Python爬虫开发
1 网页请求
requests模块
import requests
#GET请求示例
query = input("请输入你想要查询的内容:")
url = f"https://www.sogou.com/web?query={query}"
UA = {
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:109.0) Gecko/20100101 Firefox/116.0"
}
resp = requests.get(url,headers=UA) #以get方式请求url,赋值给resp
print(resp) #打印出响应的状态码
print(resp.text) #打印出响应的源代码
#POST请求示例
url = "https://fanyi.baidu.com/sug"
s = input("请输入你要翻译的英文单词:")
data1 = {
"kw":s
}
resp = requests.post(url,data=data1)
print(resp.json()) #将服务器返回的内容处理成json格式。
#爬取豆瓣电影排行榜
url = "https://movie.douban.com/j/chart/top_list"
#重新封装参数
params= {
"type": "11",
"interval_id": "100:90",
"action":"",
"start": 0,
"limit": 20,
}
headers = {
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:109.0) Gecko/20100101 Firefox/116.0"
}
resp = requests.get(url,params=params,headers=headers)
#print(resp.request.url) url拼接params后,等价于完整的url
print(resp.json())
resp.close() #关闭爬取使请求头中的keep-alive为off。cookie登录
使用Session()方法
import requests
# 登录网站
session = requests.Session() # 创建一个会话对象
url = "网站的实际登录URL" # 准备登录信息
data = {'username': 'dustfree',
'password': '5678000'
}
resp = session.post(url,data=data) # 登录动作
print(resp.text)
print(resp.cookies)
# 获取登录后の页面响应文本
resp2 = session.get("登录后才能进行访问のURL")
print(resp2.text)
# 进一步进行数据解析
'''
'''
# 关闭会话
session.close()浏览器手工导出cookie
import requests
url = ("https://www.biquxsw.net/modules/article/bookcase.php")
headers = {
"Cookie":"Hm_lvt_dbd0a5819ad389f6d69d1b451da153bc=1694225693,1694228755; Hm_lvt_a71b1bc761fe3f26085e79b5fd6a7f71=1694225693,1694228755; PHPSESSID=re6tuaaihncde317qodsg6pi3l; jieqiUserInfo=jieqiUserId%3D216432%2CjieqiUserUname%3D%CE%E5%C1%F9%C6%DF%B0%CB%C1%E5%C1%E5%C1%E5%2CjieqiUserName%3D%CE%E5%C1%F9%C6%DF%B0%CB%C1%E5%C1%E5%C1%E5%2CjieqiUserGroup%3D3%2CjieqiUserGroupName%3D%C6%D5%CD%A8%BB%E1%D4%B1%2CjieqiUserVip%3D0%2CjieqiUserHonorId%3D%2CjieqiUserHonor%3D%D0%C2%CA%D6%C9%CF%C2%B7%2CjieqiUserPassword%3D2b4ae288a819f2bcf8e290332c838148%2CjieqiUserUname_un%3D%26%23x4E94%3B%26%23x516D%3B%26%23x4E03%3B%26%23x516B%3B%26%23x94C3%3B%26%23x94C3%3B%26%23x94C3%3B%2CjieqiUserName_un%3D%26%23x4E94%3B%26%23x516D%3B%26%23x4E03%3B%26%23x516B%3B%26%23x94C3%3B%26%23x94C3%3B%26%23x94C3%3B%2CjieqiUserHonor_un%3D%26%23x65B0%3B%26%23x624B%3B%26%23x4E0A%3B%26%23x8DEF%3B%2CjieqiUserGroupName_un%3D%26%23x666E%3B%26%23x901A%3B%26%23x4F1A%3B%26%23x5458%3B%2CjieqiUserLogin%3D1694241457; jieqiVisitInfo=jieqiUserLogin%3D1694241457%2CjieqiUserId%3D216432; __gads=ID=885f1acbb2116637-22a6f229c6e300a9:T=1694225758:RT=1694242791:S=ALNI_MaK6hzq4_sstQMcbYQ7c1et3k8c4w; __gpi=UID=00000c3e253de0a7:T=1694225758:RT=1694242791:S=ALNI_MaAIfTbZ1Yz0214KLTHbcUSTm50Jg; jieqiVisitId=article_articleviews%3D153169%7C53547; Hm_lpvt_dbd0a5819ad389f6d69d1b451da153bc=1694243414; Hm_lpvt_a71b1bc761fe3f26085e79b5fd6a7f71=1694243414"
}
resp = requests.get(url, headers=headers)
print(resp.text)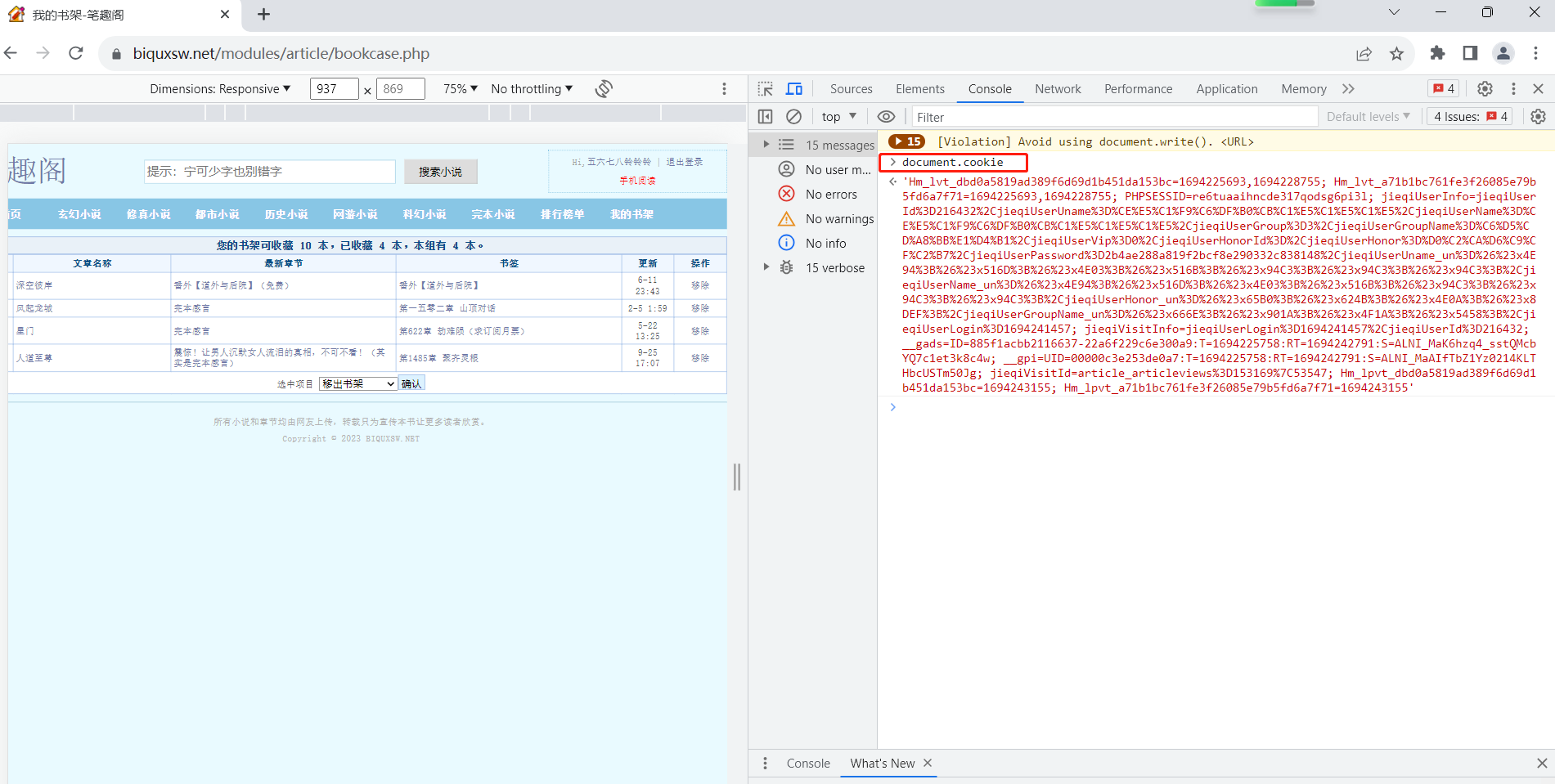
import requests
url = "https://my.jjwxc.net/backend/favorite.php?jsid=69257790-0.010712389183930915"
headers = {
