MIT 6.042J学习简要笔记
证明
归纳法模板
命题:对于所有自然数 n(通常是正整数),命题 P(n) 成立。
证明:
- 基础步骤:首先证明命题在 n=1(或其他适当的起始值)时成立。 (明确表达命题在起始值上的成立情况)
- 归纳步骤:假设命题在 n=k(或某个正整数 k)时成立,即 P(k) 成立,然后证明在 n=k+1 时,命题也成立,即 P(k+1) 成立。 (用归纳假设 P(k) 推导出 P(k+1) 的成立)
根据基础步骤和归纳步骤的证明,可以得出结论:命题 P(n) 对于所有自然数 n 成立。
强归纳
命题:对于所有自然数 n(通常是正整数),命题 P(n) 成立。
证明:
- 基础步骤:首先证明命题在 n=1(或其他适当的起始值)时成立。 (明确表达命题在起始值上的成立情况)
- 强归纳步骤:假设对于所有小于 n 的自然数,命题都成立,即对于任意 m < n,命题 P(m) 成立。然后证明在 n 时,命题也成立,即 P(n) 成立。 (使用前面所有项的成立作为假设,推导出 P(n) 的成立)
根据基础步骤和强归纳步骤的证明,可以得出结论:命题 P(n) 对于所有自然数 n 成立。
强归纳相比于普通归纳法,更强调了使用前面所有项的情况来推导出下一项的情况。
状态机
状态机(State Machine),又称状态转移图或有限状态机,是计算机科学中的一种模型,用于描述对象或系统在不同状态之间转换的行为。它是由一组状态、转移条件和动作组成的,用于描述对象或系统的行为和状态转换。
状态机包含以下几个要素:
- 状态(State):状态是对象或系统可能处于的不同状态。每个状态代表对象或系统的一个特定条件或情况。在状态机中,状态可以是离散的,也可以是连续的。
- 转移(Transition):转移表示状态之间的转换。当满足特定的条件时,状态机可以从当前状态转移到新的状态。转移可以是确定性的,也可以是非确定性的。
- 转移条件(Transition Condition):转移条件是触发状态转移的条件。它是一个逻辑条件,当满足时,状态机执行相应的状态转换。
- 动作(Action):动作是在状态转移过程中执行的操作。它可以是简单的行为,也可以是复杂的操作。
状态机有两种主要类型:确定性状态机和非确定性状态机。
- 确定性状态机:在确定性状态机中,对于每个状态和转移条件,只有一种可能的转移路径。状态转移是唯一的,因此在给定的状态和输入条件下,状态转移是确定的。
- 非确定性状态机:在非确定性状态机中,对于某些状态和转移条件,可能有多个转移路径。在给定的状态和输入条件下,可能有多种可能的状态转移。
在从一个状态转变为另一个状态时,需要满足状态转移的条件,以及在转移过程中会执行动作。
如下:S为状态,A、B为转移条件,而start和close为动作。
\((will \ done:start)S1\xLeftrightarrow[condition:B]{condition:A}S2(will \ done:close)\)
派生变量
也称为衍生变量或计算变量,通过数学运算、逻辑运算、分组统计和特征工程等处理数据方法,将原始数据转换为新的输入参数。
结构归纳
命题:对于递归定义的结构 S,性质 P(S) 成立。
证明:
- 基础步骤:证明当 S 是基础元素或基本情况时,性质 P(S) 成立。
- 归纳步骤:假设当 S 规模为 k 时,性质 P(k) 成立,证明当 S 规模为 k+1 时,性质 P(k+1) 成立。
基数
指一个集合中元素个数。也称为集合的势或大小。
可数集
指利用自然数集可以对集合元素一一对应编号,被称之为可数集
康托尔定理
