

数据采集与融合技术实践课作业1
数据采集与融合技术实践课第一次作业
| 这个作业属于哪个课程 | https://edu.cnblogs.com/campus/fzu/2024DataCollectionandFusiontechnology |
|---|---|
| 码云作业gitee仓库 | https://gitee.com/huang-yuejia/DataMining_project/tree/master/work1 |
| 学号 | 102202142 |
| 姓名 | 黄悦佳 |
目录
一、作业内容
作业①:
- 要求:用requests和BeautifulSoup库方法定向爬取给定网址(http://www.shanghairanking.cn/rankings/bcur/2020 )的数据,屏幕打印爬取的大学排名信息。
1.爬取大学排名(作业1)
本作业源码链接:https://gitee.com/huang-yuejia/DataMining_project/blob/master/work1/work1.py
-
结果展示:
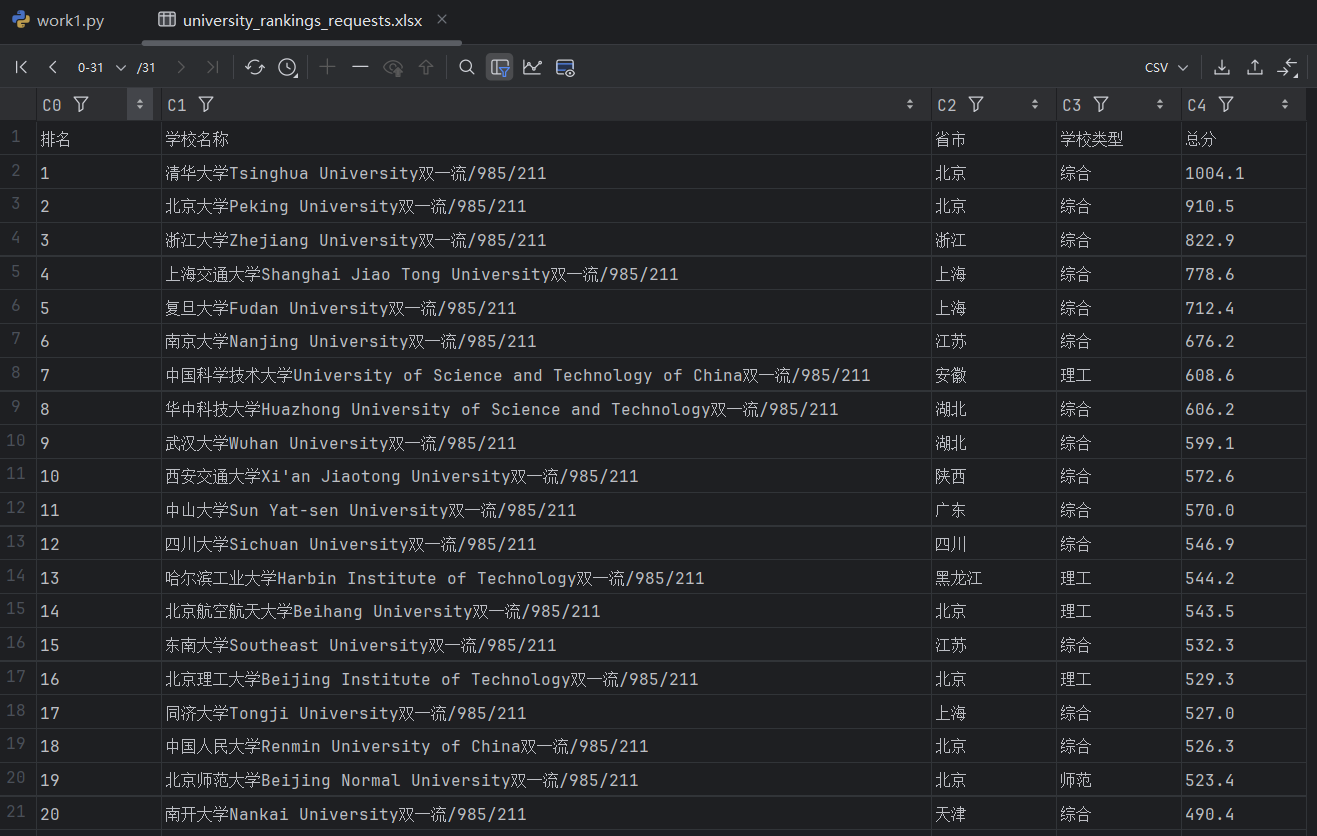
-
关键代码展示:
输出爬取处理
# 检查请求是否成功
if response.status_code == 200:
web_content = response.content.decode('utf-8')
# 使用BeautifulSoup解析网页
soup = BeautifulSoup(web_content, 'html.parser')
# 查找包含大学排名信息的表格
table = soup.find('table')
# 准备保存到Excel的数据列表
data = []
if table:
print("爬取到的大学排名信息:")
for row in table.find_all('tr')[1:]: # 跳过表头
cols = row.find_all('td')
if len(cols) >= 5:
rank = cols[0].get_text(strip=True)
name = cols[1].get_text(strip=True)
location = cols[2].get_text(strip=True)
type_ = cols[3].get_text(strip=True)
score = cols[4].get_text(strip=True)
# 将每行数据追加到列表
data.append([rank, name, location, type_, score])
2.心得体会
- 通过BeautifulSoup库解析HTML内容,结合开发者工具找到具体的数据位置。利用find()和find_all()方法,逐步缩小搜索范围,提取出表格中的排名、学校名称等关键信息实现简单的数据爬取和分析处理,提取所需要的信息。
作业②:
- 要求:用requests和re库方法设计某个商城(自已选择)商品比价定向爬虫,爬取该商城,以关键词“书包”搜索页面的数据,爬取商品名称和价格。
1.爬取当当网书包名称及价格信息(作业2)
