
数据采集与融合技术实践课作业2
数据采集与融合技术实践课第二次作业
| 这个作业属于哪个课程 | https://edu.cnblogs.com/campus/fzu/2024DataCollectionandFusiontechnology |
|---|---|
| 码云作业gitee仓库 | https://gitee.com/huang-yuejia/DataMining_project/tree/master/work2 |
| 学号 | 102202142 |
| 姓名 | 黄悦佳 |
目录
一、作业内容
作业①:
- 要求:在中国气象网(http://www.weather.com.cn)给定城市集的7日天气预报,并保存在数据库。
1.爬取城市天气信息(代码在课程作业基础上改进优化)
本作业源码链接:https://gitee.com/huang-yuejia/DataMining_project/blob/master/work2/2.1
- 结果展示:
爬取过程

存储到数据库

- 关键代码展示:
输出爬取处理
获取数据
def fetch_weather_data(self, city):
url = f"http://www.weather.com.cn/weather/{self.cityCode[city]}.shtml"
try:
req = urllib.request.Request(url, headers=self.headers)
with urllib.request.urlopen(req) as response:
data = response.read()
dammit = UnicodeDammit(data, ["utf-8", "gbk"])
return dammit.unicode_markup
except Exception as e:
print(f"Error fetching weather data for {city}: {e}")
return None
处理数据
soup = BeautifulSoup(html_data, "lxml")
lis = soup.select("ul[class='t clearfix'] li")
for li in lis:
try:
date = li.select('h1')[0].text.strip()
weather = li.select('p[class="wea"]')[0].text.strip()
msg = li.select('')[0].text.strip()
temp = li.select('p[class="tem"] span')[0].text.strip() + "/" + li.select('p[class="tem"] i')[
0].text.strip()
print(f"{city}, {date}, {weather},{msg}, {temp}")
self.db.insert(city, date, weather,msg, temp)
except Exception as e:
print(f"Error processing data for {city}: {e}")
2.心得体会
- 通过查找不同的城市代码筛选指点的城市信息,同时加入数据库的使用,使处理得到的数据能够更直观的展示,并便于下一步的处理分析。
作业②:
- 要求:要求:用 requests 和 BeautifulSoup 库方法定向爬取股票相关信息,并存储在数据库中。
1.爬取股票信息(采用抓包方式)(作业2)
本作业源码链接:https://gitee.com/huang-yuejia/DataMining_project/blob/master/work2/2.2
-
结果展示:
爬取过程

存储到数据库

-
关键代码展示:
提取json格式数据
# 提取 JSON 数据
json_str_start = response.text.index('(') + 1 # 找到 '(' 的位置
json_str_end = response.text.rindex(')') # 找到 ')' 的位置
json_str = response.text[json_str_start:json_str_end] # 提取 JSON 字符串
# 解析 JSON 数据
data = json.loads(json_str)
# 检查数据是否成功读取
if 'data' in data and 'diff' in data['data']:
return data['data']['diff']
else:
print("数据格式不正确或未找到 'diff' 字段。")
return []
通过f1,f2等参数获取信息
if stock_data:
# 提取所需字段并准备数据插入
stocks = []
for stock in stock_data:
stock_code = stock.get('f12') # 股票代码
stock_name = stock.get('f14') # 股票名称
stock_price = stock.get('f2') # 当前价格
stock_change = stock.get('f4') # 涨跌
stock_trading_volume = stock.get('f5') #交易量
stock_transaction = stock.get('f6') #总交易金额
stock_change_percent = stock.get('f10') # 涨跌幅度
2.心得体会
- 加深了对API数据抓取、JSON 解析、SQLite 数据库操作以及 Python 编程中模块化设计的理解。
作业③:
- 要求:爬取中国大学 2021 主榜(https://www.shanghairanking.cn/rankings/bcur/2021)所有院校信息,并存储在数据库中,同时将浏览器 F12 调试分析的过程录制 Gif 加入至博客中
本作业源码链接:https://gitee.com/huang-yuejia/DataMining_project/blob/master/work2/2.3
1.爬取大学排名-抓包方式(作业3)
- 结果展示:
浏览器 F12 调试分析的过程录制

