基础工具之基础学习记录
本节包含了CS学生工具的基本学习和部分常识概念。
Linux命令
常见的ls、vim、chmod、cat,echo和curl命令已经熟悉,以下仅记录grep、awk和send学习
grep
grep 是一个用于在文本文件中搜索特定模式的命令。它可以帮助你从文件中找出符合某种规则或模式的行,并将这些行打印出来。
grep可用于shell脚本,因为grep通过返回一个状态值来说明搜索的状态,如果模板搜索成功,则返回0,如果搜索不成功,则返回1,如果搜索的文件不存在,则返回2。我们利用这些返回值就可进行一些自动化的文本处理工作。
- -A<行数 x>:除了显示符合范本样式的那一列之外,并显示该行之后的 x 行内容。
- -B<行数 x>:除了显示符合样式的那一行之外,并显示该行之前的 x 行内容。
- -C<行数 x>:除了显示符合样式的那一行之外,并显示该行之前后的 x 行内容。
- -c:统计匹配的行数
- -e :实现多个选项间的逻辑or 关系
- -E:扩展的正则表达式
- -f 文件名:从文件获取
PATTERN匹配 - -F :相当于
fgrep - -i --ignore-case #忽略字符大小写的差别。
- -n:显示匹配的行号
- -o:仅显示匹配到的字符串
- -q: 静默模式,不输出任何信息
- -s:不显示错误信息。
- -v:显示不被
pattern匹配到的行,相当于[^] 反向匹配 - -w :匹配 整个单词
例
”patter“表示的是你想要在文本中进行筛选或匹配的字符序列.
- 基本用法:
grep "pattern" filename
这会在指定的文件(filename)中搜索包含指定模式(pattern)的所有行,并将这些行打印出来。
- 忽略大小写:
grep -i "pattern" filename
使用 -i 选项可以忽略模式的大小写,这样不区分大小写地搜索。
- 递归搜索目录:
grep -r "pattern" directory
使用 -r 或 -R 选项可以在指定目录及其子目录下递归地搜索模式。
- 显示行号:
grep -n "pattern" filename
使用 -n 选项可以显示匹配行的行号。
- 反向匹配:
grep -v "pattern" filename
使用 -v 选项可以显示不匹配指定模式的行。
- 只显示匹配的模式:
grep -o "pattern" filename
使用 -o 选项只显示匹配的模式,而不显示整行。
- 使用正则表达式:
grep -E "regex-pattern" filename
使用 -E 选项可以启用扩展正则表达式来进行模式匹配。
- 从管道中读取输入:
command | grep "pattern"
你可以将其他命令的输出通过管道传递给 grep 进行模式匹配。
- 将多个模式组合:
grep -e "pattern1" -e "pattern2" filename
使用 -e 选项可以在同一个命令中同时搜索多个模式。
awk
awk是一种强大的文本处理工具,常用于从文件或数据流中提取、处理和格式化文本数据。简单来说awk就是把文件逐行的读入,以空格为默认分隔符将每行切片,切开的部分再进行各种分析处理。
语法
awk [选项参数] 'script' var=value file(s)
或
awk [选项参数] -f scriptfile var=value file(s)
参数说明:
- -F fs or --field-separator fs 指定输入文件折分隔符,fs是一个字符串或者是一个正则表达式,如-F:。
- -v var=value or --asign var=value 赋值一个用户定义变量。
- -f scripfile or --file scriptfile 从脚本文件中读取awk命令
例
- 字段分隔符: 默认情况下,Awk将每行文本分割成多个字段,使用空格作为字段分隔符。你可以使用
-F选项来指定自定义的字段分隔符。例如,使用逗号作为字段分隔符:
awk -F ',' '{ print $1 }' input-file
- 打印特定列: 使用
$n表示第n个字段,例如,打印第一列的内容:
awk '{ print $1 }' input-file
- 条件匹配和处理: 使用
pattern来指定条件匹配,然后在满足条件的行上执行相应的动作。例如,打印第二列值大于10的行:
awk '$2 > 10 { print }' input-file
- 内置变量:Awk提供了许多内置变量,如
$0表示整行内容,NF表示字段数量,NR表示行号,等等。你可以使用这些变量来执行更复杂的操作。例如,打印行号和第二列的值大于10的行:
awk '$2 > 10 { print NR, $0 }' input-file
- 自定义输出格式: 使用
printf函数可以自定义输出的格式。例如,打印第一列和第三列,使用固定宽度对齐:
awk '{ printf "%-10s %s\n", $1, $3 }' input-file
- 使用脚本文件:如果需要执行复杂的Awk操作,可以将Awk命令放入一个独立的脚本文件中,然后使用
-f选项来执行脚本文件。例如,将Awk命令保存为myscript.awk,然后执行:
awk -f myscript.awk input-file
sed
sed是一个流式文本编辑工具,用于在文本流(文件、输入流等)中进行文本替换、删除、插入和转换等操作。它通常用于处理大量文本数据,可以通过脚本编程来执行复杂的文本处理任务。
sed [-hnV][-e<script>][-f<script文件>][文本文件]
参数说明:
-e<script>或--expression=<script>以选项中指定的script来处理输入的文本文件,这个-e可以省略,直接写表达式。-f<script文件>或--file=<script文件>以选项中指定的script文件来处理输入的文本文件。-h或--help显示帮助。-n或--quiet或--silent仅显示script处理后的结果。-V或--version显示版本信息。
动作说明:
- a:新增, a 的后面可以接字串,而这些字串会在新的一行出现(目前的下一行)~
- c:取代, c 的后面可以接字串,这些字串可以取代 n1,n2 之间的行!