如果集合 A 和集合 B 可以分别与对方的一个子集存在一一对应关系,即存在两个函数 f: A → B 和 g: B → A,使得 f 和 g 都是一一映射,则集合 A 和集合 B 有相同的基数(cardinality)。即两个集合的元素存在双射关系。
集合论公理
- 外延公理(Extensionality Axiom):如果两个集合具有相同的元素,则它们是相等的。即:∀A∀B [∀x(x∈A ↔ x∈B) → A=B]
- 空集公理(Empty Set Axiom):存在一个集合,其中不包含任何元素,称为空集。即:∃∅[∀x(x∉∅)]
- 配对公理(Pairing Axiom):对于任意两个元素 a 和 b,存在一个集合 {a, b},其中只包含这两个元素。即:∀a∀b∃{a, b}[∀x(x=a ∨ x=b)]
- 并集公理(Union Axiom):给定任意一个集合 A,存在一个集合 B,其中的元素是 A 中所有元素的并集。即:∀A∃B∀x(x∈B ↔ ∃C(x∈C ∧ C∈A))
- 幂集公理(Power Set Axiom):给定任意一个集合 A,存在一个集合 B,其中的元素是 A 的所有子集。即:∀A∃B∀x(x∈B ↔ x⊆A)
- 无穷公理(Infinity Axiom):存在一个集合,它包含所有自然数的集合。即:∃N[∅∈N ∧ ∀x(x∈N → x∪{x}∈N)]
- 替代公理(Replacement Axiom):对于任意一个集合 A 和关于 A 中元素的条件 P(x),存在一个集合 B,其中包含满足条件 P(x) 的所有元素。即:∀A∀P(x)∃B∀y(y∈B ↔ ∃x(x∈A ∧ P(x, y)))
- 正则公理(Regularity Axiom 或 Foundation Axiom):任意非空集合 A,存在一个元素 a,使得 A 和 a 没有交集。即:∀A[A≠∅ → ∃a(a∈A ∧ a∩A=∅)]
欧几里得算法GCD
是一种用于求解两个整数之间最大公约数算法。通过比较两整数大小,将大的数除以小的数,直至得到余数为0,其小的数为最大公约数。
计算步骤:
- 将 a 和 b 比较,令较大的数为 a,较小的数为 b。
- 用 a 除以 b,得到商 q 和余数 r(a = b * q + r)。
- 如果余数 r 等于 0,则最大公约数为 b,即 GCD(a, b) = b。
- 如果余数 r 不等于 0,则用 b 除以 r,再次得到商 q 和余数 r。
- 重复步骤 3 和步骤 4,直到余数为 0。最后的除数 b 就是所求的最大公约数,即 GCD(a, b)。
int gcd(int a,int b){
return b?gcd(b,a%b):a;
}
扩展欧几里得算法EXGCD
通过贝祖定理定理给其算法的描述\(ax+by=gcd(a,b)\).其中对于任意的整数a,b,都存在一对整数x,y,使得\(ax+by=gcd(a,b)\)成立。
由欧几里得算法可知:当我们使用递归函数进行计算时,其中的构造步骤为:
-
\(if \ b =0,x=1,y=0\),分析出递归结束条件
-
分析出在b>0时,每次b的值更换:\(a\mod b=a-\lfloor\frac{a}{b}\rfloor b\),
-
\(ax+by=GCD(a,b)=GCD(b,a\%b)=bx+(a\%b)y=bx+(a-\lfloor\frac{a}{b}\rfloor b)y=ay+(x-\lfloor\frac{a}{b}y\rfloor)b\)
-
令\(x'=y,y'=(x-\lfloor\frac{a}{b}\rfloor y)\).
