TensorFlow-谷歌深度学习库 性能优化防拟合
Stochatic Gradient Descent (S.G.D)
思想:每次从数据集中随机抽取子样本(1 ~ 1000),在子样本中应用梯度下降。
假设每次的子样本都可以很好的代表整体,假设每次猜到的梯度下降的方向是对的,迭代操作直到我们得到结果。
批量梯度下降算法每次都会使用全部训练样本,因此这些计算是冗余的,因为每次都使用完全相同的样本集。而随机梯度下降算法每次只随机选择一个样本来更新模型参数,因此每次的学习是非常快速的,并且可以进行在线更新。
因为计算得到的并不是准确的一个梯度,对于最优化问题,凸问题,虽然不是每次迭代得到的损失函数都向着全局最优方向, 但是大的整体的方向是向全局最优解的,最终的结果往往是在全局最优解附近。但是相比于批量梯度,这样的方法更快,更快收敛,虽然不是全局最优,但很多时候是我们可以接受的作者:Evan链接:https://www.zhihu.com/question/264189719/answer/291167114来源:知乎著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。

让每一次的计算变得很便宜很迅速,不过要以迭代更多次为代价。
非线性方程 | 激励函数ReLu
神经网络
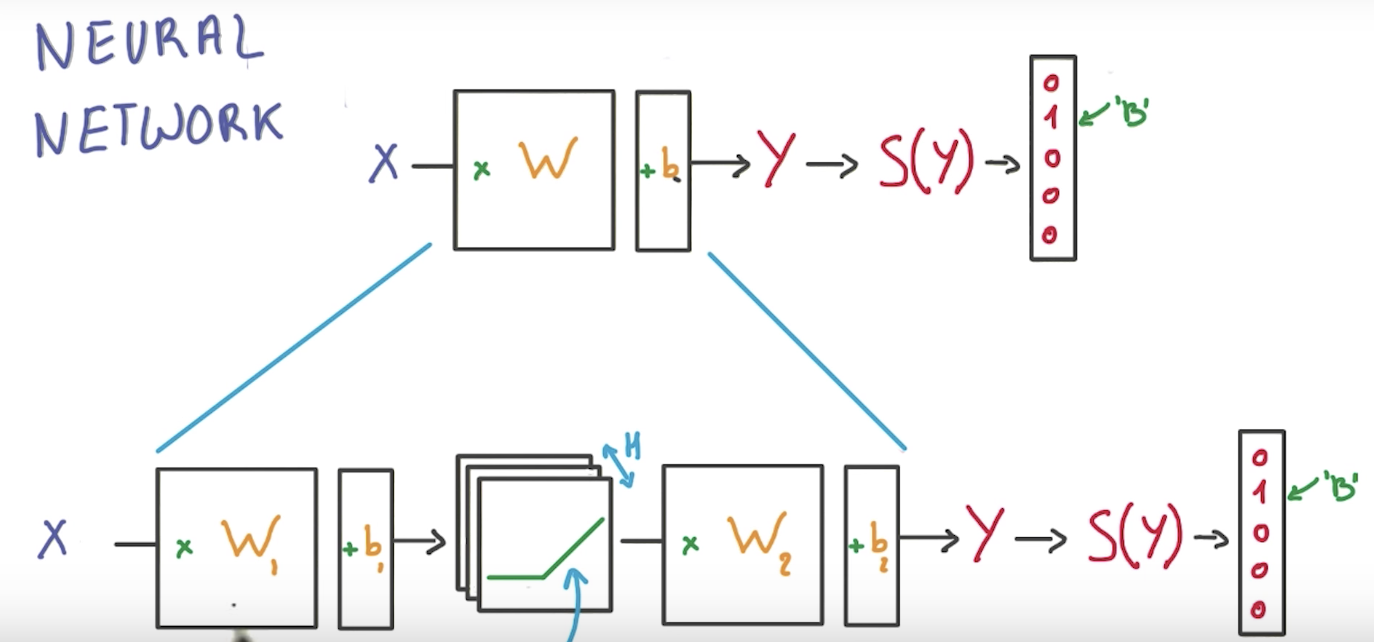
在中间加入激活函数使原先的线性方程转变为非线性方程

如果不用激励函数,每一层输出都是上层输入的线性函数,无论神经网络有多少层,输出都是输入的线性组合。
如果使用的话,激活函数给神经元引入了非线性因素,使得神经网络可以任意逼近任何非线性函数,这样神经网络就可以应用到众多的非线性模型中。
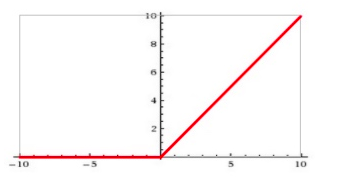
ReLu激活函数
Rectified Linear Unit(ReLU) - 用于隐层神经元输出

多层神经网络的back propagation算法
它就是复合函数的链式法则!

需要找到从q节点到p节点的所有路径,并且对每条路径,求得该路径上的所有偏导数之乘积,然后将所有路径的 “乘积” 累加起来才能得到的值。

使用regularization去避免overfiting的问题
early termination:在性能达到最优时停止训练。即在模型对训练数据集迭代收敛之前停止迭代来防止过拟合。
l2正规化:每个参数的平方
l1正规化:每个参数的绝对值
新的loss为原有loss加上一个惩罚度, 过度依赖的 W , 也就是训练参数的数值会很大, l1, l2会惩罚这些大的

l2_loss(t, name=None)
loss += reg * (tf.nn.l2_loss(weights) + tf.nn.l2_loss(weights2)) #两层layer的正规化
dropout
我们随机忽略掉一些神经元和神经联结 , 是这个神经网络变得”不完整”. 用一个不完整的神经网络训练一次.
到第二次再随机忽略另一些, 变成另一个不完整的神经网络.
Dropout 的做法是从根本上让神经网络没机会过度依赖某个w。
dropout(x, keep_prob, noise_shape=None, seed=None, name=None)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号