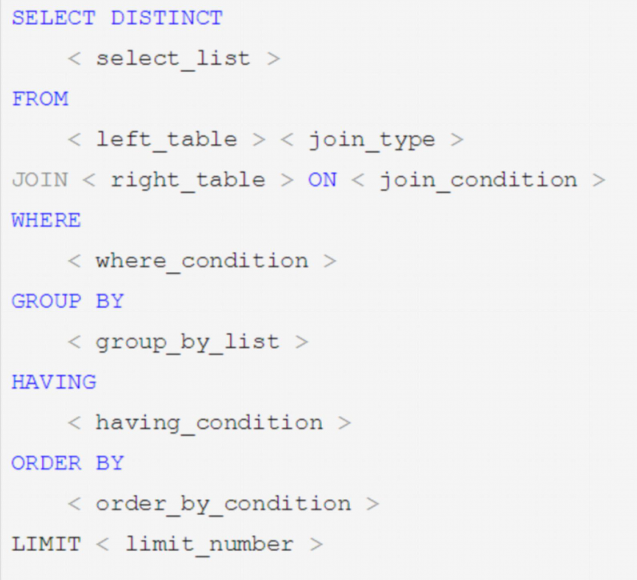
执行计划的语法其实非常简单: 在SQL查询的前面加上EXPLAIN关键字就行。
比如:EXPLAIN select * from table1
重点的就是EXPLAIN后面你要分析的SQL语句

ID列
ID列:描述select查询的序列号,包含一组数字,表示查询中执行select子句或操作表的顺序
根据ID的数值结果可以分成一下三种情况
id相同:执行顺序由上至下
id不同:如果是子查询,id的序号会递增,id值越大优先级越高,越先被执行
id相同不同:同时存在
分别举例来看

如上图所示,ID列的值全为1,代表执行的允许从t1开始加载,依次为t3与t2
EXPLAIN
select t2.* from t1,t2,t3 where t1.id = t2.id and t1.id = t3.id
and t1.other_column = '';
Id不同


如果是子查询,id的序号会递增,id值越大优先级越高,越先被执行
EXPLAIN
select t2.* from t2 where id = (
select id from t1 where id = (select t3.id from t3 where t3.other_column='')
);
Id相同又不同

id如果相同,可以认为是一组,从上往下顺序执行;
在所有组中,id值越大,优先级越高,越先执行
EXPLAIN
select t2.* from (
select t3.id
from t3 where t3.other_column = ''
) s1 ,t2 where s1.id = t2.id
select_type列
Select_type:查询的类型,
要是用于区别:普通查询、联合查询、子查询等的复杂查询
类型如下

SIMPLE
EXPLAIN select * from t1
简单的 select 查询,查询中不包含子查询或者UNION

PRIMARY与SUBQUERY
PRIMARY:查询中若包含任何复杂的子部分,最外层查询则被标记为
SUBQUERY:在SELECT或WHERE列表中包含了子查询
EXPLAIN
select t1.*,(select t2.id from t2 where t2.id = 1 ) from t1

DERIVED
在FROM列表中包含的子查询被标记为DERIVED(衍生)
MySQL会递归执行这些子查询, 把结果放在临时表里。

.UNION RESULT 与UNION
UNION:若第二个SELECT出现在UNION之后,则被标记为UNION;
UNION RESULT:从UNION表获取结果的SELECT
#UNION RESULT ,UNION
EXPLAIN
select * from t1
UNION
select * from t2

table列
显示这一行的数据是关于哪张表的

Type列
type显示的是访问类型,是较为重要的一个指标,结果值从最好到最坏依次是:
system > const > eq_ref > ref > fulltext > ref_or_null > index_merge > unique_subquery > index_subquery > range > index > ALL
需要记忆的
system>const>eq_ref>ref>range>index>ALL
一般来说,得保证查询至少达到range级别,最好能达到ref。
System与const
System:表只有一行记录(等于系统表),这是const类型的特列,平时不会出现,这个也可以忽略不计
Const:表示通过索引一次就找到了
const用于比较primary key或者unique索引。因为只匹配一行数据,所以很快
如将主键置于where列表中,MySQL就能将该查询转换为一个常量

eq_ref
唯一性索引扫描,对于每个索引键,表中只有一条记录与之匹配。常见于主键或唯一索引扫描

Ref
非唯一性索引扫描,返回匹配某个单独值的所有行.
本质上也是一种索引访问,它返回所有匹配某个单独值的行,然而,它可能会找到多个符合条件的行,所以他应该属于查找和扫描的混合体