- d:删除,因为是删除啊,所以 d 后面通常不接任何咚咚;
- i:插入, i 的后面可以接字串,而这些字串会在新的一行出现(目前的上一行);
- p:打印,亦即将某个选择的数据印出。通常 p 会与参数 sed -n 一起运行~
- s:取代,通常这个 s 的动作可以搭配正规表示法,例如 1,20s/old/new/g 。
例
-
多个命令: 你可以通过使用分号将多个
sed命令串联在一起,以依次执行多个操作。例如,删除包含 "delete" 的行,并将 "old" 替换为 "new":sed '/delete/d; s/old/new/g' input-file -
正则表达式:
sed支持正则表达式,你可以在命令中使用正则表达式来匹配文本。例如,将以数字开头的行删除
sed '/^[0-9]/d' input-file
- 替换文本: 使用
s/pattern/replacement/命令来替换文本中的模式(pattern)为指定的替换内容(replacement)。例如,将文件中所有的 "old" 替换为 "new":
sed 's/old/new/g' input-file
正则表达式
网址推荐:正则表达式学习网站
单个字符匹配
以下是匹配的是单个字符的语法
| 匹配语法 | 解释 |
|---|---|
| 单个abc...或者123... | 表示对应的单个字符 |
| \d | 表示任意数字字符 |
| \D | 表示任意非数字字符 |
| . | 类似数据库中'_'匹配字符,其也表示单个字符的通配符。 |
| \. | 加上转义字符后表示为句号"." |
| [abc] | 加上[]后,表示要么a,要么b或则c,即里面元素为并列关系 |
| [^abc] | 表示非里面的元素,即不是a,b,也不是c |
| \w | 任何数字字母 |
| \W | 任何非数字字母 |
单个字符出现次数匹配
以下是将匹配字符的次数提升
| 匹配语法 | 解释 |
|---|---|
| [a-b] or [0-9] | 表示字符从X-Y,即从a到b,从0到9 |
| {m}, | {}前面跟个字符或语法,表示该字符出现m次,或者n到m次 |
| * | 零次或多次重复 |
| + | 一次或多次重复 |
其他匹配
| 匹配语法 | 解释 |
|---|---|
| ? | ?前紧跟的字符,表示可选。例如, ab?c 将匹配字符串“abc”或“ac”,因为 b 被认为是可选的。 |
| \s | 任何空格字符 |
| \S | 任何非空格字符 |
| ^ | 用于匹配行的开头,如:在success and. 中,表达式^success指出匹配行的开头success |
| $ | 用于匹配行的结尾,如:在success and. 中,表达式end$指出匹配行的开头success | |
| (...) | 捕获组,即将符合()内匹配的字符为一组 |
| (a(bc)) | 即嵌套捕获组。如:May 1969,表达式为(\w (\d+)) |
| (.*) | 捕获全部 |
| (abc|def) | 其中|表示或, |
正则表达式匹配方法
贪婪模式和非贪婪模式
前者是匹配后一直匹配至访问结束再返回结果;后者是只要匹配到一个符合条件就返回结果。
vim学习
此处就放一些自己学习的命令
有以下操作模式
- Normal: for moving around a file and making edits
正常:用于移动文件并进行编辑 - Insert: for inserting text
插入:用于插入文本 - Replace: for replacing text
Replace:用于替换文本 - Visual (plain, line, or block): for selecting blocks of text
视觉(纯文本、行或块):用于选择文本块 - Command-line: for running a command
命令行:用于运行命令
命令模式下
按键:hjkl对应左、下、上、右键
单词: w (下一个单词)、 b (单词开头)、 e (单词结尾)
文件: gg (文件开头), G (文件结尾)
屏幕: H (屏幕顶部)、 M (屏幕中间)、 L (屏幕底部)
行: 0 (行首)、 ^ (第一个非空白字符)、 $ (行尾)
dw 是删除单词, d$ 是删除到行尾, d0 是删除到行首
o / O 在下方/上方插入行
s 替换字符(等于 cl )
u 撤消, <C-r> 重做
末行模式
:q #不保存并退出
:q! #不保存并强制退出
:wq #保存并退出
:wq #保存并强制退出
:set nu #显示每一行的行数
:行数 #跳转到对应的行数
:#
配置插件
创建目录 ~/.vim/pack/vendor/start/ ,并将插件放入其中(例如通过 git clone )。
MIT课程中老师的推荐:
- ctrlp.vim: fuzzy file finder 模糊文件查找器
- ack.vim: code search 代码搜索