"Cookie":"timeOffset_o=601; bbsnicknameAndsign=1%257E%2529%2524; testcookie=yes; Hm_lvt_bc3b748c21fe5cf393d26c12b2c38d99=1694227312,1694228113,1694232761; smidV2=20230909104152f3c81264b66739c9be9d64f258e08e55000e48661b6a77150; token=NjkyNTc3OTB8ZDlkMzhiMmI3ZmU5Yjg2YmFjMDQ3NDM2ODFlMmUyZmF8fHx8MjU5MjAwMHwxfHx85pmL5rGf55So5oi3fDB8bW9iaWxlfDF8MHx8; bbstoken=NjkyNTc3OTBfMF9iMjI3ZmM4NzQ1OWNhYzc4ZGNkMzJkN2IxM2Y3ZTMxOV8xX19fMQ%3D%3D; JJSESS=%7B%22returnUrl%22%3A%22https%3A//www.jjwxc.net/%22%2C%22sidkey%22%3A%22Dgvq0LiY5ZUcFtPe7p4jExn8TyfBQaAGumoC%22%2C%22clicktype%22%3A%22%22%2C%22bookFavoriteClass%22%3A%22favorite_2%22%7D; Hm_lpvt_bc3b748c21fe5cf393d26c12b2c38d99=1694242461; JJEVER=%7B%22shumeideviceId%22%3A%22WHJMrwNw1k/Hoy9TGPAiMxWmEO/NpqnujFwj6Cbr7WE2lZmSzO65fq9/tsQrSLttw8hI600oYFnQzmULVp4gbZJg4bu4wrWRzdCW1tldyDzmQI99+chXEigVwT8IShlBl27A54gDgTBk3vaAoz2wRe0lBLaZv6y0KU10Rt18csPbSczD/UEAZLqMfY7HcsIljbh4vSnbcMzY2bCBM9cOgFZ1dit9WO+Drze1DK/NrJ9kt3D4brZcBiAUDic6AW2yIixSMW2OQhYo%3D1487582755342%22%2C%22nicknameAndsign%22%3A%22undefined%7E%29%2524%22%2C%22foreverreader%22%3A%2269257790%22%2C%22desid%22%3A%222W/eIjSr7Pdv08Y55vgprayKQda8Lf5l%22%2C%22sms_total%22%3A%222%22%2C%22lastCheckLoginTimePc%22%3A1694241211%2C%22fenzhan%22%3A%22yq%22%2C%22fenpin%22%3A%22bgg.html%22%7D"
}
resp = requests.get(url, headers=headers)
resp.encoding = "gb18030"
print(resp.text)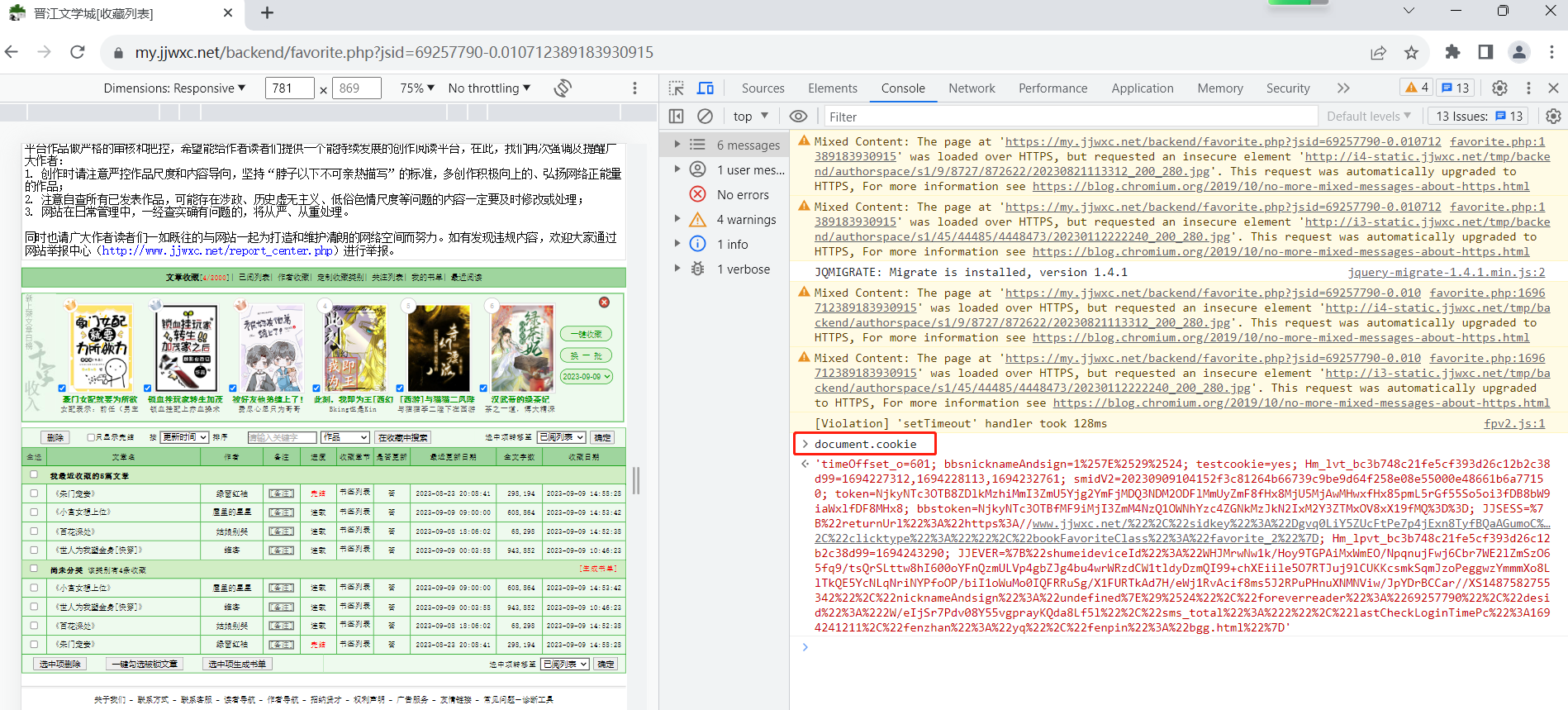
使用代理IP
import requests
url = "https://www.baidu.com"
proxies = {
"http":"106.38.248.189:80"
}
resp = requests.get(url=url, proxies=proxies)
resp.encoding = "utf-8"
print(resp.text)备注:本项目使用以下免费代理IP资源https://www.zdaye.com/free/
国外免费代理IP资源参考https://cn.proxy-tools.com/proxy/us
2 数据解析
re模块
import re
# findall:匹配字符串中所有的符合正则的内容,置于列表中。
lst = re.findall(r"\d+","我的电话号hi:10086,我女朋友的电话是:10010")
print(lst)
# finditer:匹配字符串中所有的内容,置于是迭代器中,从中提取内容使用.group()
it = re.finditer(r"\d+","我的电话号hi:10086,我女朋友的电话是:10010")
print(it)
for i in it:
print(i.group())
#search返回的结果是match对象,从中提取内容使用.group() #只要有一个结果,就只返回一个结果。
s = re.search(r"\d+","我的电话号:10086,我女朋友的电话是:10010")
print(s.group())
# match是从头开始匹配
s = re.match(r"\d+","10086,我女朋友的电话是:10010")
print(s.group())
#预加载正则表达式
obj = re.compile(r"\d+")
ret = obj.finditer("我的电话号:10086,我女朋友的电话是:10010")
for it in ret:
print(it.group())
# 分组匹配:(?P<分组名称>正则表达式)可单独从正则匹配的内容中进一步提取内容
s = """
<div class='老一'><span id='1'>小白狼</span></div>
<div class='老二'><span id='2'>绯夜</span></div>
<div class='老三'><span id='3'>dustfree</span></div>
<div class='老四'><span id='4'>棒棒</span></div>
<div class='老五'><span id='5'>凤凰展翅</span></div>
"""
obj = re.compile(r"<div class='.*?'><span id='(?P<id>\d+)'>(?P<name>.*?)</span></div>", re.S) # re.S可以使.匹配换行符
result = obj.finditer(s)
for resu in result:
pinjie = resu.group("id") + ":" + resu.group("name")
print(pinjie)re模块实战_豆瓣电影top250
import requests
import re
import csv
for num in range(0, 226, 25):
# 发送请求
url = f"https://movie.douban.com/top250?start={num}&filter="
headers = {
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:109.0) Gecko/20100101 Firefox/116.0"
}
resp = requests.get(url,headers=headers)
page_content = resp.text
#print(resp.text)
#解析数据
obj = re.compile(r'<li>.*?<div class="item">.*?<span class="title">(?P<name>.*?)'