本作业源码链接:https://gitee.com/huang-yuejia/DataMining_project/blob/master/work1/work2.py
-
结果展示:
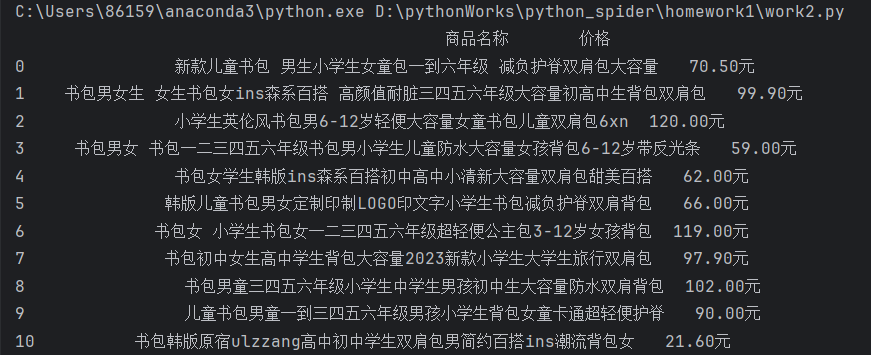

-
关键代码展示:
正则表达式处理数据
web_content = response.text
# 使用正则表达式提取商品名称和价格
# 商品名称的正则匹配
name_pattern = re.compile(r'<a.*?class="name".*?title="(.*?)".*?>')
# 商品价格的正则匹配
price_pattern = re.compile(r'<p.*?class="price".*?>(.*?)</p>')
# 获取商品名称和价格
names = name_pattern.findall(web_content)
prices = price_pattern.findall(web_content)
# 清理价格数据
cleaned_prices = [price.replace('<span class="price_n">¥', '').replace('</span>', '元').strip() for price in prices]
2.心得体会
- 通过本次练习,强化了对正则表达式的理解与使用,进一步了解了如何处理爬取到的网页内容,尤其是在应对HTML标签嵌套及数据清理时的策略。同时也学习了如何通过清理网页中的多余标签来获取干净的数据。
作业③:
- 要求:爬取一个给定网页( https://xcb.fzu.edu.cn/info/1071/4481.htm)或者自选网页的所有JPEG和JPG格式文件
本作业源码链接:https://gitee.com/huang-yuejia/DataMining_project/blob/master/work1/work3.py
1.爬取下载福大新闻官网.jpg/.jpeg图片(作业3)
-
结果展示:
-
关键代码展示:
获取图片下载地址
# 获取图片链接,过滤jpg和jpeg格式
for img in img_tags:
img_url = img.get('src')
if img_url:
# 处理相对路径和绝对路径
if img_url.startswith('//'):
img_url = 'https:' + img_url # 补全协议
elif img_url.startswith('/'):
img_url = 'https://news.fzu.edu.cn' + img_url # 补全域名
# 仅保留 jpg 和 jpeg 格式的图片
if img_url.lower().endswith(('.jpg', '.jpeg')):
img_urls.append(img_url)
下载图片
# 下载图片
def download_image(url, image_num):
try:
print(f"Downloading image {image_num} from {url}...")