- nerdtree: file explorer文件浏览器
- vim-easymotion: magic motions
shell:文字接口
常使用命令介绍
如cat、echo、curl、mkdir(创建文件夹)、mv(移动或重命名文件)、cp(拷贝文件)、ls(查看当前路径或指定路径下文件夹下的各个文件属性)、touch(创建普通文件)、vim文件编辑工具、man -指令名(查看部分指令的README.md文件),管道‘|’,流定向('<' file :输出流,'>' file: 输入流)
需要注意的细节
在shell中使用空格起到分割参数的作用。
以'定义的字符串为原义字符串,其中的变量不会被转义,而 "定义的字符串会将变量值进行替换。
bash也支持if, case, while 和 for 这些控制流关键字。同样地, bash 也支持函数,它可以接受参数并基于参数进行操作。
例如:创建mcd.sh脚本文件,内容如下:
#! /bin/sh
mcd(){
mkdir -p ./"$1"
cd ./"$1"
}
mcd "test" && exec "$SHELL"#此命令用于调用函数,并将shell进程切换到该目录下
然后命令进行调用:$./mcd.sh
另一种形式:
创建mcd2.sh脚本文件,内容如下:
#! /bin/sh
mcd2(){
mkdir -p ./"$1"
cd ./"$1"
}
命令行调用
$. ./mcd2.sh #先加载mcd2.sh脚本文件
$mcd2 "test"#调用mcd2函数,且传递参数test
参数传递使用空格间隔,使用"\ "表示将空格看作转义字符,则后续紧跟的字符与前一个做一个整体
$0- 脚本名$1到$9- 脚本的参数。$1是第一个参数,依此类推。$@- 所有参数$#- 参数个数$?- 前一个命令的返回值$$- 当前脚本的进程识别码!!- 完整的上一条命令,包括参数。常见应用:当你因为权限不足执行命令失败时,可以使用sudo !!再尝试一次。$_- 上一条命令的最后一个参数。如果你正在使用的是交互式 shell,你可以通过按下Esc之后键入 . 来获取这个值。
在普通文件首行命令作用
#! /bin/sh #此行的#!用于告诉shell本文件应使用什么命令来解析(调用什么解释器)
如:
#!/bin/sh—使用sh,即Bourne shell或其它兼容shell执行脚本
#!/usr/bin/python -O—使用具有代码优化的Python执行
#!/usr/bin/env 脚本解释器名称是一种常见的在不同平台上都能正确找到解释器的办法。
课后作业
就是简单的使用指令创建文件,以及使用echo和流定向符将内容写入文件,以及使用chmod权限修改文件权限。
chmod -R 777 ./tmp/missing/semester
#用于修改文件权限,这个是把该文件所有权限赋予所有用户,不建议习惯这样做
第9题:
ls -l semester | awk '{print $6, $7, $8}' > /home/duuuuu17/last-modified.txt
#需要注意的是,此处使用了awk命令,用于将ls -l semester文件的输出信息,获取第6、7、8列的信息,输入于/home/duuuuu17下的last-modified.txt文件
GCC学习
编译源文件
基础四步走
#预处理
gcc -E test.c -o test.i
#编译
gcc -S test.i -o test.s
#汇编
gcc -c test.s -o test.o
#链接
gcc test.o -o test
- o:指定生成文件的路径和名称。这适用于正在生成的任何类型的输出,无论是可执行文件、对象文件、汇编文件还是经过预处理的C代码。如果该参数缺省,当生成可执行文件时,在当前文件夹生成名为
a.out的可执行文件;当生成对象文件时将源文件后缀更为*.o (例如gcc -c hello.c-->hello.o)。
# 将汇编语言源文件编译为二进制可执行文件
gcc sequence_hello.s -o sequence_hello
- -c :编译(C源代码文件)或汇编(汇编源代码文件)源文件,但不进行链接。最终输出是以每个源文件的对象文件(
*.o)的形式出现的。
# 将 C 源文件编译为目标文件
gcc hello.c -c -o hello.o
- -g:生成调试信息。可以使用 GDB 调试带调试信息的可执行文件
# 将对象文件 hello.o 和 C 源文件 编译为带调试信息的二进制可执行文件 main
gcc hello.o main.c -g -o main
反编译
将二进制文件 按照默认指令集或处理器商语法反编译文件objdump -D 可执行文件名
将反汇编文件输出:使用输出流定向符>,将反编译结果输出给同名汇编文件。
objdump -d test > test.s
GDB学习
GDB使用也是command方式进行操作。所以以下代码格式被我标记被bash格式。
