
第二阶段_day16-17_SQL01&&02简单查询
- 数据库基础
- MySQL安装和使用
- SQL概述
- SQL查询语言
1.数据库基础
定义:
Database:A database is an organized collection of data, stored and accessed electronically. [wikipedia]
数据库:数据库是按照数据结构来组织、存储和管理数据的仓库。【百度百科】
分类:
- 关系型数据库
不仅存储数据本身,还存储数据之间的关系,比如说用户信息和订单信息。 关系型数据库模型把复杂的数据结构归结为简单的二维表(关系表) 。
- 非关系型数据库
非关系型数据库也被称为NoSQL数据库。NoSQL的产生并不是要否定 关系型数据库,而是作为关系型数据库的一个有效补充。
DB-Engines排行榜(2019/5)
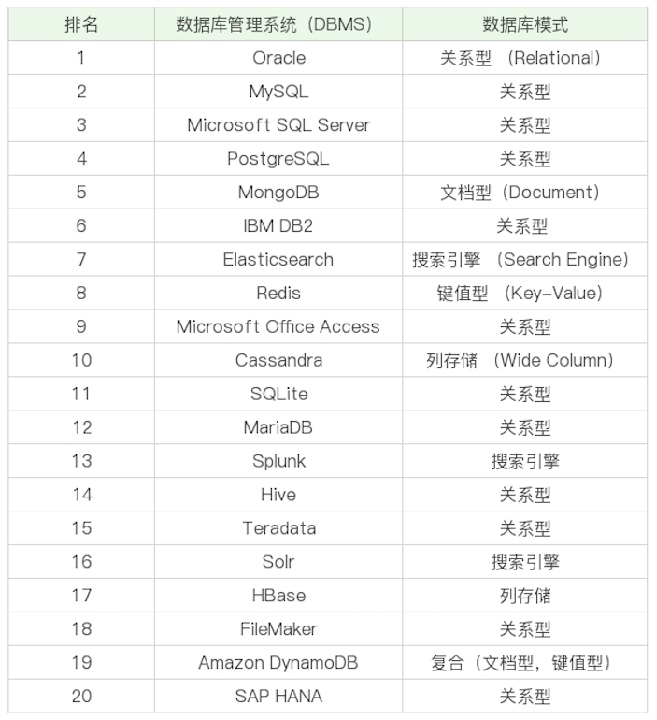
易混淆术语:
数据库系统(DBS):是指在计算机系统中引入数据库后的系统,一般由数据库、数据库管理系统、应用系统、数据库管理员(DBA)构成。
数据库管理系统(DBMS):是一种操纵和管理数据库的大型软件, 用于建立、使用和维护数据库(如:MySQL)。
数据库(DB):数据库是按照数据结构来组织、存储和管理数据的仓库。
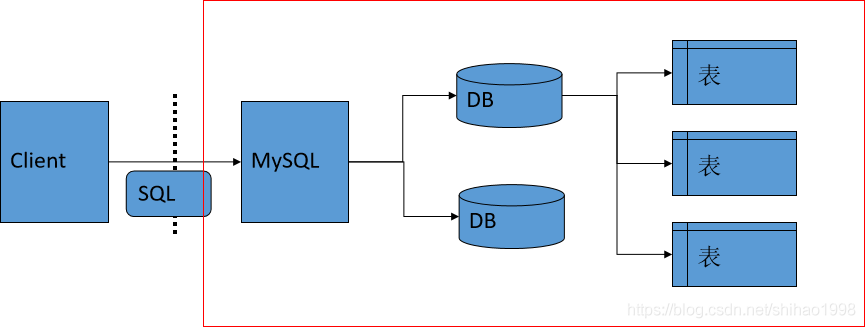
数据库管理系统、数据库服务、数据库和表的关系
典型的C/S架构
红色框中是服务器端
客户端通过SQL语言向服务器端发送需求。
MySQL接受客户端的请求。
MySQL会管理很多个数据库,每个数据库中又有多张
数据在表中的形式
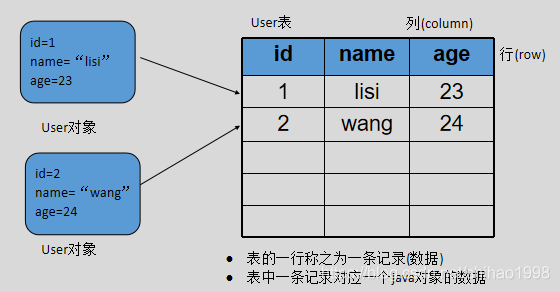
对象与行对应,属性与列对应
对象关系映射(Object Relational Mapping,简称ORM):Hibernate & MyBatis
2.MySQL安装与配置
见文档
登录 MySQL Server
在启动 MySQL 服务后,输入以下格式的命令:
mysql -h 主机名 -u 用户名 –p
- -h:该参数用于指定客户端的主机名(host),即哪台机器要登录 MySQL Server,如果是当前机器该参数可以省略;
- -u:用户名(user)。
- -p:密码(password),如果密码为空,该参数可以省略。
3.SQL简介
SQL是结构化查询语言(Structured Query Language)的缩写。 它是一种专门用来与关系型数据库沟通的语言。
它主要有如下的优点:
- SQL 是一种通用语言,几乎所有的关系型数据库都支持 SQL。
- SQL 简单易学。它的语句是由一些有很强描述性的关键词组织而成, 而且这些关键词并不多。
- SQL 虽然简单,但它是一种强有力的语言,灵活地使用 SQL, 可以进行非常复杂的数据库操作。
- 半衰期很长 SQL92, SQL99
SQL 不区分大小写(关键字不区分大小写)!!!
建议:关键字大写, 表名,列名,值最好是以它定义时值
组成:
DDL: 数据定义语言
DML:数据操作语言 (增,删,改)
DQL: 数据查询语言 (查)
DCL: 数据控制语言
TPL: 事务处理语言 …
3.1数据定义语言(DDL)
DDL:Data Definition Language
作用:创建 & 管理数据库和表的结构。
常用关键字: CREATE ALTER DROP
创建数据库

练习:
- 创建一个名称为mydb1的数据库。
- 创建一个使用gbk字符集的mydb2数据库。
- 创建一个使用gbk字符集,并带校对规则(校对集)的mydb3数据库。
查看、删除数据库

练习:
- 查看当前数据库服务器中的所有数据库
- 查看前面创建的mydb2数据库的定义信息
- 删除前面创建的mydb3数据库
修改数据库

练习
- 查看服务器中的数据库,并把mydb2的字符集修改为utf8;
-----------------------------------------------------------------------------------------------------------
关于表的一些操作
创建表

如果创建表的时候没有指定的字符集和校对规则,那么默认这张表的字符集和校对规则就是数据库的字符集和校对规则。