r'</span>.*?导演:(?P<director>.*?) .*?<br>(?P<year>.*?) .*?class="rating_num" property="v:average">'
r'(?P<score>.*?)</span>.*?<span>(?P<评价数>.*?)人评价</span>',re.S)
result = obj.finditer(page_content)
#测试能否提取数据成功
for resu in result:
print(resu.group("name"))
print(resu.group("director").strip())
print(resu.group("year").strip())
print(resu.group("score"))
print(resu.group("评价数"))
# 写入数据 一直无法写入或写入乱码,暂未解决。
with open('data.csv', mode='w', encoding='utf-8', newline='') as csvfile:
csvwriter = csv.writer(csvfile)
# 写入表头
csvwriter.writerow(['name', 'director', 'year', 'score', '评价数'])
for resu in result:
dic = resu.groupdict()
dic['year'] = dic['year'].strip()
dic['director'] = dic['director'].strip()
csvwriter.writerow(dic.values())
print("CSV文件写入完成")re模块实战_电影天堂の必看片の下载链接
import requests
import re
#发送请求
pre_url = "https://www.dy2018.com/"
resp = requests.get(pre_url)
resp.encoding = "gb2312"
html_page1 = resp.text
#解析数据
obj1 = re.compile(r"2023必看热片.*?<ul>(?P<duanluo>.*?)</ul>", re.S)
obj2 = re.compile(r"<a href='(?P<href>.*?)'",re.S)
obj3 = re.compile(r'◎片 名(?P<movie>.*?)<br />'
r'.*?<td style="WORD-WRAP: break-word" bgcolor="#fdfddf"><a href="(?P<link>.*?)">magnet', re.S)
result1 = obj1.finditer(html_page1)
url_list = []
for resu in result1:
html_page2 = resu.group("duanluo")
#print(html_page2)
#进一步解析,提取链接的后半部分。
result2 = obj2.finditer(html_page2)
for resu2 in result2:
url = pre_url + resu2.group("href").strip("/")
#print(url)
url_list.append(url) #将组合而成的链接地址保存至列表
#print(url_list)
#进一步提取子页面的内容
for u in url_list:
resp2 = requests.get(u)
resp2.encoding = "gb2312"
html_page3 = resp2.text
#print(html_page3)
#break #测试用
result3 = obj3.search(html_page3)
print(result3.group("movie"))
print(result3.group("link"))bs4模块实战_水果价格
import requests
from bs4 import BeautifulSoup
for num in range(0, 3, 1):
# 发送请求
url = f"http://www.tyhx.com.cn/Web/Price?PageNo={num}"
headers = {
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:109.0) Gecko/20100101 Firefox/116.0"
}
resp = requests.get(url,headers=headers)
#解析数据
page = BeautifulSoup(resp.text, "html.parser") #创建bs4对象并指定html解析器
#table = page.find("table", class_="list1") #为了避讳Python的关键字class,bs4使用class_,也可以使用以下的字典代替
table = page.find("table", attrs={"class":"list1"}) #获取指定の表格
#print(table)
trs = table.find_all("tr")[1:] #获取表格の每一行,赋值给trs
for tr in trs:
tds = tr.find_all("td") #获取每一行の字段们td,赋值给tds
name = tds[0].text #获取被标签标记的内容,赋值给变量name/address/high/low/avg等等。
address = tds[1].text
high = tds[2].text
low = tds[3].text
avg = tds[4].text
print(name,address,high,low,avg)bs4模块实战_美女图片
#程序逻辑:
#1.获取主页源码,提取其中の子页面的链接地址 href
#2.通过href获取子页面源码,提取其中の图片下载链接地址 img-src
#3.下载美女图片
import requests
from bs4 import BeautifulSoup
import time
for num in range(1, 73, 1): #爬取至第5页会报错,暂未解决。
#发送请求
url = f"http://www.umeituku.com/bizhitupian/meinvbizhi/{num}.htm"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:109.0) Gecko/20100101 Firefox/116.0"
}
resp = requests.get(url,headers=headers)
resp.encoding = "utf-8"
#print(resp.text)
#解析数据
main_page = BeautifulSoup(resp.text, "html.parser") #创建bs4对象并指定html解析器
alist = main_page.find("div", class_="TypeList").find_all("a")
#print(alist)
for a in alist:
href = a.get("href") #.get("x")获取标签中x属性的属性值,并赋值给变量。
#print(href)
#进一步发送请求
child_page_resp = requests.get(href)
child_page_resp.encoding = "utf-8"
child_page_text = child_page_resp.text
#print(child_page_text)
#进一步解析数据
child_page = BeautifulSoup(child_page_text, "html.parser")
div = child_page.find("div", class_="ImageBody")
img = div.find("img")
src = img.get("src")
#下载美女图片
img_resp = requests.get(src)
img_name = src.split("/")[-1]
with open("img/"+img_name, mode="wb") as f:
f.write(img_resp.content)
print("SUCCESS!", img_name)
time.sleep(2)
print("All SUCCESS!")xpath模块
from lxml import etree
xml = """
<book>
<id>1</id>
<name>恰饭群英谱</name>
<price>无穷</price>
<nick>帕梅</nick>
<author>
<nick id="10086">小白狼</nick>
<nick id="10010">棒棒</nick>
<nick class="10000">dustfree</nick>
<nick class="12319">绯夜</nick>
<div>
<nick>野马1</nick>
</div>
<span>
<nick>野马2</nick>
<div>
<nick>野马3</nick>
</div>
</span>
</author>
<partner>
<nick id="ppc">玛莎</nick>
<nick id="ppbc">迈巴赫</nick>
</partner>
</book>
"""
tree = etree.XML(xml)
# result = tree.xpath("/book") # /表示层级关系,第一个/是根节点。
# result = tree.xpath("/book/name")
# result = tree.xpath("/book/name/text()") # text()用于获取文本
# result = tree.xpath("/book/author//nick/text()") # // 后代
# result = tree.xpath("/book/author/*/nick/text()") # 文件名通配符*,代表任意节点。
result = tree.xpath("/book//nick/text()")
print(result)from lxml import etree
tree = etree.parse("b.html")
#result = tree.xpath("/html")
#result = tree.xpath("/html/body/ul/li[1]/a/text()") # xpath从1开始数,[]里的数字表示索引
#result = tree.xpath("/html/body/ol/li/a[@href='London']/text()") # [@xx='xx']表示属性の筛选
#print(result)
ol_li_list = tree.xpath("/html/body/ol/li")
for li in ol_li_list:
result = li.xpath("./a/text()")
print(result)
result2 = li.xpath("./a/@href") # @属性 表示获取属性值3
print(result2)
print(tree.xpath("/html/body/ul/li/a/@href"))
#小技巧:可通过浏览器的检查功能,复制现成のxpath进行魔改。
print(tree.xpath('/html/body/div[1]/text()'))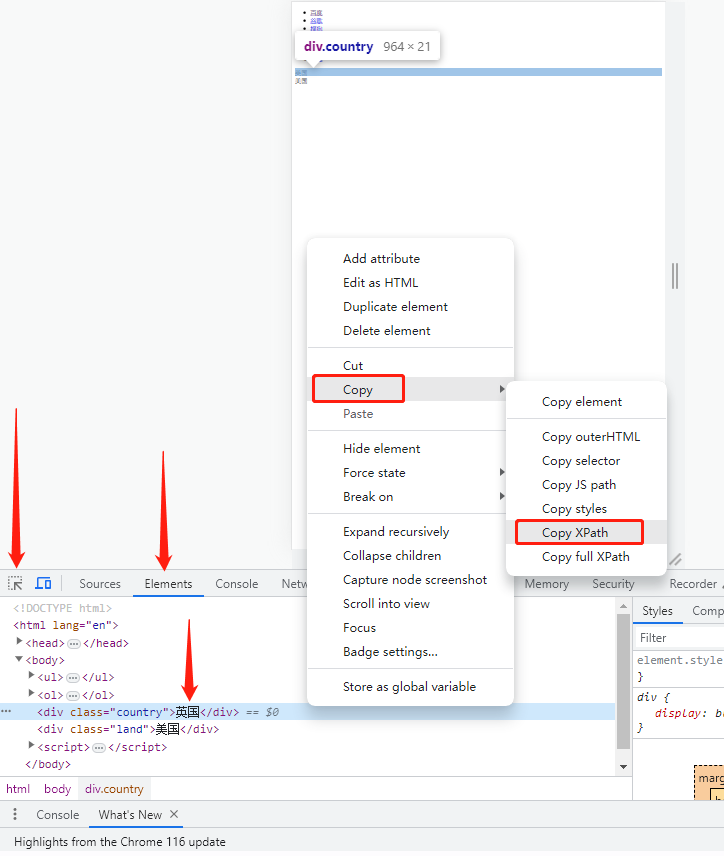
xpath模块实战_猪八戒网
备注:无输出,原因未知。
import requests
from lxml import etree
url = "https://beijing.zbj.com/search/service/?kw=saas"
resp = requests.get(url)
#print(resp.text)
html = etree.HTML(resp.text)
divs = html.xpath("/html/body/div[2]/div/div/div[3]/div/div[4]/div/div[2]/div[1]/div")
for div in divs: #遍历每个服务商信息
price = div.xpath("./div/div[3]/div[1]/span/text()")
title = div.xpath("./div/div[3]/div[2]/a/text()")
com_name = div.xpath("./div/a/div[2]/div[1]/div/text()")
print(price,title,com_name)3 线程、进程、协程
多线程
import threading
# 定义一个简单的函数,用于打印数字
def print_num():
for i in range(10):
print(i)
# 创建五个线程并传递同一个函数作为目标
thread1 = threading.Thread(target=print_num)
thread2 = threading.Thread(target=print_num)
thread3 = threading.Thread(target=print_num)
thread4 = threading.Thread(target=print_num)
thread5 = threading.Thread(target=print_num)
# 启动线程
thread1.start()
thread2.start()
thread3.start()
thread4.start()
thread5.start()
# 等待线程结束
thread1.join()
thread2.join()
thread3.join()
thread4.join()
thread5.join()
print("All threads are done!")线程池
# 程序逻辑: 封装一个可实现单页面爬取功能の函数——将调用函数の任务提交给线程池。
import requests
from concurrent.futures import ThreadPoolExecutor
def download_one_page(url, current):
Form_data = {
"limit": "20",
"current": str(current)
}
resp = requests.post(url, data=Form_data)
json_data = resp.json()
vegetable_list = []
if 'list' in json_data:
for item in json_data['list']:
prodName = item['prodName']
lowPrice = item['lowPrice']
highPrice = item['highPrice']
avgPrice = item['avgPrice']
place = item['place']
pubDate = item['pubDate'].split()[0]
vegetable_list.append((prodName, lowPrice, highPrice, avgPrice, place, pubDate))
print(f"First vegetable name of {current} :",vegetable_list[0][0])
return vegetable_list
if __name__ == '__main__':
url = "http://www.xinfadi.com.cn/getPriceData.html"
with ThreadPoolExecutor(50) as t: # 创建线程池
for current in range(1, 101):
t.submit(download_one_page(url,current)) # 提交任务给线程池
print("OVER!")进程
Python中的进程调用の语法,与线程调用の语法类似。
多任务异步协程
实战之唯美图片下载
import asyncio
import aiohttp # requests模块只支持同步操作。aiohttp模块支持异步操作。
urls = [
"https://i1.huishahe.com/uploads/allimg/202205/9999/281e5e87b0.jpg",
"https://i1.huishahe.com/uploads/allimg/202205/9999/0883978edc.jpg",
"https://i1.huishahe.com/uploads/tu/201906/9999/6297d91768.jpg",
"https://i1.huishahe.com/uploads/tu/201911/9999/85c8311a57.jpg",
"https://i1.huishahe.com/uploads/allimg/202205/9999/cce11863bd.jpg"
]
async def aiodownload(url):
name = url.rsplit("/",1)[1]
async with aiohttp.ClientSession() as session: # 创建aiohttp对象,并赋值给session。 # aiohttp.ClientSession()等价于requests.Session()
async with session.get(url) as resp: # 发送aiohttp请求,得到响应,并赋值给resp。
# 可使用aiofiles模块实现文件读写异步。
with open(name, mode="wb") as f: # 打开文件。
f.write(await resp.content.read()) # 写入文件。写入操作属于异步,需要await挂起。 # content.read()等价于content
print(name, "下载完成!")