使用gdb执行可执行文件
#gdb 可执行文件(需要有路径)
gdb ./test.exe
#run 执行加载的可执行文件
run
#start 开始调试可执行文件
start #会自动停在某个地方,一般是程序栈刚入一个栈帧就暂停
#quit 退出gdb调试
断点、语句执行方式
#break [var|function],断点,即在某个变量处或则某个函数处打上断点
break function_name
#next:下一段(跳过条件判断代码),step:下一步(不跳过条件判断代码)
#continue:从本代码执行到断点,finsh:执行完成函数调用(执行完当前调用函数的栈帧并返回),若函数调用返回主函数,则指向下一条主函数代码直至结束并且自动退出gdb
#列出源码
list #随着栈帧的插入,显示插入的函数
查询变量类型、监视变量、修改变量值
#whatis [var|function]返回变量的数据类型或则函数的参数类型和返回值类型
whatis a
>>type = int
whatis function
>>type = int (int)
#print/p var 输出某个变量现在的存储值
p a
#display var,是print命令的自动版,即每当运行到暂停处时,会自动打印某些值
display a
#undisplay id_num,取消监视变量
#需要注意的是,我们在取消某些操作时,使用的是gdb对这些变量标记的id_num。不知道id_num使用info查询
info locals#查看当前栈帧局部变量的值
#watch var
#这条命令会在变量进行任何变动时,会打印旧值和新值
watch n
#info watchpoint,用于查看当前设置了那些观察点
#delete id_num:删除监视变量
#set var = values,能够在调试时修改变量值
set a = 4
查看程序栈、断点和监视信息
#bt:backtrace,显示栈中的函数调用
bt
>>
#0 fabla (n=1) at .\test.c:7
#1 0x0000000000401579 in fabla (n=2) at .\test.c:10
#2 0x0000000000401579 in fabla (n=3) at .\test.c:10
#3 0x0000000000401579 in fabla (n=4) at .\test.c:10
#4 0x0000000000401579 in fabla (n=5) at .\test.c:10
#5 0x00000000004015a1 in main () at .\test.c:15
栈帧增长方向默认是从高位到低位地址。具体根据体系结构确定地址的增长方向(即大端法或小端法的确定)
#info breakpoint 显示断点和监视变量
info breakpoint
>>Num Type Disp Enb Address What
1 breakpoint keep y 0x000000000040155b in fabla at .\test.c:7
breakpoint already hit 2 times
2 hw watchpoint keep y n
#解释: hw:hardware breakpoint:断点 watchpoint:监视变量
#设置断点
list#先通过list选择断点代码中的哪个位置
breakpoints 行数#设置断点
disable b 断点NUM#通过i b查看断点的num号,当不需要断点又不想删除时,用disable使其禁用,同理,启用断点为enable 断点号
delete b 断点号#删除断点
#x 从某个位置开始打印存储单元的内容,全部当成字节来看,而不区分哪个字节属于哪个变量
x/7b input[5]
高级调试命令
#target record-full
#此调试命令用于告诉gdb要标记所有变量,是执行回溯命令(在执行代码时,能够返回到上一条代码处)的前提
#reverse-next:回溯上一条代码命令
git学习
git推荐学习网址
git配置
1.安装git主程序
2.创建git总仓库文件,此文件下放置各仓库
3.生成公钥
ssh-keygen -t rsa -C 秘钥名
然后可以选择公钥文件名。路径:C:\Users\test\.ssh\id_rsa.pub
生成成功后,将公钥内容,复制到github的setting里的ssh模块下的配置里。
使用命令ssh -t git@github.com,验证是否成功
git常见指令
git clone
拉取一个本地仓库没有的文件。
git pull
拉取远程仓库的最新软件版本
git push github的ssh链接
将上传本地仓库至github。
git status
查看当前本地仓库新的未上传至仓库记录本的文件。
On branch main
Your branch is up to date with 'origin/main'.