如果创建表的时候指定了的字符集和校对规则,那么这张表的数据就会使用你创建表时的字符集和校对规则。

创建表练习
创建一个员工表
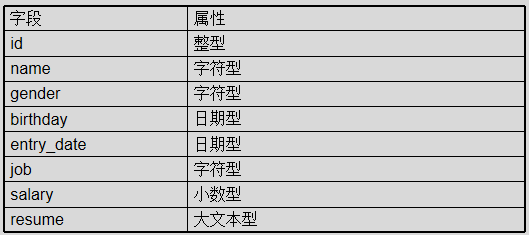
查询表
- 简单描述表结构
DESC 表名 或者 DESCRIBE 表名
- 查看生成表的 DDL 语句
SHOW CREATE TABLE 表名
修改表

RENAME TABLE 语句的另一个用法是移动该表到另一个数据库
语法为:
RENAME TABLE 旧数据库名.旧表名 TO 新数据库名.新表名
提示:我们可以把 RENAME TABLE 的这两种用法很好地统一起来,如果我们把 “重命名” 理解为 “在同一数据库里的移动”。甚至我们可以省略数据库名,如果你恰好正在使用该数据库。
修改表练习
- 在上面员工表的基础上增加一个image列。
- 修改job列,使其长度为60。
- 删除image列。
- 表名改为user。
- 修改表的字符集为gbk
- 列名name修改为username→alter table user change name username varchar(20);
删除表
DROP TALBE 表名
1 ############################ 字符集和校对规则 ############################ 2 # 查看所有字符集 3 show char set; 4 # 查看所有的校对集 5 show collation; 6 # 查看数据库的默认字符集 7 show variables like '%char%'; 8 select @@character_set_database; 9 10 ############################### 数据库 ################################## 11 12 # a. 查询数据库 13 show databases; # 查看所有数据库 14 show create database mydb1; # 查询数据库的创建语句 15 show create database mydb2; 16 show create database mydb3; 17 18 # b. 创建数据库 19 # create database [if not exists] db_name [specification]; 20 21 # 练习1:创建一个名称为mydb1的数据库。 22 create database mydb1; 23 24 # 练习2:创建一个使用gbk字符集的mydb2数据库 25 # create database mydb1 character set gbk; 26 # create database if not exists mydb1 character set gbk; 27 create database if not exists mydb2 character set gbk; 28 29 # 练习3:创建一个使用gbk字符集,并带校对规则(gbk_bin)的mydb3数据库。 30 create database mydb3 character set gbk collate gbk_bin; 31 32 # c. 删除数据库 33 # 语法:drop database [if exists] db_name 34 # 练习:删除前面创建的mydb3数据库 35 # drop database mydb3; 36 drop database if exists mydb3; 37 38 # d. 修改数据库 39 # 语法:alter database db_name [specificaton] 40 # 练习:把mydb2的字符集修改为utf8 41 alter database mydb2 character set utf8; 42 43 ################################## 表 #################################### 44 # a. 查看表 45 show tables; # 查看数据库中所有的表 46 show create table t_user; # 查看表的定义语句 47 # describe/desc t_user; # 查看表的结构 48 desc t_user; 49 50 # b. 