response = requests.get(url, stream=True)
response.raise_for_status() # 确保请求成功
file_path = os.path.join(save_folder, f'image_{image_num}.jpg')
with open(file_path, 'wb') as f:
for chunk in response.iter_content(1024):
f.write(chunk)
print(f"Successfully downloaded image {image_num}: {file_path}")
except Exception as e:
print(f"Error downloading image {image_num} from {url}: {e}")
2.心得体会
- 图片下载涉及网络请求,如果串行执行会导致效率低下,使用多线程方式对图片等数据进行下载则可以有效的解决这个问题。
- 网络请求容易受到外界因素影响,比如连接超时、断网等。因此需要在下载过程中实现的异常处理,避免程序崩溃或卡住。
二、作业总结
难点与挑战:
- 网页结构复杂性:在三次作业中,解析不同网页的HTML结构是一个共同的挑战。无论是从大学排名页面提取表格信息、从当当网提取商品数据,还是从福州大学新闻页面获取图片,网页的结构都不尽相同,尤其是动态内容、嵌套标签和相对路径增加了处理的难度。
- 数据提取准确性:无论是通过正则表达式还是使用BeautifulSoup解析网页,如何精确提取目标数据(如排名、价格、图片链接等)是核心问题。正则表达式处理复杂HTML结构时,编写和调试匹配规则较为繁琐,需要多次尝试和优化。
- 并发处理与效率优化:在福州大学新闻图片下载作业中,如何提高下载效率是关键。单线程下载效率低下,需要通过多线程来加速。合理管理并发下载、处理网络请求中的异常也是重要的挑战。
解决思路:
- 灵活应用网页解析工具:根据不同网页的复杂性,选择合适的解析方式。例如,对于结构清晰的网页,BeautifulSoup能很好地解析并提取数据。而对于页面元素较复杂的场景,正则表达式提供了更灵活的方式来精确匹配需要的数据。
- 数据清理和格式转换:在数据提取过程中,往往会遇到无效数据或多余的HTML标签。通过适当的清理与转换,例如价格数据的清理、图片链接的补全、表格内容的提取,确保数据的完整性和准确性。
- 并发与异常处理的结合:为了提升效率,使用ThreadPoolExecutor进行多线程并发处理,并结合try-except处理网络请求的失败情况。这样既提高了效率,又确保即使某个任务失败,也不会影响整体的执行。
新知识与收获:
- 正则表达式的应用:在数据爬取中,学习了如何通过正则表达式从网页中提取有价值的信息,尤其是在处理复杂网页时,正则表达式比传统解析方法更灵活。
- 多线程与并发处理:通过福州大学新闻图片下载的作业,进一步理解了Python多线程的应用场景和并发处理的优势。掌握了如何使用ThreadPoolExecutor进行多任务并行处理,并通过as_completed()管理任务结果。
- 数据存储与持久化:在三次作业中,利用pandas和openpyxl将数据结构化保存到Excel文件中,熟悉了从数据提取到数据持久化的完整流程。通过pandas库轻松处理大规模数据,学会了如何清理、转换和保存数据。>
