grep与正则表达式基础
目录
grep
正则表达式
grep用法简介
我们介绍GREP的用法,主要用于匹配行,我们借助下面的正则表达式来介绍如何使用grep,还有就是正则表达式在linux中是极为重要的一部分。
1 命令:grep 2 格式:grep [option] "pattern" filename 3 选项: 4 -v:反向选择 5 -i:忽略大小写 6 -n:显示行号 7 -c:统计行数 8 -o:仅显示匹配到的字符串 9 -w:匹配整个单词 10 -q:不输出任何信息 11 -A 2:after 显示后2行 12 -B 3:before 显示前3行 13 -C 3:context 前后各3行 14 -e:实现多个选项间的逻辑关系 15 grep -e root -e mail /etc/passwd 16 -E:相当于egrep,用于使用拓展的正则表达式 17 -F:相当于fgrep,不支持正则表达式
正则表达式(Regular expression)
什么是正则表达式
Regular expression(正则表达式)是由一类特殊字符及文本字符编写的模式,其中有些字符(元字符)不代表字符的字面意义,而表示控制或通配功能。
那些程序支持正则表达式
grep,sed,awk,vim,less,nginx,varnish
在man中查询
我们可以在正则man手册中查找正则的用法
man 7 regex
正则表达式的分类
基本正则表达式
扩展的正则表达式
元字符的分类
字符匹配,匹配次数,位置锚定,分组
基础RE(用于grep)
字符匹配
1 . 匹配任意单个字符 2 [] 匹配指定范围内的任意单个字符 3 [^] 匹配指定范围外的任意字符
匹配次数:用在要指定的次数的字符后面,用于指定前面的字符出现的次数
1 * 匹配前面的字符任意次(包括0次) 2 .* 任意长度的任意字符 3 \? 匹配前面的字符0次或一次 4 \+ 匹配前面的字符至少一次 5 \{n\} 匹配前面的字符n次 6 \{m,n\} 匹配前面的字符至少m次,最多n次 7 \{,n\} 匹配前面的字符最多n次 8 \{n,\} 匹配前面的字符最少n次
位置锚定:用于定位出现的位置
1 ^ 行首锚定 2 $ 行尾锚定 3 ^$ 空行 4 ^[[:space:]]$ 空白行 5 \<,\b 词首锚定,用于单词模式的左侧 6 \>,\b 词尾锚定,用于单词模式的右侧 7 \<pattern\> 匹配整个单词
分组:
\(\)将一个或多个字符捆绑在一起,当做一个整体进行处理,如\(root\)\+
分组括号中的模式匹配到的内容会被正则表达式引擎记录在内部的变量中,这些变量的命令方式为\1,\2,\3...
\1 表示从左侧起第一个左括号以及与之匹配的右括号之间的模式所匹配到的字符
示例:
\(string1\+\(string2\)*\)
\1:string1\+\(string2\)*
\2:string2
后向引用:
引用前面的分组括号中的模式所匹配的字符,而非模式本身
或者:\|
扩展RE(用于egrep或grep —E)
字符匹配:
1 . 匹配任意单个字符 2 [] 匹配指定范围内的任意单个字符 3 [^] 匹配指定范围外的任意字符
匹配次数
1 * 匹配前面的字符任意次(包括0次) 2 ? 匹配前面的字符0次或一次 3 + 匹配前面的字符至少一次 4 {n} 匹配前面的字符n次 5 {m,n} 匹配前面的字符至少m次,最多n次
位置锚定
1 ^ : 行首 2 $ : 行尾 3 \<, \b : 语首 4 \>, \b : 语尾
分组:
1 () 2 后向引用: \1, \2, ...
或者:
1 a|b: a或b 2 C|cat: C或cat 3 (C|c)at:Cat或cat
特殊字符
[:alnum:] 字母和数字
[:alpha:] 代表任何英文大小写字符,亦即 A-Z, a-z
[:lower:] 小写字母
[:upper:] 大写字母
[:blank:] 水平空白字符(空格和制表符)
[:space:] 所有水平和垂直的空白字符(比[:blank:]包含的范围广)
[:cntrl:] 不可打印的控制字符(退格、删除、警铃...)
[:digit:] 十进制数字
[:graph:] 可打印的非空白字符
[:print:] 可打印字符
[:punct:] 标点符号
[:xdigit:] 十六进制数字
grep
1、显示/proc/meminfo文件中以大小s开头的行(要求:使用两种方法)
cat /proc/meminfo | grep "^[sS]" cat /proc/meminfo | grep "^[s\|S]" cat /proc/meminfo | grep "^s\|^S"
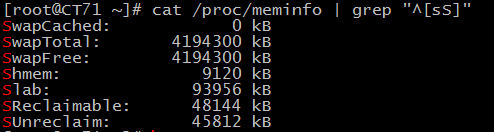
2、显示/etc/passwd文件中不以/bin/bash结尾的行
cat /etc/passwd | grep -v "/bin/bash$"