创建表 51 # 语法: 52 -- create table tb_name ( 53 -- field1 datatype, 54 -- field2 datatype, 55 -- field3 datatype 56 -- )[specifications] 57 58 use mydb1; 59 # 练习:创建user(id, name, password, birthday) 60 create table t_user ( 61 id int, 62 name varchar(255), 63 password varchar(20), 64 birthday date 65 ); 66 67 # c. 修改表 68 # 增加列 69 # 语法:alter table tb_name add column column_name datatype [, add column_name datatype, ...] 70 # 练习1:添加gender列 71 alter table t_user add column gender varchar(10); 72 # 练习2:在password后面添加balance列 73 alter table t_user add column balance int after password; 74 # 练习3:在最前面添加no列 75 alter table t_user add column no int first; 76 # 练习4:添加a, b列 77 alter table t_user add column a int, add column b int; 78 79 # 修改列 80 # 修改列的名字 81 # 语法:alter table tb_name change column col_name new_col_name datatype [specification]; 82 # 练习:把balance的名字改成salary 83 alter table t_user change column balance salary int; 84 85 # 修改列的定义 86 # 语法:alter table tb_name modify column col_name datatype [specification]; 87 # 练习:把salary的类型改成decimal(10,2) 88 alter table t_user modify column salary decimal(10,2); 89 90 # 删除列 91 # 语法:alter table tb_name drop column col_name; 92 # 练习:删除a列 93 alter table t_user drop column a; 94 95 # 练习:删除b列, 把gender的类型改成bit(1), 在name的后面添加c列 96 alter table t_user drop column b, modify column gender bit(1), add column c int after name; 97 desc t_user; 98 99 # 修改表的名字, 迁移表 100 # 语法: rename table tb_name to new_tb_name; 101 rename table t_user to user; 102 # show tables; 103 # show databases; 104 # 练习:把mydb1中的user迁移到mydb2,并且重命名为t_user; 105 rename table user to mydb2.t_user; 106 show tables; 107 show tables in mydb2; 108 109 # 修改表的字符集 110 # 语法:alter table character set charset_name 111 rename table mydb2.t_user to t_user; 112 show create table t_user; 113 # 练习:把t_user的字符集改成gbk 114 alter table t_user char set gbk; 115 116 # d.删除表 117 # 语法:drop table tb_name; 118 drop table t_user; 119 show tables; 120 drop table t_user; 121 drop table if exists t_user;