Range
只检索给定范围的行,使用一个索引来选择行。key 列显示使用了哪个索引
一般就是在你的where语句中出现了between、<、>、in等的查询
这种范围扫描索引扫描比全表扫描要好,因为它只需要开始于索引的某一点,而结束语另一点,不用扫描全部索引。

Index
当查询的结果全为索引列的时候,虽然也是全部扫描,但是只查询的索引库,而没有去查询
数据。

All
Full Table Scan,将遍历全表以找到匹配的行

possible_keys 与Key
possible_keys:可能使用的key
Key:实际使用的索引。如果为NULL,则没有使用索引
查询中若使用了覆盖索引,则该索引和查询的select字段重叠

key_len
Key_len表示索引中使用的字节数,可通过该列计算查询中使用的索引的长度。在不损失精确性的情况下,长度越短越好
key_len显示的值为索引字段的最大可能长度,并非实际使用长度,即key_len是根据表定义计算而得,不是通过表内检索出的

key_len表示索引使用的字节数,
根据这个值,就可以判断索引使用情况,特别是在组合索引的时候,判断所有的索引字段是否都被查询用到。
char和varchar跟字符编码也有密切的联系,
latin1占用1个字节,gbk占用2个字节,utf8占用3个字节。(不同字符编码占用的存储空间不同)

字符类型

字符类型-索引字段为char类型+不可为Null时

name这一列为char(10),字符集为utf-8占用3个字节Keylen=10*3
字符类型-索引字段为char类型+允许为Null时

name这一列为char(10),字符集为utf-8占用3个字节,外加需要存入一个null值
Keylen=10*3+1(null) 结果为31
索引字段为varchar类型+不可为Null时

Keylen=varchar(n)变长字段+不允许Null=n*(utf8=3,gbk=2,latin1=1)+2
索引字段为varchar类型+允许为Null时

Keylen=varchar(n)变长字段+允许Null=n*(utf8=3,gbk=2,latin1=1)+1(NULL)+2
总结
字符类型
变长字段需要额外的2个字节(VARCHAR值保存时只保存需要的字符数,另加一个字节来记录长度(如果列声明的长度超过255,则使用两个字节),所以VARCAHR索引长度计算时候要加2),固定长度字段不需要额外的字节。
而NULL都需要1个字节的额外空间,所以索引字段最好不要为NULL,因为NULL让统计更加复杂并且需要额外的存储空间。
复合索引有最左前缀的特性,如果复合索引能全部使用上,则是复合索引字段的索引长度之和,这也可以用来判定复合索引是否部分使用,还是全部使用。
整数/浮点数/时间类型的索引长度
NOT NULL=字段本身的字段长度
NULL=字段本身的字段长度+1(因为需要有是否为空的标记,这个标记需要占用1个字节)
datetime类型在5.6中字段长度是5个字节,datetime类型在5.5中字段长度是8个字节
Ref
显示索引的哪一列被使用了,如果可能的话,是一个常数。哪些列或常量被用于查找索引列上的值

由key_len可知t1表的idx_col1_col2被充分使用,col1匹配t2表的col1,col2匹配了一个常量,即 'ac'
其中 【shared.t2.col1】 为 【数据库.表.列】
Rows
根据表统计信息及索引选用情况,大致估算出找到所需的记录所需要读取的行数

Extra
包含不适合在其他列中显示但十分重要的额外信息。

Using filesort
说明mysql会对数据使用一个外部的索引排序,而不是按照表内的索引顺序进行读取。MySQL中无法利用索引完成的排序操作称为“文件排序”
当发现有Using filesort 后,实际上就是发现了可以优化的地方

上图其实是一种索引失效的情况,后面会讲,可以看出查询中用到了个联合索引,索引分别为col1,col2,col3

当我排序新增了个col2,发现using filesort 就没有了。
Using temporary
使了用临时表保存中间结果,MySQL在对查询结果排序时使用临时表。常见于排序 order by 和分组查询 group by。


