

数据采集与融合技术实践课第四次作业
数据采集与融合技术实践课第四次作业
| 这个作业属于哪个课程 | https://edu.cnblogs.com/campus/fzu/2024DataCollectionandFusiontechnology |
|---|---|
| 码云作业gitee仓库 | https://gitee.com/huang-yuejia/DataMining_project/tree/master/work4 |
| 学号 | 102202142 |
| 姓名 | 黄悦佳 |
目录
一、作业内容
作业①:
- 要求:熟练掌握 Selenium 查找HTML元素、爬取Ajax网页数据、等待HTML元素等内容。
使用Selenium框架+ MySQL数据库存储技术路线爬取“沪深A股”、“上证A股”、“深证A股”3个板块的股票数据信息。
1.采用selenium爬取股票数据(作业1)
本作业源码链接:https://gitee.com/huang-yuejia/DataMining_project/blob/master/work4/4.1/work1.py
- 结果展示:
爬取数据存储到“沪深A股”、“上证A股”、“深证A股”三张表中:
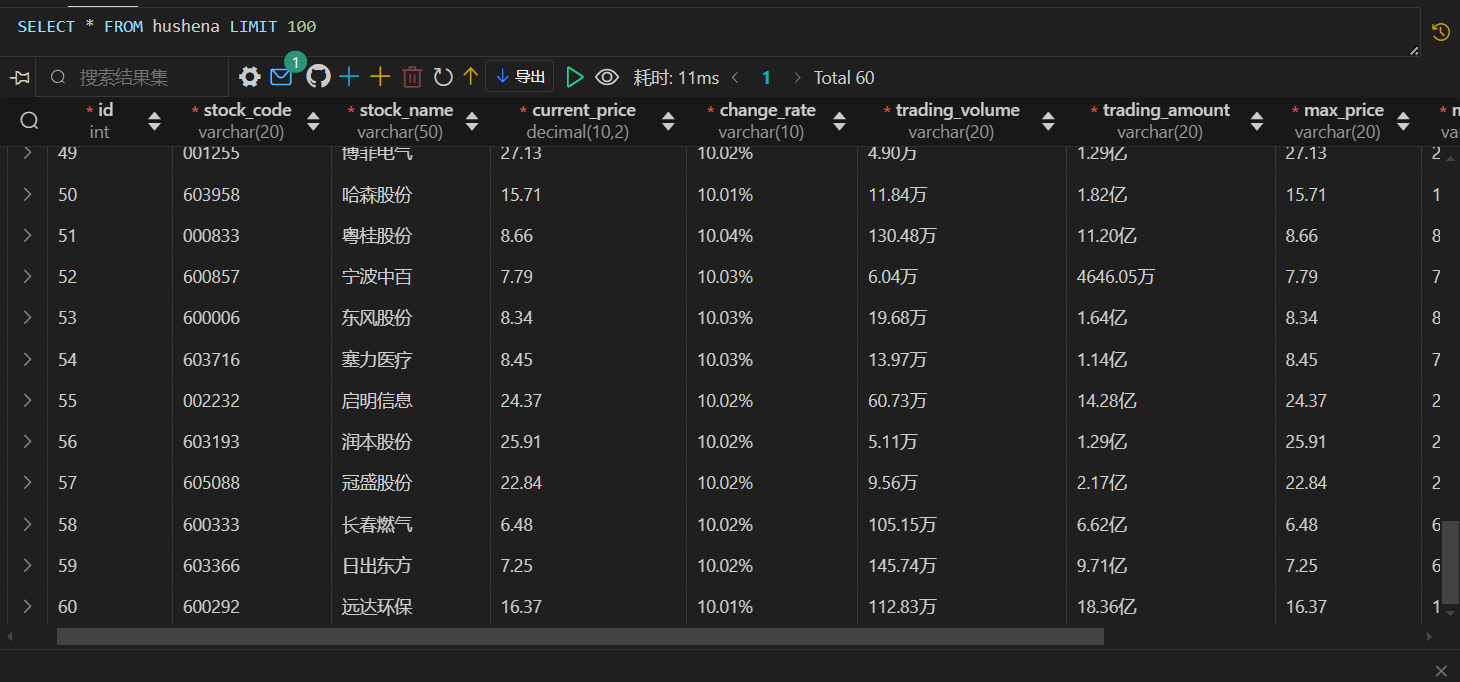