1 数据库基础 2 定义 3 分类 4 a.关系型数据库 5 Oracle 6 MySQL 7 Microsoft SQL Server 8 MariaDb 9 ... 10 b.非关系型数据库 11 文档型 12 键值值 13 搜索引擎 14 列存储 15 图数据库 16 易混淆的概念 17 数据库系统 18 数据库管理系统(DBMS) 19 数据库 20 RDBMS架构(C/S) 21 ORM思想 22 23 MySQL的安装和配置 24 25 SQL 26 介绍 27 组成: 28 DDL 29 DML 30 DQL 31 DCL 32 TPL 33 ... 34 35 DML 36 数据库 37 查: 38 show databases; 39 show create database db_name; 40 增: 41 create database [if not exists] db_name [character set, collate]; 42 改: 43 alter database db_name [character set, collate] 44 删: 45 drop database db_name; 46 表: 47 查: 48 show tables; 49 show create table tb_name; 50 describe/desc tb_name; 51 增: 52 create table tb_name( 53 col_name type, 54 col_name type, 55 col_name type 56 )[engine, character set, collate]; 57 改: 58 a. 添加列 59 alter table tb_name add column new_col_name type; 60 alter table tb_name add column new_col_name type after col_name; 61 alter table tb_name add column new_col_name type first; 62 b. 修改列 63 alter table tb_name change column col_name new_col_name type; 64 alter table tb_name modify column col_name type; 65 c. 删除列 66 alter table tb_name drop column col_name; 67 d. 重命名/迁移 68 rename table tb_name to new_tb_name; 69 e. 修改存储引擎,字符集,校对集 70 alter table tb_name [engine, character set, collate]; 71 删: 72 drop table tb_name;
day17
数据类型
注意:这里以MySQL为例,不同的DBMS的都支持数值类型,字符串类型以及日期类型,但他们的实现可能不一样。
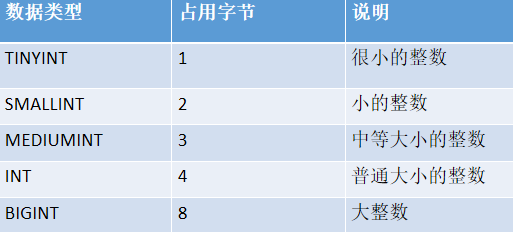
- 整数类型
- 浮点数类型和定点数类型
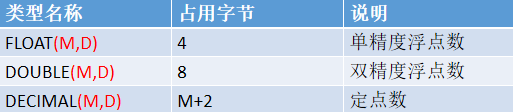
其中 M 称为精度,表示总共的位数;
D 称为标度,表示小数的位数。
DECIMAL 类型不同于 FLOAT & DOUBLE,DECIMAL 实际是以字符串存放的,它的存储空间并不固定,而是由精度 M 决定的。
为什么要引入定点数DECIMAL呢?
DECIMAL 类似于 java中的BigDecimal类,浮点数是不精确的,DECIMAL类型是精确的,它是以字符串进行加减的。
存储金额的时候不要用浮点数类型。
- 日期与时间类型
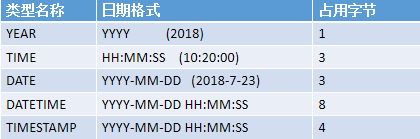
DATETIME 和 TIMESTAMP 虽然显示的格式是一样的,但是它们有很大的区别:
- DATETIME 的系统默认值是 NULL, 而 TIMESTAMP 的系统默认值是当前时间 NOW();
- DATETIME 存储的时间与时区无关,而 TIMESTAMP 与时区有关。
为什么TIMESTAMP可以用4个字节表示,而DATETIME得用8个字节呢?
