
202103226-1 编程作业
第二周作业
|这个作业属于哪个课程 |https://edu.cnblogs.com/campus/zswxy/computer-science-class3-2018/|
|这个作业要求在哪里 |https://edu.cnblogs.com/campus/zswxy/computer-science-class3-2018/homework/11879|
|这个作业的目标 |初步学会码云和Github、git的使用以及通过工程软件进行编程|
|学号 | 20188468|
码云仓库地址:https://gitee.com/duwei3414664176/project-java
1、PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 45 | 30 |
| • Estimate | • 估计这个任务需要多少时间 | 1300 | 1200 |
| Development | 开发 | 900 | 600 |
| • Analysis | • 需求分析 (包括学习新技术) | 300 | 200 |
| • Design Spec | • 生成设计文档 | 150 | 100 |
| • Design Review | • 设计复审 | 50 | 50 |
| • Coding Standard | • 代码规范 (为目前的开发制定合适的规范) | 30 | 20 |
| • Design | • 具体设计 | 20 | 50 |
| • Coding | • 具体编码 | 10 | 10 |
| • Code Review | • 代码复审 | 150 | 200 |
| • Test | • 测试(自我测试,修改代码,提交修改) | 90 | 200 |
| Reporting | 报告 | 20 | 20 |
| • Test Repor | • 测试报告 | 20 | 30 |
| • Size Measurement | • 计算工作量 | 20 | 20 |
| • Postmortem & Process Improvement Plan | • 事后总结, 并提出过程改进计划 | 20 | 10 |
| 合计 | 3425 | 2730 |
2.
功能需求分析
-
1.读取文件,将文件内容。
-
2.统计文件内容,含有多少个ASCII码。
-
3.将文件内容按行分割,并且统计行数。
-
4.找出文件中的单词,并且统计其出现频率。
-
5.将结果输出至对应的输出文件。
初步分析设计
-
1.首先对于文件读写,我直接选用BufferedReader和BufferedWriter 较普通的输入输出流有较好的性能。
-
2.对于读入文件的方式,我的设计是直接使用BufferedReader.read()方法按字符读取,然后拼合成一个字符串进行处理。
-
3.将文件分割直接使用乐String自带的String.split()方法。然后对结果集中的每一个对象使用trim()方法将空白字符去掉再判断是否是空行。这样就统计出了非空行的数目。
-
4.最后就是单词的统计,我对于每行都使用正则表达式取出有效的单词,然后将单词加入hashmap统计个数。
-
5.最后使用优先队列对hashmap中的单词按照其出现次数排序,取出出现次数最多的10个单词。
-
6.向文件写出结果。
3.正文
读取文件模块
public class FileTool { public BufferedReader InputReader; public BufferedWriter OutputWriter; BufferedReader getReader(String filePath) BufferedWriter getWriter(String filePath) boolean closeReader() boolean closeWriter() String getFileString() public void writeResult(int CharNums, int RowNums, int WordNums, ArrayList<Map.Entry<String, Integer>> TopList)//输出结果 }
计算模块
public class ComputeTool { private String TargetString; private ArrayList<String> Rows; private ArrayList<String> ValidRows; private ConcurrentHashMap<String, Integer> ValidWords; public int RowNums; public int CharNums; public int WordNums; public ArrayList<Map.Entry<String, Integer>> TopList; public ComputeTool(String TargetString)