爬取过程
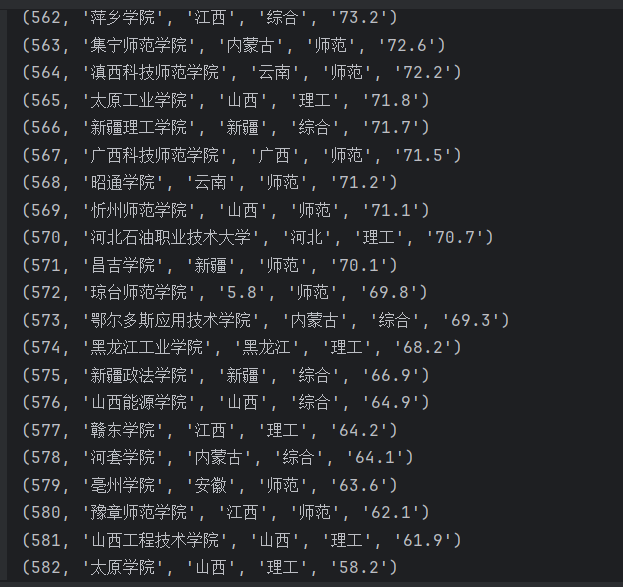
存储到数据库

遇到的问题
对应关系图
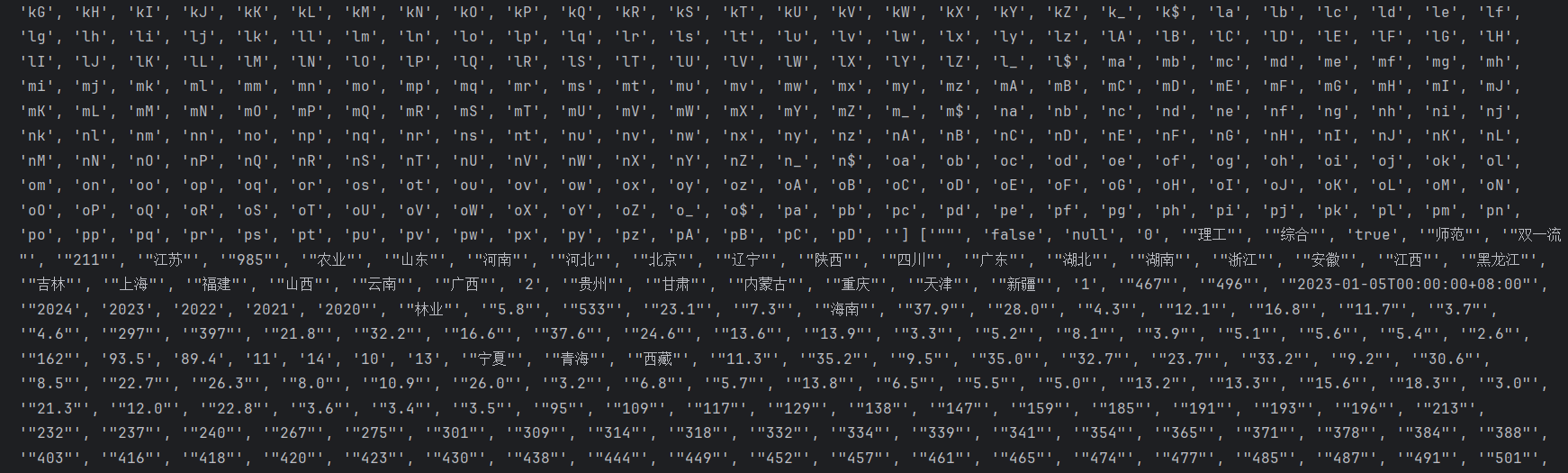
部分数据存在异常情况,部分分数由字母表示转换过程中发生异常