DATETIME表示的是自基准时间以来的毫秒数,而TIMESTAMP表示的是自基准时间以来的秒数。
基准时间:1970年1月1日0点0分0秒 (格林威治时间)
1 # 1) datetime的默认值是null, timestamp的默认值是now() 2 create database day17; 3 use day17; 4 create table t_time( 5 a datetime, 6 b timestamp 7 ); 8 insert into t_time(a) values(now()); 9 insert into t_time(b) values(now()); 10 desc t_time; 11 select * from t_time;
执行结果如下:
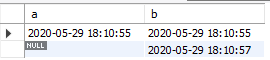
insert into t_time(a) values(now()); 执行完后,a列插入当前时间的数据,b列默认值为now(),所以也为当前时间。
insert into t_time(b) values(now());执行完后,b列插入当前时间的数据,a列默认值为null。
- 字符串类型
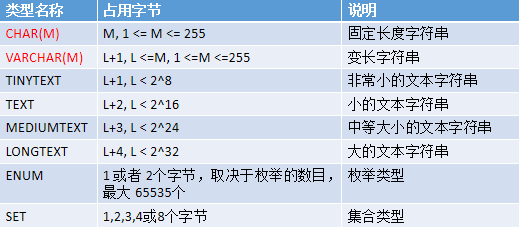
当用char(10)表示一个数据所占的字节个数时,即使这个数据是‘a’,它也占10个字节。
当用varchar(10)表示一个数据所占的字节个数时,表示这个数据最大占10字节,如‘abc’这个数据总共占4字节,1个字节表示数据的长度,3个字节表示数据。(上述图表中L表示数据,+1表示用1个字节记录数据 长度,告诉计算机往后读取几个字节能读完这个数据)
char和varchar类型一般用于存储字符串
TINYTEXT用于存储文本类型的数据。
TINYTEXT其实就等于varchar(255)
ENUM存的数据如:‘男’、‘女’。里面的类型都是一种类型,如:字符串类型
SET类型存的数据如:‘打篮球’、‘唱歌’、‘吃’。里面的类型可以是不同类型。
ENUM 类型总有一个默认值,当ENUM 列声明为NULL,则默认值为NULL。如果 ENUM 列被声明为 NOT NULL,则其默认值为列表的第一个元素。
- 二进制类型

字符串类型存储的字符串(字符), 二进制类型存储的是二进制数据(字节)。
对比这张表和上面字符串类型的那张表
BINARY 和char类型类似
VARBINARY和varchar类型类似
下面的blob类型和text类型相似
blob类型对应java中的blob类型,text类型对应java中的cblob类型,c表示character,字符
1 ############################### 数据类型 ################################ 2 # 注意事项:字符串类型和日期类型应该用单引号括起来。 3 4 # a. 数值类型 5 # 整数类型:tinyint, smallint, mediumint, int, bigint 6 # 小数类型:float(M,D), double(M,D), decimal(M, D) 7 8 # b.日期类型 9 # year, date, time, datetime, timestamp 10 # datetime vs timestamp 11 # 1) datetime的默认值是null, timestamp的默认值是now() 12 create database day17; 13 use day17; 14 create table t_time( 15 a datetime, 16 b timestamp 17 ); 18 insert into t_time (a) values (now()); 19 insert into t_time (b) values (now()); 20 select * from t_time; 21 # 2) datetime的值与时区无关, timestamp的值会随着时区的改变而改变。 22 set time_zone = '+10:00'; 23 select * from t_time; 24 set time_zone = '+8:00'; 25 select * from t_time; 26 27 # c.字符串类型 28 # char(M), varchar(M), tinytext, text, mediumntext, longtext, enum, set 29 # char(M): M个字节 30 # varchar(M): L+1个字节(L字符的长度) 31 # enum: 如果enum有非空约束,那么它的默认值是定义时的第一个元素。 32 create table t_enum ( 33 gender enum('male', 'female') not null, 34 hobby enum('a', 'b', 'c', 'd') 35 ); 36 insert into t_enum (gender) values ('female'); 37 insert into t_enum (hobby) values ('a'); 38 select * from t_enum; 39 40 insert into t_enum (hobby) values (null); 41 insert into t_enum (hobby) values ('x'); 42 insert into t_enum (hobby) values ('ab'); 43 44 create table t_set ( 45 hobby set('a', 'b', 'c', 'd') 46 ); 47 insert into t_set values ('a'); # Y 48 insert into t_set values ('x'); # N 49 insert into t_set values ('a,b,d'); # Y 50 insert into t_set values ('a,,b,x'); # N 51 insert into t_set values ('c,a,d'); # Y 52 select * from t_set; 53 54 # d.