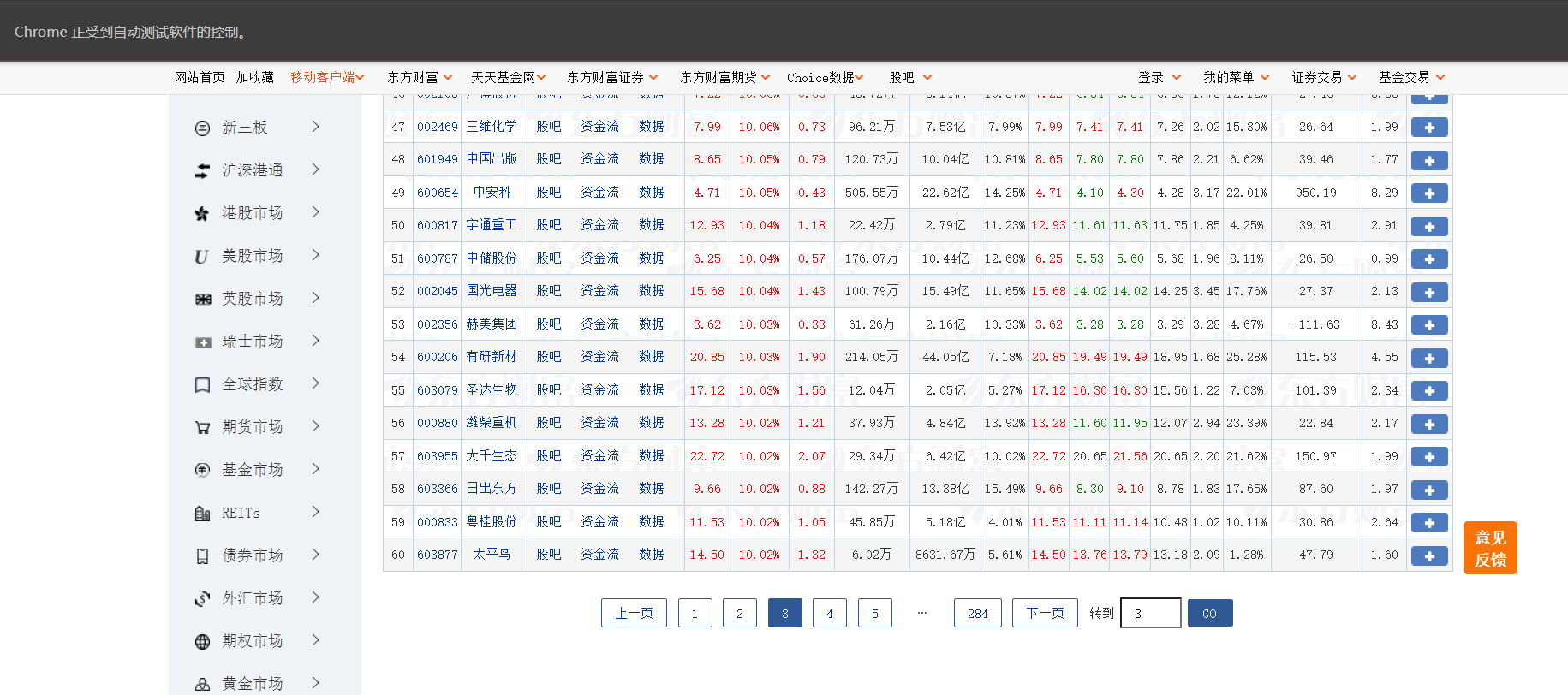
实现翻页爬取,爬取不同模块指定页数的数据
- 关键代码展示:
爬取主函数,实现自动翻页,切换板块
def spider_run(driver, part, table_name):
# 定位板块按钮并点击
button = driver.find_element(By.XPATH, part)
button.click()
pages = 3 # 要爬取的页数
with connection.cursor() as cursor:
for page in range(1, pages + 1):
print(f"正在爬取 {table_name} 第 {page} 页数据...")
slow_scroll(driver)
rows_name = ['//tr[@class="odd"]', '//tr[@class="even"]']
for row_name in rows_name:
rows = driver.find_elements(By.XPATH, row_name)
for row in rows:
columns = row.find_elements(By.TAG_NAME, 'td')
stock_code = columns[1].text
stock_name = columns[2].text
current_price = columns[4].text
change_rate = columns[5].text
trading_volume = columns[7].text
trading_amount = columns[8].text
max_price = columns[10].text
min_price = columns[11].text
today_open = columns[12].text
yes_close = columns[13].text
# 插入数据到对应的表
sql = f"""
INSERT INTO {table_name}
(stock_code, stock_name, current_price, change_rate, trading_volume,
trading_amount, max_price, min_price, today_open, yes_close)
VALUES (%s, %s, %s, %s, %s, %s, %s, %s, %s, %s)
"""
cursor.execute(sql, (stock_code, stock_name, current_price, change_rate,
trading_volume, trading_amount, max_price, min_price,
today_open, yes_close))
connection.commit()
print(f"{table_name} 第 {page} 页数据插入成功!")
next_page(driver)
driver.execute_script("window.scrollTo(0, 0);") # 滑动到顶部
2.心得体会
- 爬取过程中,原本的设想是不进行页面滚动,实际操作中发现不将页面滑动到出现下一页点击按钮,程序无法获取其位置。所以进行click操作时需要确定其在页面范围内,保证程序正常运行。
作业②:
- 要求:
1.爬取mooc网课程资源信息(作业2)
本作业源码链接: https://gitee.com/huang-yuejia/DataMining_project/blob/master/work4/4.2/work2.py
- 结果展示:
实现登录功能