Untracked files:
(use "git add <file>..." to include in what will be committed)
mathmatic.md
git add 文件及路径
将需要上传的文件,从工作区提交至暂存区(需要注意的是该文件需要在仓库的.git文件同级或以下的文件层级))
git add ./test.txt
git commit -m
确认暂存区需要提交的文件,至仓库内。
git push推送工作区至
连接远程仓库
git remote -v //查看远程仓库
git remote add <远程仓库别名> <url> //这样就不用每次输入仓库的git链接
例如:
git remote add DL git@github.com:xxx/xxx.git
有了提交的备注之后就可以把暂存区的文件推送到远程仓库了
git push -u <远程版本库名> <分支名>
分支
git branch //查看分支
git branch <branchName> //创建分支
git checkout <branchName> //切换分支
git checkout -b <branchName> //综合上面两句,创建并切换分支
git branch -d <branchName> //删除branchName分支
冲突
对于遇到同一个文件不同人的修改同一区域,且上传时,此时需要将修改进行合并。
git diff //默认工作区和暂存区比较
git diff --cached //暂存区和HEAD比较
git diff --HEAD //工作区和HEAD比较
回退
git revert
是生成一个新的提交来撤销某次提交,此次提交之前的commit都会被保留,只是将指定提交的代码给清除掉
git reset
是回到某次提交,提交及之前的commit都会被保留,但是此次之后的修改都会被退回到暂存区
merge和rebase
git merge:
记录下合并动作,很多时候这种合并动作是垃圾信息
不会修改原 commit ID
冲突只解决一次
分支看着不大整洁,但是能看出合并的先后顺序
记录了真实的 commit 情况,包括每个分支的详情
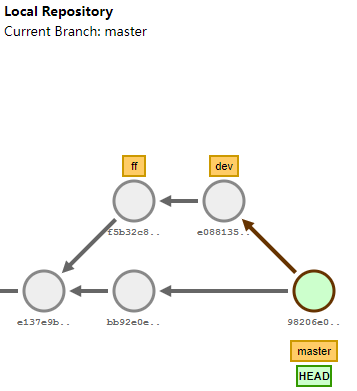
git rebase:
改变当前分支 branch out 的位置
得到更简洁的项目历史
每个 commit 都需要解决冲突
修改所有 commit ID
git rebase --abort,rebase的所有操作撤销。
其作用是将另一个分支的提交信息全部移动到当前开发分支上
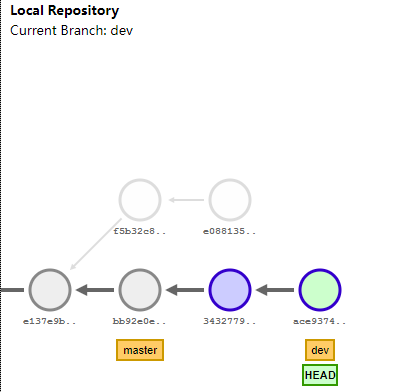
git remote
git remote add Study-CS (url带有.git结尾)。
git remote rm Study-CS,撤销远程配置
举例
配置远程仓库别名进行push
对于新创建的github仓库,使用git进行配置远程仓库
echo "# learning-basic" >> README.md
git init
git add README.md#git add 文件路径
git commit -m "first commit"#git commit -m "本次commit注释"
git branch -M master
git remote add origin git@github.com:xxx/xxx.git[github提供的ssh后缀为git链接]