async def main(): # 定义一个main()函数,专门用于处理异步协程逻辑。
tasks = [] # 创建一个空列表,用于保存异步协程对象。
for url in urls:
tasks.append(asyncio.create_task(aiodownload(url))) # 调用download()函数,生成异步协程对象。
# tasks = [asyncio.create_task(aiodownload(url)) for url in urls] # 本行代码等价于以上3行代码。
await asyncio.wait(tasks) # 将任务列表添加至异步协程序列。
if __name__ == '__main__':
asyncio.run(main()) # 异步协程运行main()函数。实战之小说下载
'''
# 需求分析:爬取整部小说。
原始url = "https://dushu.baidu.com/pc/reader?gid=4306063500&cid=1569782244"
url0 = 'https://dushu.baidu.com/api/pc/getCatalog?data={"book_id":"4306063500"}'
url1 = 'https://dushu.baidu.com/api/pc/getChapterContent?data={"book_id":"4306063500","cid":"4306063500|1569782244","need_bookinfo":1}'
# 方案设计:
1.通过访问URL1,可以获取某个章节の文本。分析URL1得知,其所需参数为book_id和cid。
2.可以确定的是book_id为固定值,而在访问URL0后得到的json响应包中,正好包含所需核心参数cid。
3.因此,爬取本部小说的逻辑为:首先同步访问URL0,获取所有章节的cid、name;然后异步访问URL1,快速获取小说文本。
'''
# 代码实现
import os
import requests
import asyncio
import aiohttp
import aiofiles
async def getChapterContent(book_id,cid,title):
directory = r"C:\Users\cinaanic\Desktop\pyproject\爬虫code\novel download"
file_name = os.path.join(directory, title + ".txt")
url1 = f'https://dushu.baidu.com/api/pc/getChapterContent?data={{"book_id":"{book_id}","cid":"{book_id}|{cid}","need_bookinfo":1}}'
async with aiohttp.ClientSession() as session: # 创建aiohttp对象,并赋值给session。
async with session.get(url1) as resp: # 发送aiohttp请求,得到响应,并赋值给resp。
json_data = await resp.json()
async with aiofiles.open(file_name, mode="w", encoding="utf-8") as f:
text = json_data['data']['novel']['content']
await f.write(text)
print(title,"下载完成!")
async def getCatalog(url0):
resp = requests.get(url0)
dict = resp.json()
tasks = [] # 创建一个空列表,用于保存异步协程对象。
for item in dict['data']['novel']['items']:
title = item['title']
cid = item['cid']
# 调用getChapterContent()函数,生成异步协程对象并追加存入列表tasks。
tasks.append(asyncio.create_task(getChapterContent(book_id,cid,title)))
# 将任务列表添加至异步协程序列。注意缩进,否则达不到异步协程の效果:异步协程≤3s,非异步协程≥20s。
await asyncio.wait(tasks)
if __name__ == '__main__':
book_id = "4306063500"
url0 = f'https://dushu.baidu.com/api/pc/getCatalog?data={{"book_id":"{book_id}"}}'
asyncio.run(getCatalog(url0))4 selenium模拟人工操作浏览器
模拟定位、点击、输入文本、回车、切换窗口
# 下载浏览器及其对应驱动程序:https://commondatastorage.googleapis.com/chromium-browser-snapshots/index.html?prefix=Win_x64/1177694/
# 请把驱动程序解压后置于Python解释器同一目录中。
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
import time
url = "https://www.lagou.com/"
brower = webdriver.Chrome() # 创建Chrome浏览器对象
brower.get(url) # 调用Chrome访问url
el = brower.find_element(By.XPATH, "/html/body/div[10]/div[1]/div[2]/div[2]/div[1]/div/ul/li[9]/a") # 定位指定の网页元素
el.click() # 操作:点击事件
el2 = brower.find_element(By.XPATH, "/html/body/div[7]/div[1]/div[1]/div[1]/form/input[1]") # 定位指定の网页元素
el2.send_keys("python", Keys.ENTER) # 操作:搜索框中输入内容并回车
brower.minimize_window() # 最小化Chrome窗口
brower.maximize_window() # 最大化Chrome窗口
time.sleep(3) # 让Chrome休息一会儿,等待网络加载
print(brower.page_source) # 获取动态加载后的页面HTML源码——即浏览器开发者工具中Elements中的所有内容,而非右键直接查看页面源码。
list = brower.find_elements(By.XPATH, "/html/body/div/div[2]/div/div[2]/div[3]/div/div[1]/div") # 定位指定の网页元素
for l in list:
job_name = l.find_element(By.XPATH, "./div[1]/div[1]/div[1]/a").text # 定位指定の网页元素并提取文本
job_price = l.find_element(By.XPATH, "./div[1]/div[1]/div[2]/span").text # 定位指定の网页元素并提取文本
job_company = l.find_element(By.XPATH, "./div[1]/div[2]/div[1]/a").text # 定位指定の网页元素并提取文本
print(job_name,job_price,job_company)
# 找到第一条,点击。 # xpath表达式明明正确,却一直报错,真TMD奇葩!
el3 = brower.find_element(By.TAG_NAME, "/html/body/div[1]/div[2]/div/div[2]/div[3]/div/div[1]/div[1]/div[1]/div[1]/span/div/div[1]/a") # 定位指定の网页元素
el3.click() # 操作:点击事件。这时将打开一个新标签页
brower.switch_to.window(brower.window_handles[-1]) # 切换到新标签页
el4 = brower.find_element(By.XPATH, "/html/body/div[1]/div[2]/div[2]/div[1]/dl[1]/dd[2]/div") # 定位指定の网页元素
job_detail = el4.text # 操作:提取文本
print(job_detail)
brower.close() # 关掉新标签页
brower.switch_to.window(brower.window_handles[0]) # 切换到主窗口
time.sleep(30) # 让Chrome保持不退出状态30s,否则chrom会立刻关闭模拟下拉菜单;启用静默模式、webdriver反爬
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.support.select import Select
from selenium.webdriver.chrome.options import Options
import time
# 创建配置对象,设定相关配置参数
opt = webdriver.ChromeOptions() # 创建配置对象
opt.add_argument('--headless') # 启用静默模式
opt.add_argument('--disable-gpu') # 禁用GPU加速,适用于部分环境
# 反爬手段:禁用webdriver属性,隐藏受自动化软件控制の特征(chrome的版本大于等于88时,在console中执行window.navigator.webdriver=false)。
opt.add_argument('--disable-blink-features=AutomationControlled')
# 创建Chrome浏览器对象,并使配置生效
brower = webdriver.Chrome(options=opt)
# 调用Chrome访问url
url = "http://www.gkong.com/co/delta/index_solution.asp"
brower.get(url)
# 定位至搜索框
el = brower.find_element(By.XPATH, "/html/body/table[4]/tbody/tr/td[1]/table[2]/tbody/tr[2]/td/input")
el.send_keys("电源") # 操作:搜索框中输入内容
# 定位至下拉框
el2 = brower.find_element(By.XPATH, "/html/body/table[4]/tbody/tr/td[1]/table[2]/tbody/tr[3]/td/select")
sel = Select(el2) # 包装成Select下拉菜单对象
sel.select_by_value("2") # 按照value值进行切换
# 定位至查找按钮
el3 = brower.find_element(By.XPATH, "/html/body/table[4]/tbody/tr/td[1]/table[2]/tbody/tr[4]/td/input")
el3.click() # 操作:点击事件
time.sleep(2)
# 定位至table
table = brower.find_element(By.XPATH, "/html/body/table[4]/tbody/tr/td[2]/table[1]")
print(table.text)
print("========================================================")
