

2.1 解压Hadop包
2.2 配置hadoop-env.sh文件
[root@master ~]# cd /usr/local
[root@master local]# tar xf hadoop-3.2.0.tar.gz
[root@master local]# mv hadoop-3.2.0 hadoop
[root@master local]# cd hadoop
[root@master hadoop]# vim etc/hadoop/hadoop-env.sh
修改:
export JAVA_HOME=/usr/local/jdk
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export HADOOP_SECURE_DN_USER=yarn
export YARN_NODEMANAGER_USER=root
2.3 配置core-site.xml文件
[root@master hadoop]# vim etc/hadoop/core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9820</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:///usr/local/hadoop/tmp</value>
</property>
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>
</configuration>
2.4 配置hdfs-site.xml文件
[root@master hadoop]# vim etc/hadoop/hdfs-site.xml
<configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop/dfs/data</value>
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>master:9868</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
</configuration>
2.5 配置slave文件
[root@master hadoop]# vim etc/hadoop/workers
添加:
master
slave1
slave2
2.6 将master节点配置同步其他主机
scp -rp /usr/local/hadoop/ slave1:/usr/local/
scp -rp /usr/local/hadoop/ slave2:/usr/local/
scp -rp /usr/local/hadoop/ slave3:/usr/local/
2.7 修改环境配置文件
vim /etc/profile
添加:
#Hadoop Environment Variables
export HADOOP_HOME=/usr/local/hadoop
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
export LD_LIBRARY_PATH=$HADOOP_HOME/lib/native
#mysql
export PATH=$PATH:/usr/local/mysql-5.6/bin
#hive
export HIVE_HOME=/usr/local/hive
export PATH=$PATH:$HIVE_HOME/bin
#spark
export SPARK_HOME=/usr/local/spark
export PATH=${SPARK_HOME}/bin:$PATH
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export JAVA_LIBRARY_PATH=$HADOOP_HOME/lib/native
#zookeeper
export PATH=$PATH:/usr/local/zookeeper/bin
#scala
export SCALA_HOME=/usr/local/scala
export PATH=${SCALA_HOME}/bin:$PATH
[root@master ~]# scp -rp /etc/profile slave1:/etc/profile
[root@master ~]# scp -rp /etc/profile slave2:/etc/profile
2.8 格式化hdfs文件系统
[root@master ~]# hdfs namenode -format
格式化hdfs的namenode节点,产生定义的hdfs_tmp目录
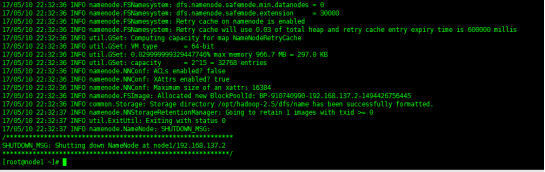
查看是否生成fsimage文件,验证hdfs格式化是否成功

2.9 启动hadoop集群
[root@master ~]# start-dfs.sh
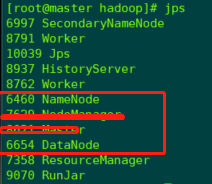
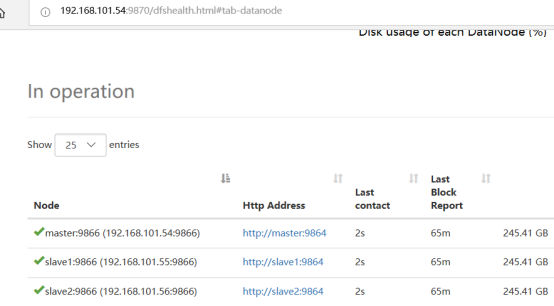
2.10 验证hadoop集群
登录http://192.168.101.54:9870
2.11 关闭hadoop集群
[root@master ~]# stop-dfs.sh
注意yarn服务需要运行zookeeper。