3、显示用户rpc默认的shell程序
cat /etc/passwd | grep "^rpc\>" | grep -o "[^/]\+$" cat /etc/passwd | grep "^rpc\>" | cut -d"/" -f6

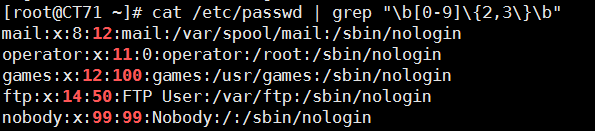
4、找出/etc/passwd中的两位或三位数
cat /etc/passwd | grep "\b[0-9]\{2,3\}\b"
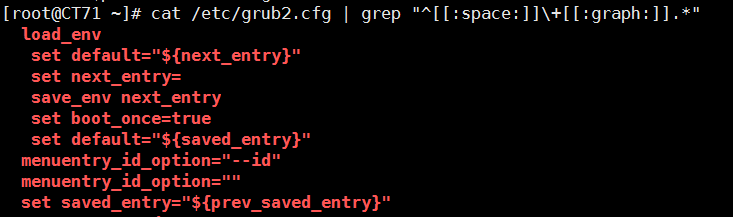
5、显示CentOS7的/etc/grub2.cfg文件中,至少以一个空白字符开头的且后面存非空白 字符的行
cat grub2.txt | grep "^[[:space:]]\+[[:graph:]].*"
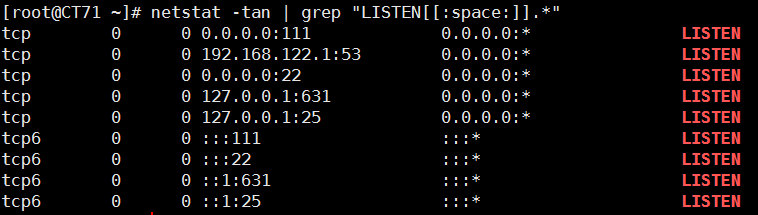
6、找出“netstat -tan”命令的结果中以‘LISTEN’后跟任意多个空白字符结尾的行
netstat -tan | grep "LISTEN[[:space:]]*$"
7、显示CentOS7上所有系统用户的用户名和UID
cat /etc/passwd | cut -d ":" -f 1,3 | grep -v "\b0$" | grep "\b[0-9]\{1,3\}\b"
cat /etc/passwd | cut -d ":" -f 1,3 | grep -ve "\b0$" -e "[0-9]\{4,\}"

8、添加用户bash、 testbash、 basher、 sh、 nologin(其shell为/sbin/nologin),找出 /etc/passwd用户名同shell名的行
cat /etc/passwd | grep "\(^[[:alnum:]]\+\>\).*\<\1$"

9、利用df和grep及sort,取出磁盘各分区利用率,并从大到小排序
df | grep "/dev/sd" | grep -o "[0-9]\{1,\}%" | sort -nr

egrep
1、显示三个用户root、 mage、 wang的UID和默认shell
cat /etc/passwd | egrep "^root|^mage|^wang" | tr -s ":" "/" | cut -d"/" -f3,8 cat /etc/passwd | egrep "^root|^mage|^wang" | cut -d":" -f3,7