# 以下代码片段想使用for i in range(len(sel.options)):进行遍历,却在18行sel.select_by_value一直报错,使用sel.select_by_index也是如此。
# 定位至下拉框
el2 = brower.find_element(By.XPATH, "/html/body/table[4]/tbody/tr/td[1]/table[2]/tbody/tr[3]/td/select")
sel = Select(el2) # 包装成Select下拉菜单对象
sel.select_by_value("4") # 按照value值进行切换
# 定位至查找按钮
el3 = brower.find_element(By.XPATH, "/html/body/table[4]/tbody/tr/td[1]/table[2]/tbody/tr[4]/td/input")
el3.click() # 操作:点击事件
time.sleep(2)
# 定位至table
table = brower.find_element(By.XPATH, "/html/body/table[4]/tbody/tr/td[2]/table[1]")
print(table.text)
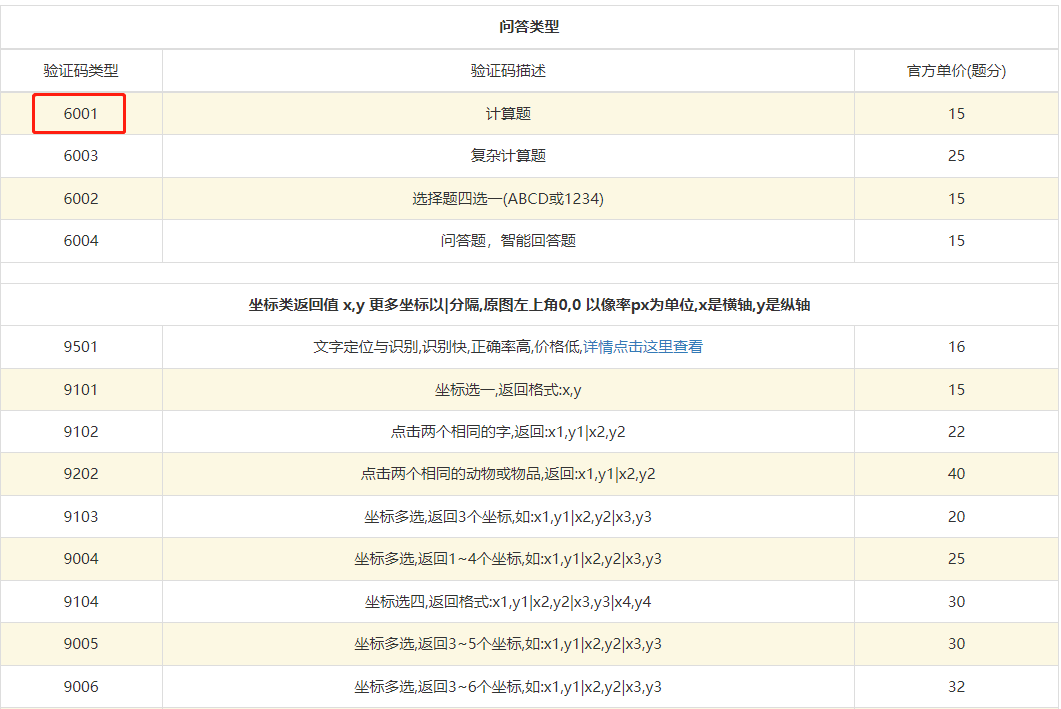
print("========================================================")验证码自动化识别(调用超级鹰接口)
4位数字字母
# 笔趣阁自动化登录
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.chrome.options import Options
import time
from chaojiying import Chaojiying_Client
# 创建配置对象,设定相关配置参数
opt = webdriver.ChromeOptions() # 创建配置对象
# 反爬手段:禁用webdriver属性,隐藏受自动化软件控制の特征(chrome的版本大于等于88时,在console中执行window.navigator.webdriver=false)。
opt.add_argument('--disable-blink-features=AutomationControlled')
# 创建Chrome浏览器对象,并使配置生效
brower = webdriver.Chrome(options=opt)
# 调用Chrome访问url
url = "https://www.biquxsw.net/login.php"
brower.get(url)
time.sleep(3)
# 填入账户密码
el1 = brower.find_element(By.XPATH,"//html/body/div[2]/div/form/table/tbody/tr[1]/td/table/tbody/tr[1]/td[2]/input") # 定位至账户框
el2 = brower.find_element(By.XPATH,"/html/body/div[2]/div/form/table/tbody/tr[1]/td/table/tbody/tr[2]/td[2]/input") # 定位至密码框
el1.send_keys("******") # 操作:输入笔趣阁账户:五六七八铃铃铃
el2.send_keys("******") # 操作:输入笔趣阁密码:******
# 识别验证码
el3 = brower.find_element(By.XPATH,"/html/body/div[2]/div/form/table/tbody/tr[1]/td/table/tbody/tr[3]/td[2]/img") # 定位至验证码图片处
img = el3.screenshot_as_png # 获取验证码图片の字节
# 登录、调用超级鹰查询接口
chaojiying = Chaojiying_Client('你的超级鹰账户', '你的超级鹰密码', '你的超级鹰软件ID')
dict = chaojiying.PostPic(img, 1902)
verify_code = dict['pic_str'] # 获取验证码值
# 输入验证码
el4 = brower.find_element(By.XPATH,"/html/body/div[2]/div/form/table/tbody/tr[1]/td/table/tbody/tr[3]/td[2]/input")
el4.send_keys(verify_code)
time.sleep(3)
# 点击登录
el5 = brower.find_element(By.XPATH,"/html/body/div[2]/div/form/table/tbody/tr[1]/td/table/tbody/tr[5]/td[2]/input") # 定位至登录按钮
el5.click() # 操作:点击登录
time.sleep(300)4位数字字母_超级鹰干超级鹰
# 用超级鹰干超级鹰
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.chrome.options import Options
import time
from chaojiying import Chaojiying_Client
# 创建配置对象,设定相关配置参数
opt = webdriver.ChromeOptions() # 创建配置对象
# 反爬手段:禁用webdriver属性,隐藏受自动化软件控制の特征(chrome的版本大于等于88时,在console中执行window.navigator.webdriver=false)。
opt.add_argument('--disable-blink-features=AutomationControlled')
# 创建Chrome浏览器对象,并使配置生效
brower = webdriver.Chrome(options=opt)
# 调用Chrome访问url
url = "https://www.chaojiying.com/user/login/"
brower.get(url)
time.sleep(3)
# 填入账户密码
el1 = brower.find_element(By.XPATH,"/html/body/div[3]/div/div[3]/div[1]/form/p[1]/input") # 定位至账户框
el2 = brower.find_element(By.XPATH,"/html/body/div[3]/div/div[3]/div[1]/form/p[2]/input") # 定位至密码框
el1.send_keys("你的超级鹰账户") # 操作:输入账户
el2.send_keys("你的超级鹰密码") # 操作:输入密码
# 识别验证码
el3 = brower.find_element(By.XPATH,"/html/body/div[3]/div/div[3]/div[1]/form/div/img") # 定位至验证码图片处
img = el3.screenshot_as_png # 获取验证码图片の字节
# 登录、调用超级鹰查询接口
chaojiying = Chaojiying_Client('你的超级鹰账户', '你的超级鹰密码', '你的超级鹰软件ID')
dict = chaojiying.PostPic(img, 1902)
verify_code = dict['pic_str'] # 获取验证码值
# 输入验证码
el4 = brower.find_element(By.XPATH,"/html/body/div[3]/div/div[3]/div[1]/form/p[3]/input")
el4.send_keys(verify_code)
time.sleep(3)
# 点击登录
el5 = brower.find_element(By.XPATH,"/html/body/div[3]/div/div[3]/div[1]/form/p[4]/input") # 定位至登录按钮
el5.click() # 操作:点击登录
time.sleep(300)算术运算
# 暴露面管理平台自动化登录
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.chrome.options import Options
import time
from chaojiying import Chaojiying_Client
# 创建配置对象,设定相关配置参数
opt = webdriver.ChromeOptions() # 创建配置对象
# 反爬手段:禁用webdriver属性,隐藏受自动化软件控制の特征(chrome的版本大于等于88时,在console中执行window.navigator.webdriver=false)。
opt.add_argument('--disable-blink-features=AutomationControlled')
# 创建Chrome浏览器对象,并使配置生效
brower = webdriver.Chrome(options=opt)
# 调用Chrome访问url
url = "暴露面管理平台地址"
brower.get(url)
time.sleep(5)
# 填入账户密码
el1 = brower.find_element(By.XPATH,"/html/body/div/div/div[1]/div[2]/div/div/form/div[1]/div/div/input") # 定位至账户框
el2 = brower.find_element(By.XPATH,"//html/body/div/div/div[1]/div[2]/div/div/form/div[2]/div/div/input") # 定位至密码框
el1.send_keys("********") # 操作:输入账户
el2.send_keys("********") # 操作:输入密码
# 识别验证码
el3 = brower.find_element(By.XPATH,"/html/body/div/div/div[1]/div[2]/div/div/form/div[3]/div/div/div[2]/img") # 定位至验证码图片处
img = el3.screenshot_as_png # 获取验证码图片の字节
# 登录、调用超级鹰查询接口
chaojiying = Chaojiying_Client('你的超级鹰账户', '你的超级鹰密码', '你的超级鹰soft_id')
dict = chaojiying.PostPic(img, 6001) # 6001:参考超级鹰定义的识别类型
verify_code = dict['pic_str'] # 获取验证码值
# 输入验证码
el4 = brower.find_element(By.XPATH,"/html/body/div/div/div[1]/div[2]/div/div/form/div[3]/div/div/div[1]/div/input")
el4.send_keys(verify_code)
time.sleep(3)
# 点击登录
el5 = brower.find_element(By.XPATH,"/html/body/div/div/div[1]/div[2]/div/div/form/div[4]/div/button") # 定位至登录按钮
el5.click() # 操作:点击登录
time.sleep(300)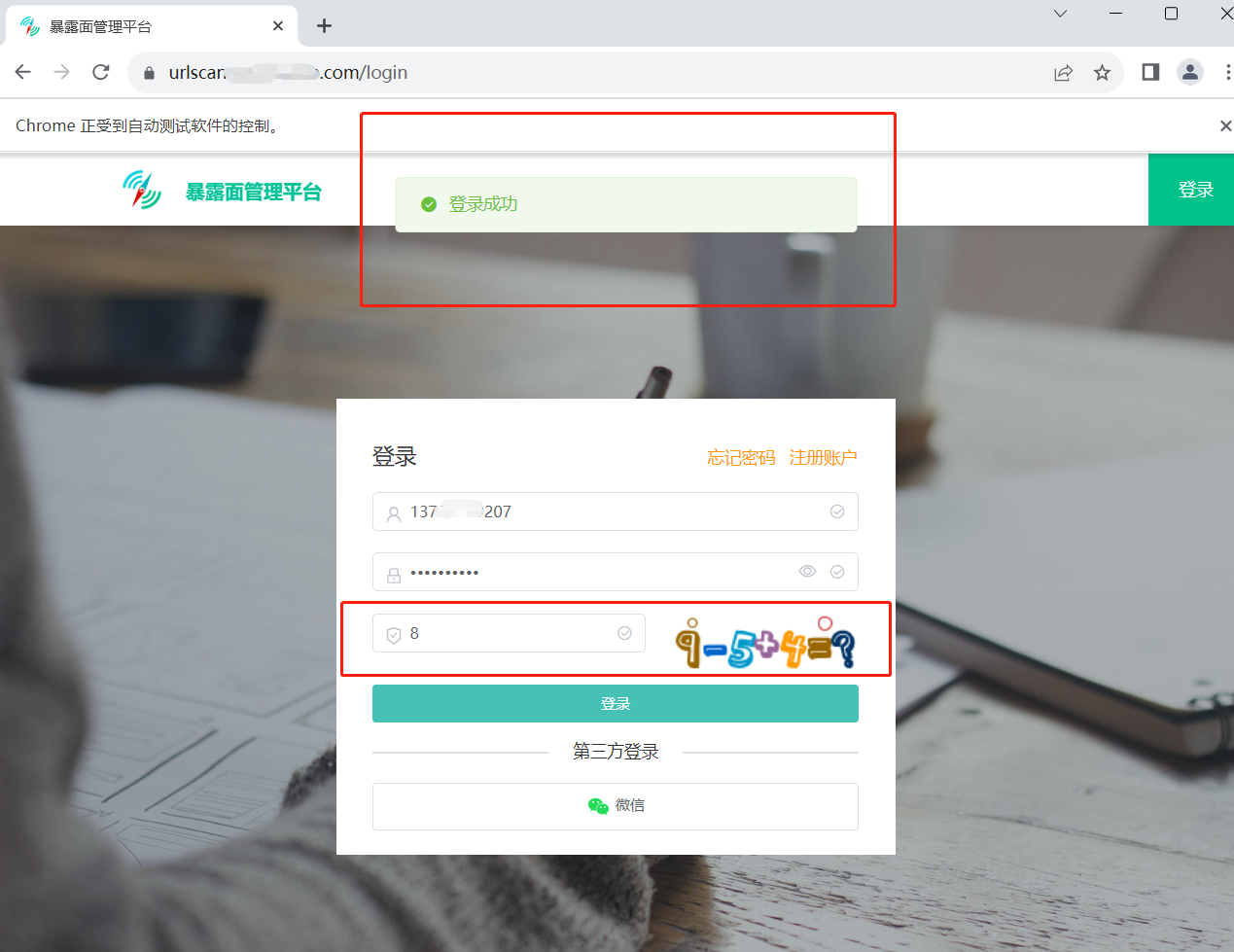
识图点击(错误率高)
# 晋江文学城自动化登录
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.action_chains import ActionChains
from selenium.webdriver.chrome.options import Options
import time
from chaojiying import Chaojiying_Client