{this.TargetString=TargetString; } private int countCharNums()//计算字符数 private int countRowNums()//计算行数 private int countWordTypeNums()//计算单词种类数量 private int CountWordNums(int k)//计算单词出现次数 public void compute() }
根据需求分析我们可知需要三个功能就可以得到答案
- 1.统计文件内容,含有多少个ASCII码。
- 2.将文件内容按行分割,并且统计行数。
- 3.找出文件中的单词,并且统计其出现频率
计算字符数
首先是计算字符数的模块,因为我们已经把整个文件的内容存入了一个字符串,所以只需要返回字符串的长度就可以得到整个文件的字符数
private int countCharNums() { return TargetString.length(); }
计算行数
private int countRowNums() { Rows =new ArrayList<String>(Arrays.asList(TargetString.split("\n"))); ValidRows =new ArrayList<String>(); for (String Row:Rows) { if(!(Row.trim().isEmpty())) ValidRows.add(Row); } return ValidRows.size(); }
字符串的处理(分割字符串),并计算单词数
public void addList(String srl) { //string from readline 将判定为的单词放入List中 srl = srl.trim(); //String[] wordArray = srl.split("[a-zA-Z]{4}([a-zA-Z0-9])*"); //String[] wordArray = srl.split("[0-9A-Za-z]+"); String [] wordArray = srl.split("\\W+"); Pattern p = Pattern.compile("[a-zA-Z]{4}([a-zA-Z0-9])*"); for (String listWord : wordArray) { Matcher m = p.matcher(listWord); if (listWord.length() != 0 && m.find()) { list.add(listWord); wordNum++; } } }
将分割好的字符串,送去map中并进行排序,从排好序的map取出词频高的词和频分别存取
public void addMap() { //将筛选好的单词放入map中,若存在则value+1,不存在则设value=1 for (String mapWord : list) { if(map.get(mapWord) != null) { map.put(mapWord, map.get(mapWord) + 1); }else{ map.put(mapWord,1); } //System.ot.println(mapWord); } //mapSort(map); }
public void mapSort(Map<String,Integer> oldmap){ //定义比较器根据value的值降序排列 ArrayList<Map.Entry<String, Integer>> newList = new ArrayList<>(oldmap.entrySet()); Collections.sort(newList, new Comparator<>() { @Override public int compare(Map.Entry<String, Integer> o1, Map.Entry<String, Integer> o2) { return o2.getValue() - o1.getValue();//降序 } }); for (int i = 0; i < (newList.size() > 10 ? 10 : newList.size()); i++) { wordSet[i] = newList.get(i).getKey(); freSet[i] = newList.get(i).getValue(); } }
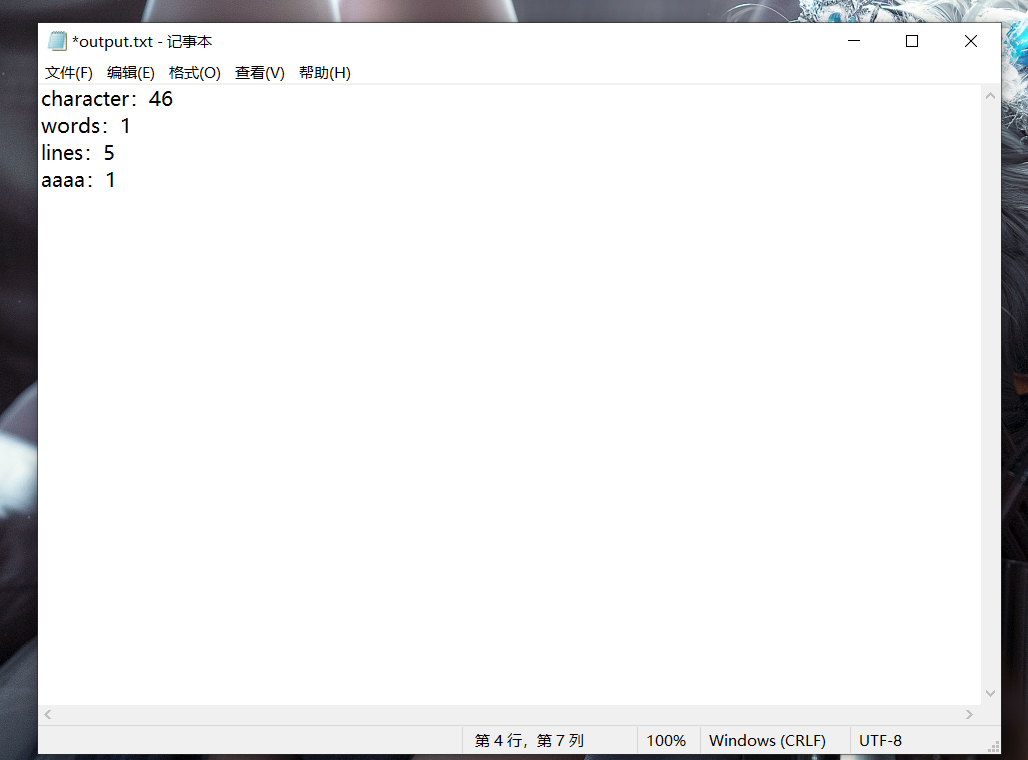
运行截图
心得体会:
对于GitHub的感觉其实一开始是有点抗拒的,曾经使用过一次因为没有深入的理解导致那次使用给我感觉特别不好,这次了解以后才真正明白GitHub对于项目的管理是多么的好用!
然后就是刚开始看到这些题目要求的时候,其实是傻眼的,然后通过慢慢问同学和老师,结合上课的知识一步步去解决这些问题,最后完成的时候成就感还是很足的。
至于PSP表格,第一次做的话时间的估计我感觉应该是特别不准确的,没想到后来出入也不是特别大,所以PSP计划时间基本上都是凭感觉瞎写的。