2、找出/etc/rc.d/init.d/functions文件中行首为某单词(包括下划线)后面跟一个小括号的行
cat /etc/rc.d/init.d/functions | egrep -o "^([[:alpha:]]+|_).*[[:graph:]]\(\)" cat /etc/rc.d/init.d/functions | egrep -o "^.*[[:grpha:]]\(\)" cat /etc/rc.d/init.d/functions |egrep -o "^.*\>\(\)"
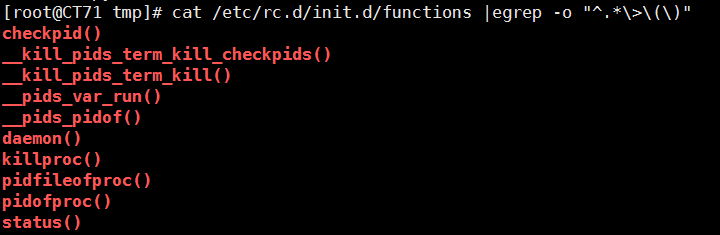
3、使用egrep取出/etc/rc.d/init.d/functions中其基名
echo /etc/rc.d/init.d/functions | egrep -o "\b[[:alnum:]]+/*$" echo /etc/rc.d/init.d/functions | egrep -o "\b[[:alnum:]]+/?$" echo /etc/rc.d/init.d/functions |egrep "[^/]+/?$" -o

4、使用egrep取出上面路径的目录名
echo /etc/rc.d/init.d/functions | egrep -o ".*/\<" echo /etc/rc.d/init.d/functions |egrep -o ".*/." |egrep -o

5、统计last命令中以root登录的每个主机IP地址登录次数
last | grep ^root | egrep -o "([0-9]{1,3}\.){3}[0-9]{1,3}" | sort | uniq -c

6、利用扩展正则表达式分别表示0-9、 10-99、 100-199、200-249、 250-255
echo {1..1000} | egrep -o "\b[0-9]\b" | tr "\n" " " ;echo
echo {1..1000} | egrep -o "\b[0-9]{2}\b" | tr "\n" " " ;echo
echo {1..1000} | egrep -o "\b1[0-9]{2}\b" | tr "\n" " " ;echo
echo {1..1000} | egrep -o "\b2[0-4][0-9]\b" | tr "\n" " " ;echo
echo {1..1000} | egrep -o "\b25[0-5]\b" | tr "\n" " " ;echo

7、显示ifconfig命令结果中所有IPv4地址
ifconfig|egrep -o "\<(([0-9]|[1-9][0-9]|1[0-9]{2}|2[0-4]0-9]|25[0-5])\.){3}([0-9]|[1-9][0-9]|1[0-9]{2}|2[0-4][0-9]|25[0-5])\>"

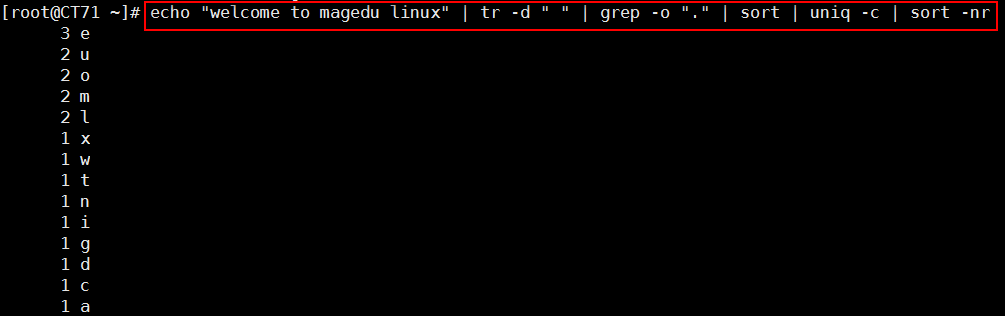
8、将此字符串: welcome to magedu linux 中的每个字符去重并排序,重复次数多的排到前面
echo "welcome to magedu linux" | tr -d " " | grep -o "." | sort | uniq -c | sort -nr

 浙公网安备 33010602011771号
浙公网安备 33010602011771号