# 创建配置对象,设定相关配置参数
opt = webdriver.ChromeOptions() # 创建配置对象
# 反爬手段:禁用webdriver属性,隐藏受自动化软件控制の特征(chrome的版本大于等于88时,在console中执行window.navigator.webdriver=false)。
opt.add_argument('--disable-blink-features=AutomationControlled')
# 创建Chrome浏览器对象,并使配置生效
brower = webdriver.Chrome(options=opt)
# 调用Chrome访问url
url = "https://www.jjwxc.net/"
brower.get(url)
time.sleep(3)
# 点击登入
el0 = brower.find_element(By.XPATH,"/html/body/div[3]/div[3]/div/div[4]/a[1]")
el0.click()
# 填入账户密码
el1 = brower.find_element(By.XPATH,"/html/body/div[9]/div[3]/div[3]/div[2]/div[2]/form/div[1]/div[1]/p[1]/input") # 定位至账户框
el2 = brower.find_element(By.XPATH,"/html/body/div[9]/div[3]/div[3]/div[2]/div[2]/form/div[1]/div[1]/p[2]/input") # 定位至密码框
el1.send_keys("********") # 操作:输入账户
el2.send_keys("********") # 操作:输入密码
time.sleep(3)
# 识别验证码
el3 = brower.find_element(By.XPATH,"/html/body/div[9]/div[3]/div[3]/div[2]/div[2]/form/div[2]/div[1]/div/div/div[1]/div[3]/div/img") # 定位至验证码图片处
img = el3.screenshot_as_png # 获取验证码图片の字节
# 登录、调用超级鹰查询接口
chaojiying = Chaojiying_Client('你的超级鹰账户', '你的超级鹰密码', '你的超级鹰soft_id')
dict = chaojiying.PostPic(img, 9004) # 9004:参考超级鹰定义的识别类型
zuobiao = dict['pic_str'] # 获取验证码坐标:x1,y1|x2,y2|x3,y3
# 提取坐标偏移量,事件链带着偏移量执行点击、提交
zuobiao_list = zuobiao.split("|") # 过滤坐标,只保留数字、逗号
for rs in zuobiao_list: # x1,y1
p_temp = rs.split(",") # 继续过滤坐标,只保留数字
x = int(p_temp[0]) # x1
y = int(p_temp[1]) # y1
ActionChains(brower).move_to_element_with_offset(el3,x,y).click().perform() # 带着偏移量执行点击、提交
time.sleep(3)
# 点击登录
el6 = brower.find_element(By.XPATH,"/html/body/div[9]/div[3]/div[3]/div[2]/div[2]/form/div[2]/div[2]/input") # 定位至协议勾选框
el6.click() # 操作:点击勾选
el5 = brower.find_element(By.XPATH,"/html/body/div[9]/div[3]/div[3]/div[2]/div[2]/form/div[2]/div[4]/button") # 定位至登录按钮
el5.click() # 操作:点击登录
time.sleep(300)滑块拖拽 {"Status":"Waiting Update"}
拖拽到底:
huakuai = brower.find_element(By.XPATH,"滑块のXpath")
ActionChains(brower).drag_and_drop_by_offset(huakuai,300,0).perform()拖拽到指定图框:
5 Scrapy企业级爬虫框架 {"Status":"No Update Plan"}
* 应用实例_爬取video
下载梨视频video
# 爬取video程序の逻辑:
# 1.播放video,检查页面,找出videoの播放状态のURL。
# 2.刷新页面,找出videoの停止播放状态のURL,观察请求响应文本,找出与播放状态のURL类似的URL,对比二者之间的差异。
# 3.拼接出videoの播放状态のURL,涉及以下参数:contId、systemTime、cont-{contId}
# 4.下载video。
# videoの正常访问URL = "https://www.pearvideo.com/video_1100878”
# videoの播放状态の可访问URL = "https://video.pearvideo.com/mp4/short/20170628/cont-1100878-10579405-hd.mp4"
# videoの停止播放状态の可访问URL = "https://www.pearvideo.com/videoStatus.jsp?contId=1100878&mrd=0.7072643950777905"
# 与videoの播放状态の可访问URL类似的URL = "https://video.pearvideo.com/mp4/short/20170628/1694248080439-10579405-hd.mp4"
import requests
# 发送请求
Normal_url = "https://www.pearvideo.com/video_1100878"
contId = Normal_url.split('_')[1] # print(contId) 将输出videoの代号1100878
headers = {
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:109.0) Gecko/20100101 Firefox/117.0",
"Referer":Normal_url # 防盗链处理
}
video_stop_Url = f"https://www.pearvideo.com/videoStatus.jsp?contId={contId}&mrd=0.7072643950777905"
resp = requests.get(video_stop_Url, headers=headers)
# 拼接过程
dic = resp.json()
srcUrl = dic['videoInfo']['videos']['srcUrl'] # 获取与播放状态のURL类似的URL
systemTime = dic['systemTime'] # 获取systemTimeの值,用于稍后进行替换
srcUrl = srcUrl.replace(systemTime, f"cont-{contId}") # 将systemTimeの值替换成cont-{contId}
print(srcUrl) # 获取最终のURL,即videoの播放状态のURL
# 下载视频
with open("1.mp4", mode="wb") as f:
f.write(requests.get(srcUrl).content)
print("Download Success!")下载麻豆video
"""
# 需求分析:爬取整部video。
# 站点分析:人工分析过程(略)。
# 方案设计:
1.访问原始url = "https://{麻豆域名}/mdx0270-%E6%B0%B4%E7%94%B5%E5%B8%88%E5%82%85%E7%9A%84%E6%AD%A2%E6%B0%B4%E7%A7%81%E6%B4%BB-%E6%B7%AB%E9%AD%85%E5%90%B8%E8%88%94%E5%8F%96%E7%B2%BE.html"
2.通过原始url,获取播放器dash_url = "https://dash.{麻豆域名}/share/64ec788eb377e4139defb9b2"
3.通过dash_url,获取到m3u8的构成要素——m3u8路径、token:
/videos/64ec788eb377e4139defb9b2/index.m3u8
token=eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJhY2Nlc3MiOiJ2aWV3IiwiaWF0IjoxNjk0NjUxNDMzLCJleHAiOjE2OTQ2NTE1MzN9.amvuNXC5tQ-cGs9Zvt49aqK69FO3tTH5B0Agr1AXOZ8
4.将以上要素拼接成m3u8_url:
m3u8_url = "https://dash.{麻豆域名}/videos/64ec788eb377e4139defb9b2/index.m3u8?token=eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJhY2Nlc3MiOiJ2aWV3IiwiaWF0IjoxNjk0NjUwMDU2LCJleHAiOjE2OTQ2NTAxNTZ9.N-PAyW5Sm_DJoY6QXyuQ2K8y8kj-D_wAkAsVj5Wx34g"
5.访问m3u8_url,获取m3u8文件。
6.解析m3u8文件,过滤出纯净的.ts文件集合,访问,拼接成video文件。
# 备注:需挂上自己的美国代理IP方可成功,使用机场访问失败。
# 备注:将{麻豆域名}替换成你知道的麻豆URL
"""
# 代码实现
import os
import re
import requests
# 生成本地m3u8文件。
def generate_m3u8_file(url):
# 访问url,提取出dash_url
resp = requests.get(url, headers=headers)
resp.encoding = "utf-8"
pattern1 = r'<iframe height=720 width=1280 src=(https://\S+) frameborder=0'
match1 = re.search(pattern1, resp.text)
global dash_url
dash_url = match1.group(1)
# 访问dash_url,提取出m3u8路径、token,拼接成为m3u8_url
resp2 = requests.get(dash_url, headers=headers)
resp.encoding = "utf-8"
pattern2 = r'var token = "(.*?)";'
match2 = re.search(pattern2, resp2.text)
token = match2.group(1)
pattern3 = r"var m3u8 = '(.*?)';"
match3 = re.search(pattern3, resp2.text)
global m3u8_path
m3u8_path = match3.group(1)
new_dash_url = "/".join(dash_url.split("/")[:3]) # 提取出https://dash.{麻豆域名}
m3u8_url = new_dash_url + m3u8_path + "?token=" +token # 拼接m3u8_url
# 访问m3u8_url,将结果写入文件
resp3 = requests.get(m3u8_url)
with open(m3u8_file_name, mode="wb") as f:
f.write(resp3.content)
print("成功生成m3u8文件!")