-
可得贝祖定理的证明式子:\(ax'+by'=gcd(a,b)\)
代码:
int exgcd(int a , int b ,int &x, int &y){
if(b==0) {//递归结束条件,即最大公约数为b,并得到系数x=1,y=0
x=1;y=0;
return a;
}
int return_value = gcd(b,a%b,x,y);//先计算当前递归的返回值
int temp = x;
x = y;//计算x' = y
y = temp - a % b *y;//y' = x - loof(a/b)y
return return_value;
}
质因数分解
质因数分解的步骤如下:
- 选择一个正整数 n,然后找到 n 的最小质因数 p1。
- 将 n 除以 p1,得到商 q1 和余数 r1。如果 r1 为 0,则 n 是一个质数,质因数分解结束。如果 r1 不为 0,则继续下一步。
- 对商 q1 进行相同的步骤,找到它的最小质因数 p2,并继续将 q1 除以 p2,得到商 q2 和余数 r2。
- 不断重复上述步骤,直到最终的商 qk 是一个质数为止。
- 将每个找到的质因数 p1, p2, ..., pk 依次相乘,得到原始整数 n 的质因数分解形式。
欧拉函数
- 模幂(Modular Exponentiation):模幂是指计算形如 a^b mod m 的运算,其中 a、b 和 m 都是整数,^ 表示乘方运算,mod 表示取模运算(即取余数)。在计算 a^b mod m 时,由于指数 b 可能非常大,直接计算可能非常耗时,而模幂算法可以高效地计算这个结果。
常用的模幂算法包括快速幂算法,它利用指数 b 的二进制表示来逐步计算 a^b mod m,以减少乘法和取模的次数,从而提高计算效率。
- 欧拉函数(Euler's Totient Function):欧拉函数 φ(n) 是指小于等于正整数 n 且与 n 互质的正整数的个数。换句话说,φ(n) 表示与 n 互质的小于 n 的正整数的个数。
图
DAG(有向无环图)中的调度
在 DAG 中,每个节点表示一个任务或作业,而有向边表示任务之间的依赖关系。一个节点只有当其所有前置任务都已经完成(即所有入边都已经执行)时才能执行(类似于数据结构中的关键路径)。因为 DAG 是无环图,所以不存在循环依赖,这保证了任务的执行顺序是可行的。
DAG 调度的目标通常包括以下几个方面:
- 最短执行时间:即使得整个 DAG 执行完成所需的最小时间。这是一个重要的优化目标,尤其在并行计算和高性能计算中,希望尽量缩短任务的执行时间,以提高计算效率。
- 负载均衡:尽量使得各个处理节点或处理器的负载均衡,避免出现一些节点执行过多任务而另一些节点处于空闲状态的情况。
- 资源利用率:合理利用计算资源,确保任务之间的并发执行,以提高资源利用率和整体效率。
- 满足依赖关系:保证 DAG 中的任务依赖关系得到满足,即每个任务在执行前能够正确地获取其依赖任务的输出。
常用的 DAG 调度算法包括:
- 拓扑排序:通过拓扑排序可以确定 DAG 中节点的执行顺序,使得前置任务在后续任务之前执行,从而满足依赖关系。
- 并行调度:将 DAG 中的任务分配到多个处理器或计算节点上并行执行,以提高整体执行效率。
- 动态规划:对于复杂的 DAG 调度问题,可以利用动态规划等方法求解最优的调度方案。
同构图的判断:
从结点的度入手,以及当对两个图很大的时候,同构对一个特点的结点连接结构,记录一个图中小块的节点度数,在另一个图中查找是否有满足该情况的节点,从而快速判断两个图是否同构。
树
树的着色
课程中使偶数路径的节点为红色,而奇数路径数的节点为绿色。
生成树
生成树是图中连通性为1,且具有所有结点的图。
最小生成树算法:prime归并点,kruskal归并边,Meyer。
结点稳定匹配
站在不同端的结点进行匹配是不稳定,但如果添加所需的匹配条件,可能更符合某一方。
离散概率
Monty Hall树
课程中,老师介绍了一个三个门中选择有奖品的门的小游戏。他讲述了,通过直觉去判断概率是不对的。
使用了Monty Hall数,来统计出现事件的发生的最终情况,并计算每个发生事件的概率。并统计,实际坚持选择和换另一个选择的概率并不相等。实际前者只有1/3,后者有2/3的概率。
提示:一些事情的发展具有树型概率时,我们可对其进行假设,并使用树模型计算每个情况的概率。从而帮助判断。
感觉有点类似决策树。
构建树的方法:
- Identify outcomes (tree helps)
- Identify event (winning)
- Assign outcome probabilities
- Compute event probabilities
样本空间
定义:\(Pr\{\bigcup_{\substack{i\in \mathbb{N}}}A_i\}=Pr\{\sum_{i\in \mathbb{N}}A_i\}\)其中引出了集合的差集、交集.