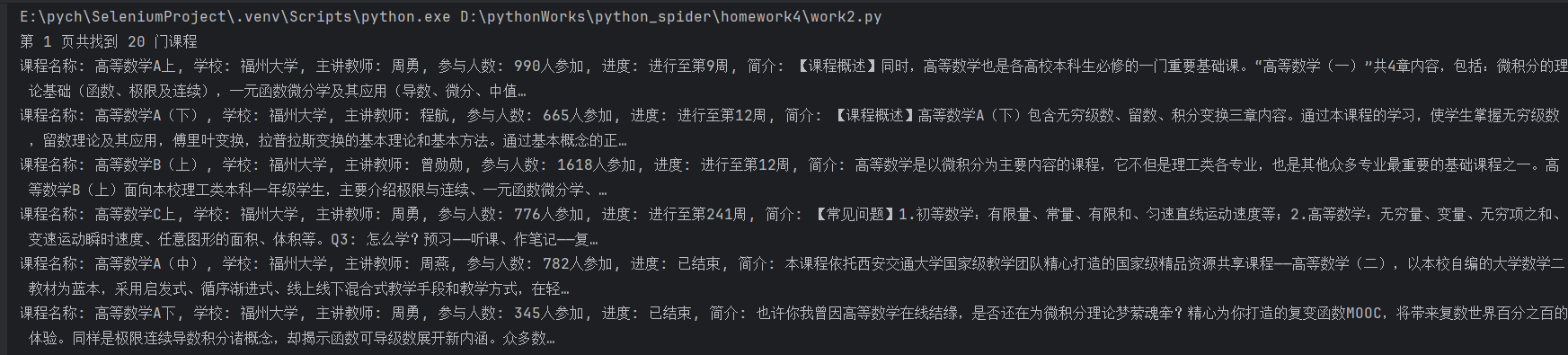
开始爬取数据,实现下滑页面与翻页爬取
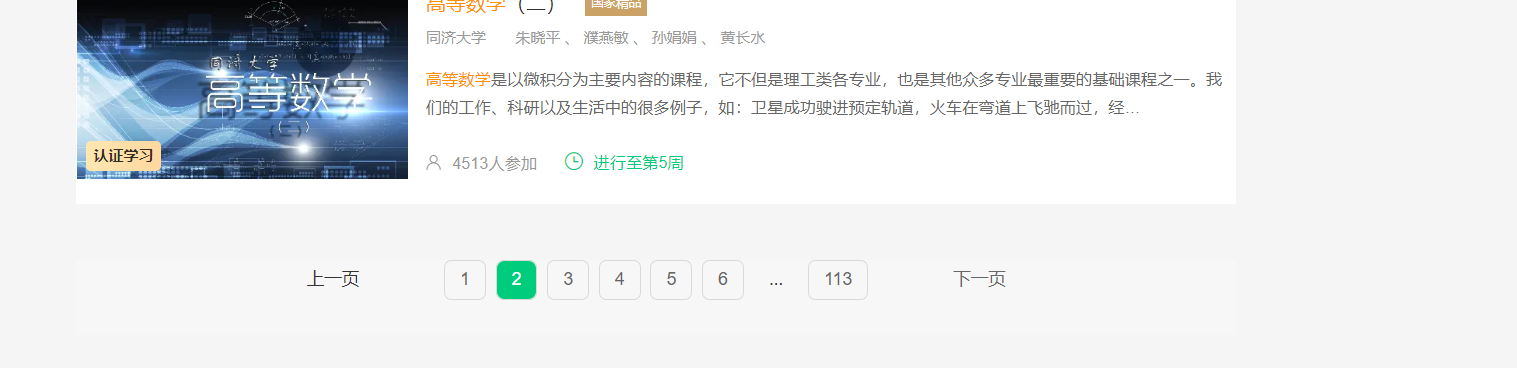
- 关键代码展示:
实现登录功能
def login(driver):
try:
# 点击登录按钮并切换到登录 iframe
login_button1 = driver.find_element(By.XPATH, '//*[@id="j-topnav"]/div')
login_button1.click()
time.sleep(3)
iframe = driver.find_element(By.XPATH,
'/html/body/div[13]/div[2]/div/div/div/div/div/div[1]/div/div[1]/div[2]/div[2]/div[1]/div/iframe')
driver.switch_to.frame(iframe)
# 输入账号和密码
account = driver.find_element(By.XPATH, '//*[@id="phoneipt"]')
password = driver.find_element(By.XPATH, '//*[@id="login-form"]/div/div[4]/div[2]/input[2]')
account.send_keys("13015721658")
password.send_keys("Hyj20041110")
time.sleep(1)
# 点击登录按钮
login_button2 = driver.find_element(By.XPATH, '/html/body/div[2]/div[2]/div[2]/form/div/div[6]/a')
login_button2.click()
# 等待验证登录成功
WebDriverWait(driver, 60).until(EC.url_changes(driver.current_url))
driver.switch_to.default_content() # 切回主内容
time.sleep(2)
# 同意隐私政策
agree = driver.find_element(By.XPATH, '//*[@id="privacy-ok"]')
agree.click()
except Exception as e:
print("登录失败:", e)
实现搜索课程
def search(driver, course):
try:
# 定位搜索框输入课程名称并点击搜索
input_search = WebDriverWait(driver, 10, 0.5).until(
EC.element_to_be_clickable(
(By.XPATH, '//*[@id="j-indexNav-bar"]/div/div/div/div/div[7]/div[1]/div/div[1]/div[1]/span/input'))
)
input_search.send_keys(course)
search_button = driver.find_element(By.XPATH,'//*[@id="j-indexNav-bar"]/div/div/div/div/div[7]/div[1]/div/div/div/span/span/span[2]')
search_button.click()
time.sleep(2)
except TimeoutException:
print("搜索框预期时间内未出现")
实现翻页与获取数据
def fetch(driver, page_num):
for page in range(page_num):
driver.implicitly_wait(5)
courses = driver.find_elements(By.XPATH,
'/html/body/div[4]/div[2]/div[2]/div[2]/div/div[6]/div[2]/div[1]/div/div/div')
print(f"第 {page + 1} 页共找到 {len(courses)} 门课程")