- 关键代码展示:
将地址数据由英文字符表示转换为中文(查阅资料修改)
university_data = fetch_university_data()
#获取需要的数据
name = re.findall(',univNameCn:"(.*?)",', university_data)
score = re.findall(',score:(.*?),', university_data)
category = re.findall(',univCategory:(.*?),', university_data)
province = re.findall(',province:(.*?),', university_data)
#对数据进行处理变换
c_name = re.findall('function(.*?){', university_data)
start = c_name[0].find('a')
end = c_name[0].find('pE')
c_name = c_name[0][start:end].split(',')
v_name = re.findall('mutations:(.*?);', university_data)
start = v_name[0].find('(')
end = v_name[0].find(')')
v_name = v_name[0][start + 1:end].split(",")
universities = []
for i in range(len(name)):
province_name = v_name[c_name.index(province[i])][1:-1]
category_name = v_name[c_name.index(category[i])][1:-1]
pattern = '[a-zA-Z]' # 匹配大小写字母
result = re.findall(pattern, score[i])
if result:
score[i]=v_name[c_name.index(score[i])][:-1]
else:
score[i]=score[i]
print((i + 1, name[i], province_name, category_name, score[i]))
universities.append((i + 1, name[i], province_name, category_name, score[i]))
2.心得体会
- 部分信息不是直接将数据存储在其中,而是先通过其他更简介的方式标记,需要时再通过函数转化得到。例如本次作业中的学校地址,类型信息。通过这种方式,可以减少数据的传输量,存储量,提高效率。
二、作业总结
难点与挑战:
- 复杂的网页结构与数据抓取
网页中的数据经常被深藏在嵌套的标签或脚本中,尤其是学校排名和股票信息,需要分析网页的 DOM 结构,或者通过抓包分析找到数据源。提取信息时,需要精确选择合适的标签或使用正则表达式来解析非结构化的数据。 - API 数据解析
对于股票信息,数据通过 API 返回的 JSON 格式,需要准确地理解 JSON 数据的层次结构,并提取出关键信息进行处理和存储。
解决思路:
- 抓包分析
使用浏览器的开发者工具进行抓包分析,找出 API 请求和返回的格式,从中提取出数据的结构,设计相应的解析逻辑。 - 数据处理与清洗
在解析完 JSON 数据后,结合实际需要提取特定的字段,使用字典或映射表将代码转换为相应的文本信息,确保数据在存储之前已经处理完毕,满足后续使用的需求。
新知识与收获:
-
深入掌握 HTML 和 CSS 的解析
通过多次实践,增强了对 HTML 文档结构的理解,能更灵活地使用 BeautifulSoup 进行数据提取。学习了如何使用 CSS 选择器和 XPath 来选择特定节点,极大提高了提取效率。 -
API 调用与 JSON 数据处理
对 API 数据的调用与 JSON 格式的解析有了更深刻的理解,掌握了如何从 JSON 数据中提取出嵌套字段,并将其转化为所需的格式。 -
数据库的设计与操作
在使用 SQLite 进行数据存储的过程中,理解了如何设计数据库表结构,如何高效地进行数据插入、更新和查询,进一步提高了数据的管理和使用效率。


【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】凌霞软件回馈社区,博客园 & 1Panel & Halo 联合会员上线
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】博客园社区专享云产品让利特惠,阿里云新客6.5折上折
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 一个费力不讨好的项目,让我损失了近一半的绩效!
· 清华大学推出第四讲使用 DeepSeek + DeepResearch 让科研像聊天一样简单!
· 实操Deepseek接入个人知识库
· CSnakes vs Python.NET:高效嵌入与灵活互通的跨语言方案对比
· Plotly.NET 一个为 .NET 打造的强大开源交互式图表库