条件概率
\(P(B|A)=\frac{P(AB)}{P(A)}\)推演
全概率模型
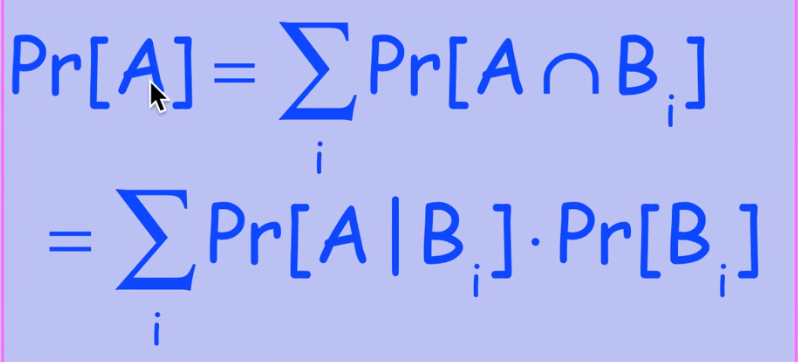
贝叶斯定理

独立事件
\(P(A\bigcap B)=P(A)P(B)\),即事件A和事件B发生相互独立。
\(P(A)=P(A|B)\).
离散型随机变量
是指定义在离散的结果空间\(\Omega\)(指有限或可数的)上的实值函数,具体是指,每个元素\(\omega\in\Omega\)有一个指定的实数\(X(\omega)\).
也就是一个事件的概率是具有指定实数。
概率密度函数
\(f_X(x)=Prob(\omega\in\Omega: X(\omega)=x)\).X取某个特定值的概率的规则。概率密度函数的值总是大于或等于0,并且和始终为1.
累积分布函数
概率密度函数是取x,而累积分布函数是取一个范围的概率。
\(F_X(x)=Prob(\omega\in\Omega: X(\omega)\le x)\)
期望
期望(Expectation):期望是随机变量的平均值或预期值。它表示了在多次重复试验中,某个随机变量的平均结果。对于一个离散随机变量 X,其期望值(μ)通常用以下公式表示:
E(X) = Σ [x * P(X=x)]
其中,x 表示随机变量可能取的值,P(X=x) 表示随机变量取值 x 的概率。对于连续随机变量,期望值的计算使用积分而不是求和。
例如,掷一枚均匀的六面骰子,每个面的点数是1到6之间的整数,那么骰子的期望值就是 (1+2+3+4+5+6)/6 = 3.5。
总体预期
"总体预期"(Population Expectation)是统计学和概率论中的一个重要概念,它指的是对整个总体(总体是指研究对象的全部个体或数据集合)的某个随机变量的期望值。总体预期表示了对总体中所有成员的平均值或预期值。
通常,总体预期用 μ(小写希腊字母mu)表示。对于一个总体 X,其总体预期 μ 可以用以下数学公式表示:
μ = E(X)
其中,E(X) 表示随机变量 X 的期望值,也就是 X 的平均值。
总体预期在统计分析和推断中扮演着重要的角色,因为它是对总体性质的一个关键描述。通过了解总体预期,可以得出有关总体的许多重要信息,例如平均水平、中心趋势等。总体预期也是许多统计估计和假设检验的基础,因为它提供了对总体特征的估计和比较的依据。
期望的线性
"期望的线性"是指一个随机变量的期望(平均值)在进行线性运算(加法和乘法)时的性质。这个性质表明,随机变量的期望在进行线性运算时可以分解成各个随机变量的期望和系数的线性组合。这是概率论和统计学中的一个重要性质,通常被称为线性期望(Linearity of Expectation)。
具体来说,对于任意两个随机变量 X 和 Y,以及任意常数 a 和 b,线性期望可以表述为:
- 期望的加法性质: E(aX + bY) = aE(X) + bE(Y)
- 期望的乘法性质(仅当 X 和 Y 相互独立时成立): E(XY) = E(X) * E(Y)
这意味着当你对两个或多个随机变量进行加法和乘法运算时,你可以将这些运算分别应用到每个随机变量的期望上,然后再进行线性组合或乘法运算,得到整体的期望。
偏离均值
偏离均值(Deviation from the Mean)是一个用来衡量数据点或随机变量与其平均值之间差异的概念。它表示了每个数据点或随机变量与均值之间的距离或差异程度。通常,偏离均值可以用以下的方式计算:
对于一个数据点 xi(其中 i 表示数据点的索引或标号),与均值 μ 之间的偏离可以用以下公式表示:
偏离(xi) = xi - μ
其中,
- 偏离(xi) 表示数据点 xi 与均值 μ 之间的偏离或差异。
- xi 是第 i 个数据点的值。
- μ 是数据集的均值(平均值)。