for cor in courses:
# 获取课程详细信息
elements = cor.find_elements(By.XPATH, './div[2]/div/div/div[1]/a[1]/span')
cCourse = elements[0].text if elements else None # 课程名称
elements = cor.find_elements(By.XPATH, './div[2]/div/div/div[2]/a[1]')
cCollege = elements[0].text if elements else None # 学校名称
elements = cor.find_elements(By.XPATH, './div[2]/div/div/div[2]/a[2]')
cTeacher = elements[0].text if elements else None # 主讲教师
elements = cor.find_elements(By.XPATH, './div[2]/div/div/div[3]/span[2]')
cCount = elements[0].text if elements else None # 参加人数
elements = cor.find_elements(By.XPATH, './div[2]/div/div/div[3]/div/span[2]')
cProcess = elements[0].text if elements else None # 课程进度
elements = cor.find_elements(By.XPATH, './div[2]/div/div/a/span')
cBrief = elements[0].text if elements else None # 课程简介
print(
f"课程名称: {cCourse}, 学校: {cCollege}, 主讲教师: {cTeacher}, 参与人数: {cCount}, 进度: {cProcess}, 简介: {cBrief}")
save_to_database(cCourse, cCollege, cTeacher, cCount, cProcess, cBrief)
# 翻页
if page < page_num - 1:
try:
next_page_button = driver.find_element(By.XPATH, '//*[@id="j-courseCardListBox"]/div[2]/ul/li[10]/a')
next_page_button.click()
scroll(driver)
time.sleep(2)
except TimeoutException:
print("下一页按钮未出现")
break
2.心得体会
- 慕课网登录界面无法直接被程序查询到,需要手动找到登录界面的iframe,先切换后进行操作。同时,操作1结束后还要切换回原来的window。
- 慕课搜索课程中,存在广告课程,其中部分课程数据是不完整的,无法获取到信息,需要对此类课程进行额外的判断处理,避免影响程序的正常爬取。
- 直接在课程展示界面爬取的数据是简略过的,信息不完整,需要点击进入具体信息界面进行爬取。
作业③:
- 要求:掌握大数据相关服务,熟悉Xshell的使用
完成文档 华为云_大数据实时分析处理实验手册-Flume日志采集实验(部分)v2.docx 中的任务,即为下面5个任务,具体操作见文档。
本作业源码链接:https://gitee.com/huang-yuejia/DataMining_project/blob/master/work4/
1.华为云平台实时分析开发(作业3)
- 结果展示:
- 环境搭建:开通MapReduce服务
- 实时分析开发实战:
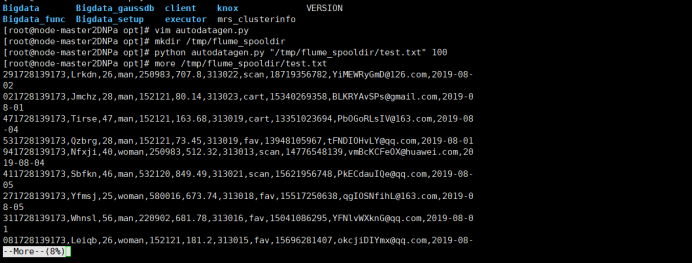
- 任务一:Python脚本生成测试数据
执行Python命令,测试生成100条数据
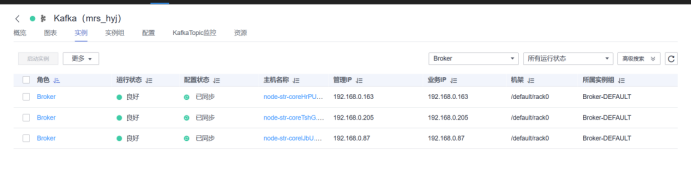
- 任务二:配置Kafka
查看kafkaIP
- 任务一:Python脚本生成测试数据
创建topic