git push -u origin master #git push -u 配置的远程仓库连接别名 分支
将本地仓库恢复到源服务器的状态
git reset 分支名
git clean -df ,删除未跟踪文件
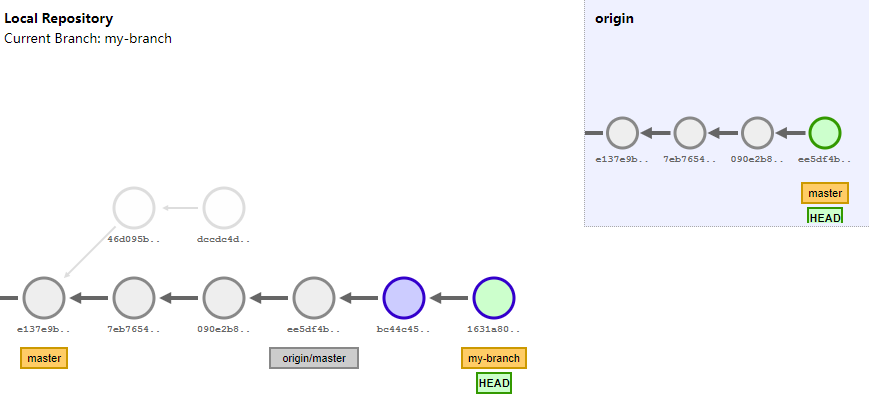
将远程仓库最新版本在本地进行更新
首先git fetch,更新本地分支与对应的远程仓库分支
然后git rebase 更新分支名
问题集
如果远程仓库为新建,出现版本报错问题
#前提:先将本地的文件拷贝至别处,然后。
#我们需要将在本地新建仓库,并初始化.使用:
git pull ssh地址#,将本地仓库版本与远程仓库版本一致
#然后,再将刚才拷贝备份的文件复制回来。
git add ./
git commit -m ""
#最后上传至远程仓库
git push ssh地址
Makefile学习
依赖管理
也就是管理一些项目本身所需的工具或库。这些工具或库是需要与项目本身的版本有依赖问题。需要其版本控制在有效范围内。也就是项目能够正常使用。
版本控制
版本号
x.y.z=主版本号.次版本号.补丁号;
版本号的修改如下规则:
- 如果新的版本没有改变 API,请将补丁号递增;
- 如果您添加了 API 并且该改动是向后兼容的,请将次版本号递增;
- 如果您修改了 API 但是它并不向后兼容,请将主版本号递增。
持续集成系统
是指在大型项目中,后续新代码的变动,因为是重复操作。我们希望能够有自动化的东西进行帮助我们测试它,看它是否符合我们的要求和标准。从而使我们从重复性工作中解放,到更有创造力的工作中去。
测试简介
此处是照搬的,仅作有个认知就行。
多数的大型软件都有“测试套件”。您可能已经对测试的相关概念有所了解,但是我们觉得有些测试方法和测试术语还是应该再次提醒一下:
- 测试套件:所有测试的统称。
- 单元测试:一种“微型测试”,用于对某个封装的特性进行测试。
- 集成测试:一种“宏观测试”,针对系统的某一大部分进行,测试其不同的特性或组件是否能协同工作。
- 回归测试:一种实现特定模式的测试,用于保证之前引起问题的 bug 不会再次出现。
- 模拟(Mocking): 使用一个假的实现来替换函数、模块或类型,屏蔽那些和测试不相关的内容。例如,您可能会“模拟网络连接” 或 “模拟硬盘”。
密码学常识部分
熵
用于度量随机性。在密码学中用于确定密码的强度。
哈希函数
在后续的学习中,我们会经常遇见哈希函数生成的加密字符串。其广泛应用在不同项目中。
它将任意大小的输入映射到160位的输出(表示为40个十六进制符)
在命令行中添加 | shalsum,来test一下。
特性
它对于相同的输入具有确定的输出。
但其输出不可逆。
以及由于它的熵的极大,所以它的抗碰撞的能力也很强(也就是找到两个输入其输出相同的情况)。
通常应用于
- 对某个东西进行唯一标识
- 承诺方案:利用随机数进行第一次加密,然后将随机数作为hash的输入,hash输出后与他人进行共享。在验证时,使用该随机数即可。
- 密码加盐就是指加密算法中参数还添加了随机数这一项。比如KDF(秘钥派生函数)其参数为(password,salt,iteration),其中salt=random().
对称加密
及秘钥又为加密者,也为解密者。
非对称加密
生成一对秘钥。其中公钥为解密者,私钥为加密者(用于标记谁进行了加密

 浙公网安备 33010602011771号
浙公网安备 33010602011771号