偏离均值的计算结果可以为正数、负数或零,具体取决于数据点的值与均值之间的关系。正数表示数据点高于均值,负数表示数据点低于均值,零表示数据点等于均值。
偏离均值对于理解数据的分布和变异性非常重要。通过计算每个数据点与均值的偏离,我们可以分析数据的离散程度、数据点的散布情况以及异常值。在统计学和数据分析中,偏离均值常常用于计算方差、标准差以及其他描述数据分布和变异性的统计量。
马尔可夫不等式
如果\(x>0 \ and \ a>0,then\ P(X\ge a)\le\frac{E[x]}{a}\),其实际概率与它期望/a的距离较远。
切比雪夫不等式
如果\(x>0 \ and \ a>0,then\ P(|X-\mu|\ge a)\le\frac{E[(x-\mu)^2]}{a^2}\)
暂时先留坑。
方差
方差(Variance)是统计学中用来衡量随机变量或数据集分布的离散程度或不确定性的一个重要指标。方差表示数据点与其均值之间的离散程度,也可以理解为数据的扩散程度。
方差的计算方法如下,假设有一个包含 n 个观测值的数据集 {x1, x2, ..., xn},其中 x̄ 表示这些观测值的均值(平均值):
方差 = Σ(xi - x̄)² / n
其中:
- xi 表示数据集中的第 i 个观测值。
- x̄ 表示数据集的均值。
- Σ 表示求和符号,对数据集中的每个观测值进行累加。
- n 表示数据集中观测值的数量。
方差的值越大,表示数据点相对于均值分散得越广,数据集的离散程度越高。相反,方差的值越小,表示数据点相对于均值聚集得越紧,数据集的离散程度越低。
大数定律
大数定律(Law of Large Numbers)是概率论中的一个基本原理,描述了随着样本容量的增加,样本均值趋近于总体均值的现象。大数定律有两个主要版本:弱大数定律和强大数定律。
-
弱大数定律(Weak Law of Large Numbers):弱大数法则(Weak Law of Large Number):
弱大数定律指出,对于来自同一总体的独立随机变量的样本均值,随着样本容量的增加,样本均值会趋近于总体均值,并在概率上收敛。具体而言,如果有一个独立同分布的随机变量序列 {X1, X2, X3, ...},它们具有相同的总体均值 μ 和总体方差 σ^2,那么对于任意 ε > 0:
lim (n->∞) P(|(X1 + X2 + ... + Xn)/n - μ| < ε) = 1
这意味着随着样本容量 n 的增加,样本均值的绝对偏差小于 ε 的概率趋近于1,即样本均值以概率1收敛于总体均值 μ。
-
强大数定律(Strong Law of Large Numbers):强数据决策(Strong Law of Large Numbers):
强大数定律进一步强调了样本均值与总体均值的收敛性。它指出,对于来自同一总体的独立随机变量的样本均值,几乎处处都会收敛到总体均值。具体而言,如果有一个独立同分布的随机变量序列 {X1, X2, X3, ...},它们具有相同的总体均值 μ 和总体方差 σ^2,那么几乎对所有样本路径,都有:
lim (n->∞) [(X1 + X2 + ... + Xn)/n] = μ
这意味着在几乎所有情况下,随着样本容量 n 的增加,样本均值会几乎确定地收敛于总体均值 μ。
采样和置信度
- 采样(Sampling):
- 采样是从一个较大的总体或群体中选择部分个体或元素的过程,以便对总体特性或性质进行研究或估计。
- 在统计学中,采样通常用于从大规模或无法完全观察的总体中获取样本数据。样本数据是总体的代表,允许进行统计分析和做出推断,而无需收集和分析整个总体数据。
- 采样方法可以是随机抽样、分层抽样、系统抽样等,具体方法取决于研究的目的和总体的性质。
- 置信度(Confidence):