查看topic 信息:

- 任务三:安装Flume客户端
下载客户端

下载成功并检验

解压:

安装客户端:

重启服务:

- 任务四:配置Flume采集数据
修改配置文件

创建消费者消费kafka中的数据,在Kafka有数据产生,表明Flume到Kafka目前是打通的


2.心得体会
- 理解大数据生态:通过这个实验,我更深入地理解了大数据生态系统中的各个组件如何协同工作,特别是MapReduce、Kafka和Flume在数据流处理中的作用。
- 掌握工具的使用:我学会了如何使用Xshell这样的SSH客户端来远程登录服务器,这对于远程管理和调试大数据服务至关重要。
- 实践数据流处理:实验让我体会了从数据生成、传输到存储的整个流程,这对于理解实时数据处理的复杂性非常有帮助。
二、作业总结
学习到的技术
- Selenium框架应用:通过Selenium框架,实现了对沪深A股、上证A股、深证A股股票数据的爬取,以及mooc网课程资源信息的爬取,加深了对网页自动化操作和selenium框架的理解。
- 大数据服务:通过华为云平台的实时分析开发,初步了解了MapReduce服务的开通、Kafka的配置、Flume客户端的安装和配置的流程,对未来处理大规模数据起到奠基作用。
遇到的问题及解决方法
- 处理 iframe: Selenium 在操作 iframe 时必须先切换到相应的框架,否则无法访问框架内的元素,遇到 iframe 问题时,要特别注意页面的切换和元素的定位,同时在结束某一页面的操作后,应当及时返回原来的界面,防止操作流程中断。
心得体会
- 通过这次实践课的作业,我不仅提升了自己的技术技能,也增强了解决实际问题的能力。这些经验对于我未来在数据科学和大数据处理领域的进一步学习和工作将起到重要的推动作用。