尤其发现在执行计划里面有using filesort而且还有Using temporary的时候,特别需要注意
Using index
表示相应的select操作中使用了覆盖索引(Covering Index),避免访问了表的数据行,效率不错!
如果同时出现using where,表明索引被用来执行索引键值的查找;

如果没有同时出现using where,表明索引用来读取数据而非执行查找动作

覆盖索引:
覆盖索引(Covering Index),一说为索引覆盖。
理解方式一:就是select的数据列只用从索引中就能够取得,不必读取数据行,MySQL可以利用索引返回select列表中的字段,而不必根据索引再次读取数据文件,换句话说查询列要被所建的索引覆盖。
理解方式二:索引是高效找到行的一个方法,但是一般数据库也能使用索引找到一个列的数据,因此它不必读取整个行。毕竟索引叶子节点存储了它们索引的数据;当能通过读取索引就可以得到想要的数据,那就不需要读取行了。一个索引包含了(或覆盖了)满足查询结果的数据就叫做覆盖索引
注意:
如果要使用覆盖索引,一定要注意select列表中只取出需要的列,不可select *,
因为如果将所有字段一起做索引会导致索引文件过大,查询性能下降。
所以,千万不能为了查询而在所有列上都建立索引,会严重影响修改维护的性能。
Using where 与 using join buffer
Using where
表明使用了where过滤
using join buffer
使用了连接缓存:

impossible where
where子句的值总是false,不能用来获取任何元组

sql优化顺口溜
全职匹配我最爱,最左前缀要遵守;
带头大哥不能死,中间兄弟不能断;
索引列上少计算,范围之后全失效;
LIKE百分写最右,覆盖索引不写*;
全职匹配我最爱?

当建立了索引列后,能在where条件中使用索引的尽量所用。
最左前缀要遵守,带头大哥不能死,中间兄弟不能断?

如果索引了多列,要遵守最左前缀法则。指的是查询从索引的最左前列开始并且不跳过索引中的列。
联合索引index(name,age,pos),带头大哥name,少了索引直接失效,使用(name,pos)丢下中间兄弟age索引失效。
索引列上少计算?

不在索引列上做任何操作(计算、函数、(自动or手动)类型转换),会导致索引失效而转向全表扫描
范围之后全失效?
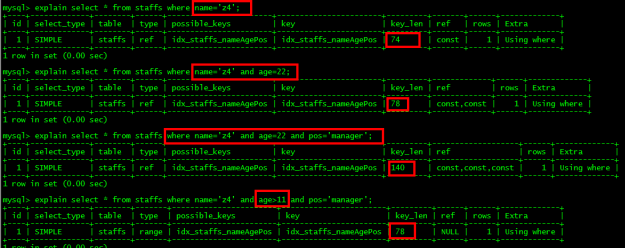
中间有范围查询会导致后面的索引列全部失效
EXPLAIN SELECT * FROM staffs WHERE NAME = 'July' and age >22 and pos='manager'
LIKE百分写最右?
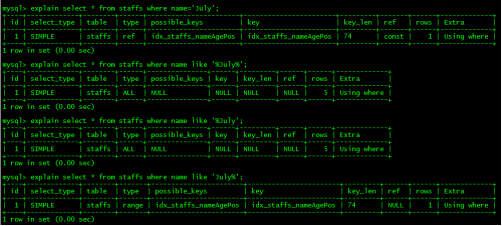
like以通配符开头('%abc...')mysql索引失效会变成全表扫描的操作
解决方式:覆盖索引
EXPLAIN select name,age,pos from staffs where name like '%july%'
覆盖索引不写* ?
使用select * from 破坏了了覆盖索引的使用条件。
补充两个比较偏的
Null/Not 有影响
索引不可为空

在字段为not null的情况下,使用is null 或 is not null 会导致索引失效
解决方式:覆盖索引
EXPLAIN select name,age,pos from staffs where name is not null
索引可为空:


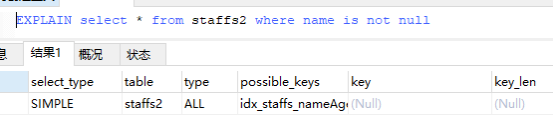
Is not null 的情况会导致索引失效