# 生成ts_url文件。
def generate_ts_url_file():
# 切割并合并dash_url、m3u8_path
cut = dash_url.split('/')
cut_dash_url = f"https://{cut[2]}"
cut_m3u8_path = m3u8_path.split("/index.m3u8")[0]
pre_hebing_url = cut_dash_url + cut_m3u8_path
# print(pre_hebing_url)
# 过滤m3u8文件,去除以'#'开头的行。拼接成ts_url。
with open(m3u8_file_name, "r", encoding='utf-8') as f:
lines = f.readlines()
for line in lines:
line = line.strip() # 去除空格
if line.startswith("#"): # 去除以"#"开头的行
continue
global ts_url
ts_url = pre_hebing_url + "/" + line + "\n" # 生成ts_url
# print(ts_url)
with open(ts_url_name, "a") as f:
f.write(ts_url)
print("成功生成ts_url文件!")
# 下载ts_file,可考虑使用异步协程。
def download_ts_file():
with open(ts_url_name, mode="r", encoding="utf-8") as f:
n = 0
for line in f:
ts_file_name = os.path.join(directory, f"第{n}个.ts")
line = line.strip()
resp = requests.get(line)
with open(ts_file_name, "wb") as file:
file.write(resp.content)
print(f"下载到第{n}个了!")
n += 1
if __name__ == '__main__':
url = input("请输入你想要下载的麻豆video url:")
headers = {
"User-Agent": "Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/116.0.0.0 Mobile Safari/537.36"
}
directory = r"C:\Users\cinaanic\Desktop\pyproject\爬虫code\videos" # 替换成你的video下载目录
m3u8_file_name = os.path.join(directory, "m3u8.m3u8")
ts_url_name = os.path.join(directory, "ts_url.m3u8")
# 调用函数
generate_m3u8_file(url)
generate_ts_url_file()
download_ts_file()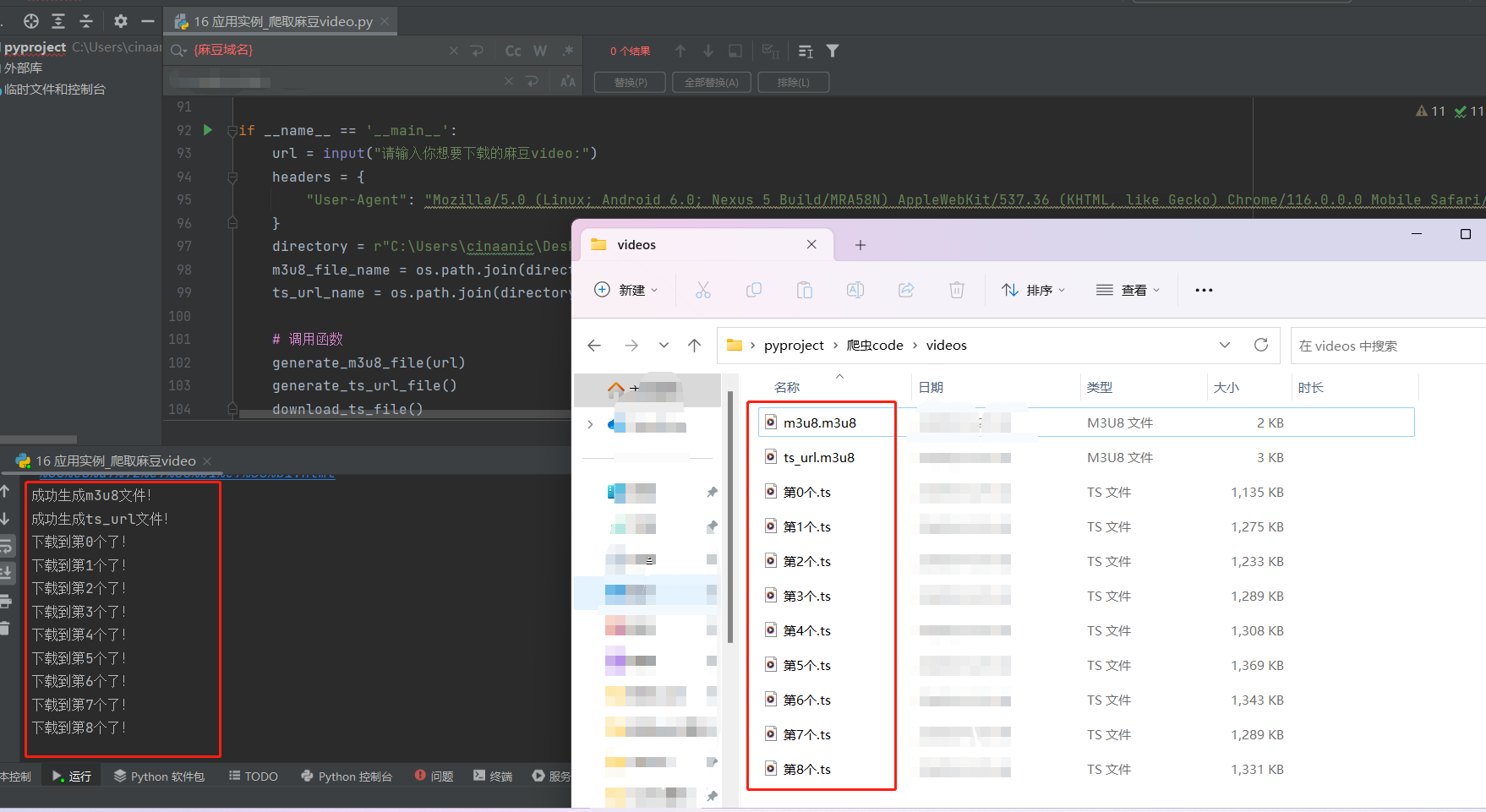
下载美剧video {"Status":"Waiting Update"}
# 其它美剧网站 = https://www.kanjuw.net/video/?247084-4-6.html
# 其它美剧网站 = https://www.kan-ju.com/video/?234205-4-6.html
'''
https://www.91mjtv.com/meiju/quanlideyouxidierji/1-7.html
https://vip.ffzy-play.com/20221211/33261_d4f7c459/index.m3u8
https://vip.ffzy-play.com/20221211/33261_d4f7c459/2000k/hls/mixed.m3u8
https://vip.ffzy-play.com/20221211/33261_d4f7c459/2000k/hls/af4decae096000059.ts
https://code.feifeicms.co/player.demo/dplayer.php?v=4.1&url=https%3A%2F%2Fvip.ffzy-play.com%2F20221211%2F33261_d4f7c459%2Findex.m3u8&t=1694609687&sign=3a8b47352a879d09e887bb7d42f4ff7e
v: 4.1
url: https://vip.ffzy-play.com/20221211/33261_d4f7c459/index.m3u8
t: 1694609687
sign: 3a8b47352a879d09e887bb7d42f4ff7e
'''
# 代码实现
import requests
url = "https://www.91mjtv.com/meiju/quanlideyouxidierji/1-7.html"
headers = {
"User-Agent":"Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/116.0.0.0 Mobile Safari/537.36"
}
m3u8_url = "https://vip.ffzy-play.com/20221211/33261_d4f7c459/index.m3u8"
resp = requests.get(m3u8_url, headers=headers)
resp.encoding = "utf-8"
print(resp.text) # 获取"2000k/hls/mixed.m3u8"
all_m3u8_url = "https://vip.ffzy-play.com/20221211/33261_d4f7c459/2000k/hls/mixed.m3u8"
# 下载.ts文件
# 合并.ts文件备注:在线工具网址https://zh.savefrom.net/ 可下载YouTube视频。此工具也可以插件形式Install to Chrome,效果更佳!
在线工具网址https://video-converter.com/cn/可提取出视频中的音频。
* 应用实例_Excel文件操作
使用openpyxl模块将数据写入Excel文件
import requests
import openpyxl
def download_one_page(url, current):
Form_data = {
"limit": "20",
"current": str(current) # 将current值转换为字符串
}
resp = requests.post(url, data=Form_data)
json_data = resp.json() # 解析JSON数据
vegetable_list = [] # 创建一个空列表来存储提取的数据
if 'list' in json_data:
for item in json_data['list']:
prodName = item['prodName']
lowPrice = item['lowPrice']
highPrice = item['highPrice']
avgPrice = item['avgPrice']
place = item['place']
pubDate = item['pubDate'].split()[0]
# 将提取的数据作为元组添加到vegetable_list中
vegetable_list.append((prodName, lowPrice, highPrice, avgPrice, place, pubDate))
print(f"Downloaded data for Page: {current}")
return vegetable_list
def save_to_excel(data, filename):
try:
workbook = openpyxl.load_workbook(filename)
sheet = workbook.active
except FileNotFoundError:
workbook = openpyxl.Workbook()
sheet = workbook.active
sheet['A1'] = '产品名称'
sheet['B1'] = '最低价格'
sheet['C1'] = '最高价格'
sheet['D1'] = '平均价格'
sheet['E1'] = '产地'
sheet['F1'] = '发布日期'
for idx, row_data in enumerate(data, start=sheet.max_row + 1):
sheet[f'A{idx}'] = row_data[0]
sheet[f'B{idx}'] = row_data[1]
sheet[f'C{idx}'] = row_data[2]
sheet[f'D{idx}'] = row_data[3]
sheet[f'E{idx}'] = row_data[4]
sheet[f'F{idx}'] = row_data[5]
workbook.save(filename)
if __name__ == '__main__':
url = "http://www.xinfadi.com.cn/getPriceData.html"
for current in range(1, 11): # current的值从1到200循环
vegetable_data = download_one_page(url, current)
filename = 'vegetable.xlsx'
save_to_excel(vegetable_data, filename)
print("成功写入Excel文件!")