- 置信度是一个度量统计估计的可靠性或确定性的概念。它表示在一定的置信水平下,估计值包含或者不包含总体参数的可能性。
- 通常,统计估计伴随着一个置信区间,该区间表示估计值可能落在其中的范围。例如,我们可以说:"我们对估计的均值有95%的置信度,置信区间为[8, 12]。" 这意味着我们有95%的信心估计的均值在8到12之间。
- 置信度水平通常以百分比(例如95%、99%等)表示,表示我们对估计的可信度有多高。置信度水平越高,置信区间越宽,估计值的确定性越高。
随机游走
随机游走(Random Walk)是一种数学模型,用于描述在离散时间点上的随机漫步或随机移动过程。在随机游走中,一个物体(通常用点或粒子表示)在每个时间步骤上以随机的方式移动到相邻的位置,可能向左或向右等概率地移动,也可能在一维情况下停留在原地。
有两种主要类型的随机游走:
- 简单随机游走:在简单随机游走中,物体在每个时间步骤上有两个可能的移动方向,通常是向左或向右,且每个方向的概率相等。这种类型的随机游走常用于描述随机过程的基本特性。
- 随机游走模型:在这种模型中,物体在每个时间步骤上可以以不同的概率移动到不同的位置,这些概率可以根据特定的概率分布进行建模。例如,布朗运动(Brownian Motion)是一种连续时间的随机游走模型,其中物体的位置在每个时间点上按照正态分布随机漫步。
随机游走是概率论、统计学和物理学中的一个重要概念,它有多种应用,包括金融市场的价格变动、股票价格的模拟、分子运动的建模、噪声的分析、信息传输的模拟等。
平稳分布
平稳分布(Stationary Distribution)是指在一个马尔可夫链(Markov Chain)中,当时间趋于无穷大时,状态分布保持不变的概率分布。在马尔可夫链中,每个状态之间的转移是随机的,但经过足够长的时间后,链会达到一个平稳状态,此时状态分布不再发生变化,称为平稳分布。
具体来说,对于一个离散时间的马尔可夫链,其状态空间可以表示为 {S1, S2, S3, ...},其中 Si 表示可能的状态。平稳分布 π = (π1, π2, π3, ...) 是一个概率分布,满足以下条件:
- 所有状态的概率值都是非负的:πi ≥ 0,对于所有 i。
- 所有状态的概率之和等于1:Σπi = 1,其中 i 遍历所有可能的状态。
当时间趋于无穷大时,马尔可夫链的状态分布接近于平稳分布 π。这意味着,如果你从平稳分布中随机选择一个状态,那么无论在什么时刻,选择的状态都遵循平稳分布。
它用于分析和理解随机过程的长期行为。平稳分布的计算通常涉及到解线性方程组,通常可以通过数值方法或代数方法来获得。平稳分布的存在和性质取决于马尔可夫链的转移概率矩阵,这也是马尔可夫链理论的一个关键方面。
PageRank
PageRank(页面排名)是一种用于评估网页重要性的算法。PageRank是搜索引擎谷歌的早期核心算法之一,用于确定搜索结果中网页的排名顺序。
PageRank的核心思想是基于链接分析,它认为一个网页的重要性可以通过其他网页链接到它的数量和质量来衡量。具体来说,PageRank考虑以下几个因素:
- 入链数量:一个网页被其他网页链接到的数量。如果一个网页被许多其他网页链接到,那么它可能更重要。
- 入链质量:链接到一个网页的其他网页的重要性。如果一个高权重的网页链接到另一个网页,那么被链接的网页的重要性也会提高。
- 网页内部链接:一个网页内部链接到其他网页的数量和质量。网页的内部链接结构也可以影响其PageRank。
PageRank通过对这些因素进行复杂的数学计算,为每个网页分配一个分数,表示其重要性。具有较高PageRank分数的网页通常在搜索结果中排名较高,因为它们被认为更相关或更重要。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号