------------------------------------------------------------------------------------------------------------------------------------
爬虫初识
#爬虫定义:一组模拟浏览器上网、抓取数据的代码。
#爬虫分类(根据使用场景):
1.通用爬虫:抓取系统的重要组成部分,通常抓取一整张页面数据。搜索引擎。
2.聚焦爬虫:建立在通用爬虫的基础上,通常抓取页面中的局部内容。
3.增量爬虫:监测网站更新情况。抓取网站的更新内容。
#爬虫与反爬(略)
UA检测与UA伪装
#http/https协议
#常用请求头:
User-Agent:当前请求载体的身份标识。
Connection:请求完毕后,是断开连接还是保持连接。
#常用响应头:
Content-Type:服务器响应客户端的数据类型。
#加密方式
1.对称秘钥加密 缺点:客户端生成秘钥,易被拦截。
2.非对称秘钥加密 缺点:效率低、公钥易被篡改。
3.证书秘钥加密 CA数字证书、
web请求流程
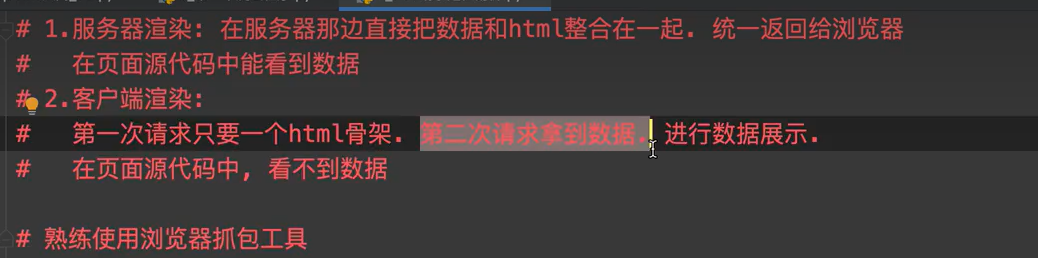
#浏览器发起请求の步骤(requests模块的编码流程)
1.指定URL
2.发起请求
3.获取响应数据
4.持久化存储
#环境安装:
pip install requests 或者 pycharm设置——python解释器——添加包
#编程练习:
1.搜狗首页:将搜狗首页的html页面下载至本地。 知识点:requests基本功能
2.简易网页采集器:爬取搜狗搜索指定词条的结果页面。 知识点:UA伪装
3.破解百度翻译:根据百度翻译的Ajax局部刷新特性,透过非数据分析手段爬取局部数据。 知识点:发送post请求、处理json格式的响应数据
4.爬取豆瓣电影排行榜:依然Ajax 知识点:同上
5.爬取肯德基餐厅位置:依然Ajax 知识点:同上
#聚焦爬虫编码流程:
1.指定url
2.发起请求
3.获取响应数据
4.数据解析
5.持久化存储数据解析方法
#数据解析原理:解析的局部文本内容,均在标签之间或标签对应的属性中存储。
1.对指定标签进行定位
2.对标签之间或标签对应的属性中存储的值进行提取。
RE语法
RE,英文为Regular Expression,中文译作正则表达式。是用于文本过滤的工具。进行逐行扫描,满足条件的被整行显示。
RE语法由一些元字符、其它任意字符串作为基本单元,匹配次数、边界锚定符、分组匹配等作为操作单元组成。
基本单元
- 元字符:例如
.、\d、\w、\s等,用于匹配特定类型的字符,如数字、字母、空白字符等。 - 字面值字符:例如字母、数字、空格等,可以直接匹配它们自身。
- 字符类:用方括号
[ ]包围的字符集合,用于匹配方括号内的任意一个字符。
操作单元
- 匹配次数
*
+
?
{m}- 边界锚定符:例如
^、$、\b、\B等,用于匹配字符串的开头、结尾或单词边界位置。 #常用于表单验证锚定手机号等。 - 分组匹配group:······代耕
常用RE
.* 贪婪匹配,即尽可能多地匹配
.*? 惰性匹配,即尽可能少地匹配
RE模块
import re
#re模块的语法
eg: m=re.search('[0-9]','abcd4ef')
re.search(pattern,string) 搜索整个string,直到发现符合pattern的结果。
re.sub(pattern,replacement,string) 搜索整个string,直到发现符合pattern的结果,再将结果使用replacement进行替换。
re.split() 根据正则表达式分割字符串,将分割后的字符串置于一个list中。
re.findall() 根据正则表达式搜索字符串,将符合条件的字符串置于一个list中。
print(变量.group(0)) 查看匹配后の结果
#re模块运用示例
content = 'abcd_output_1994_abcd_1912_abcd'
zz= 'output_\d{4}'
m = re.search(zz,content)
print(m.group()) #将打印output_1994
content = 'abcd_output_1994_abcd_1912_abcd'
zz= 'output_(\d{4})'
m = re.search(zz,content)
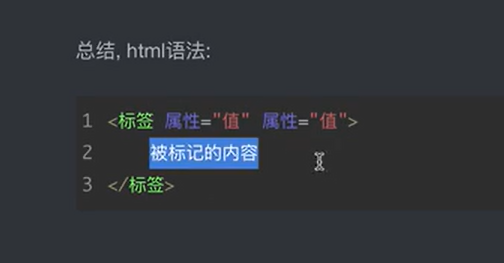
print(m.group(1)) #将打印1994bs4前置知识:
xpath前置知识:
Xpath 是XML文档中搜索内容的一门语言。而HTML是XML的一个子集。
名词:节点、父节点、子节点、兄弟节点等。
课程链接:
https://www.bilibili.com/video/BV1i54y1h75W?p=1&vd_source=c928153ba3bfd8cd05cb7135600ed75e
附录
b.html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8"/>
<title>Title</title>
</head>
<body>
<ul>
<li><a href="http://www.baidu.com">百度</a></li>
<li><a href="http://www.google.com">谷歌</a></li>
<li><a href="http://www.sogou.com">搜狗</a></li>
</ul>
<ol>
<li><a href="New York">纽约</a></li>
<li><a href="London">伦敦</a></li>
<li><a href="Hong Kong">香港</a></li>
</ol>
<div class="country">英国</div>
<div class="land">美国</div>
</body>
</html>验证码自动化识别(超级鹰官方接口)
#!/usr/bin/env python
# coding:utf-8
import requests
from hashlib import md5
class Chaojiying_Client(object):
def __init__(self, username, password, soft_id):
self.username = username
password = password.encode('utf8')
self.password = md5(password).hexdigest()
self.soft_id = soft_id
self.base_params = {
'user': self.username,
'pass2': self.password,
'softid': self.soft_id,
}
self.headers = {
'Connection': 'Keep-Alive',
'User-Agent': 'Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 5.1; Trident/4.0)',
}
def PostPic(self, im, codetype):
"""
im: 图片字节
codetype: 题目类型 参考 http://www.chaojiying.com/price.html
"""
params = {
'codetype': codetype,
}
params.update(self.base_params)
files = {'userfile': ('ccc.jpg', im)}
r = requests.post('http://upload.chaojiying.net/Upload/Processing.php', data=params, files=files, headers=self.headers)
return r.json()
def PostPic_base64(self, base64_str, codetype):
"""
im: 图片字节
codetype: 题目类型 参考 http://www.chaojiying.com/price.html
"""
params = {
'codetype': codetype,
'file_base64':base64_str
}
params.update(self.base_params)
r = requests.post('http://upload.chaojiying.net/Upload/Processing.php', data=params, headers=self.headers)
return r.json()
def ReportError(self, im_id):
"""
im_id:报错题目的图片ID
"""
params = {
'id': im_id,
}
params.update(self.base_params)
r = requests.post('http://upload.chaojiying.net/Upload/ReportError.php', data=params, headers=self.headers)
return r.json()
if __name__ == '__main__':
chaojiying = Chaojiying_Client('超级鹰用户名', '超级鹰用户名的密码', '96001') #用户中心>>软件ID 生成一个替换 96001
im = open('a.jpg', 'rb').read() #本地图片文件路径 来替换 a.jpg 有时WIN系统须要//
print(chaojiying.PostPic(im, 1902)) #1902 验证码类型 官方网站>>价格体系 3.4+版 print 后要加()
#print chaojiying.PostPic(base64_str, 1902) #此处为传入 base64代码

 浙公网安备 33010602011771号
浙公网安备 33010602011771号