二进制类型 55 # bit(M), binary(M), varbinary(M), tinyblob, blob, mediumnblob, longblob
3.2DML数据操纵语言结合DQL
- DML:Data Manipulation Language
- 作用:用于向数据库表中插入、删除、修改数据。
- 常用关键字: INSERT UPDATE DELETE
Insert语句
- 使用 INSERT 语句向表中插入数据。
INSERT INTO table [(column [, column...])] VALUES (value [, value...]);
- 插入的数据应与字段的数据类型相同。
- 数据的大小应在列的规定范围内,例如:不能将一个长度为80的字符串加入到长度为40的列中。
- 在values中列出的数据 。
- 字符串和日期型数据应包含在单引号中。
- 插入空值 insert into table value(null)
Insert语句练习
练习:使用insert语句向表中插入三个员工的信息。
Update语句
- 使用 update语句修改表中数据。
UPDATE tbl_name SET col_name1=expr1 [, col_name2=expr2 ...] [WHERE where_definition]
- UPDATE语法可以用新值更新原有表行中的各列。
- SET子句指示要修改哪些列和要给予哪些值。
- WHERE子句指定应更新哪些行。如没有WHERE子句,则更新所有的行。
Update语句练习
- 在上面创建的employee表中修改表中的纪录
- 将所有员工薪水修改为5000元。
- 将姓名为‘henson’的员工薪水修改为3000元。
- 将姓名为’lisi’的员工薪水修改为4000元, job改为ccc。
- 将‘lan zhao’的薪水在原有基础上增加10000元。
Delete语句
- 使用 delete语句删除表中数据。
delete from table_name [WHERE where_definition]
- 如果不使用where子句,将删除表中所有数据。
- Delete语句不能删除某一列的值(可使用update)删除的单位是行(行)
- 使用delete语句仅删除记录,不删除表本身。如要删除表,使用drop table语句。
delete会删除一条记录,如果只是想删除一条记录的某个属性的值,使用update语句将其置为空即可。
Delete语句练习
- 删除表中名称为‘henson’的记录。
- 删除表中所有记录。
3.3DQL数据查询语言(简单查询)
- DQL:Data Query Language
- 作用:查询表中的数据。
- 关键字: SELECT
常见运算符介绍
- 算术运算符 + - * / %
- 比较运算符
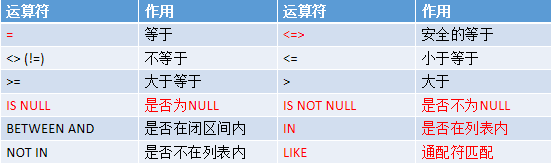
- 逻辑运算符 NOT(!) AND(&&) OR(||)
- 位操作运算符 & | ~ ^ << >>
测试计算
虽然 SELECT 语句通常用于从表中检索数据,但我们也可以用它计算表达式和函数的值。如:
SELECT 3*2; -- 计算表达式3*2的值
SELECT NOW(); -- 查看当前的时间
SELECT TRIM(' ab cd ‘); -- 修剪字符串' ab cd '左右两边的空白
SELECT CONCAT('ab','cd’); -- 拼接字符串'ab'和'cd'
查询单列
SELECT column_name FROM table_name;
如:查询表 t_students 中学生的姓名。
查询多列
SELECT col_name1, col_name2, … , col_namen
FROM table_name;
如:我们查询 t_students 中学生的姓名和各科成绩。
查询所有列
SELECT * FROM table_name;
如:查询 t_students 表中的所有数据。
使用 WHERE 子句过滤记录
SELECT * | {column_names}
FROM table_name
WHERE <filter_condition>;
- filter_condition 是一个逻辑表达式,即表达式的结果是布尔类型。
练习:
- 1. 查询语数外总成绩大于 180 的同学信息;
- 2. 查询数学成绩在[80,90]区间的同学姓名;
- 3. 查询各科都及格的同学姓名;
- 4. 查询一班和二班的同学信息;
DISTINCT 过滤相同的记录
SELECT DISTINCT {column_names}
FROM table_name;
如:查询 t_students 表中的不同班级数据。
限制结果
SELECT 语句返回所有匹配的记录。但是如果我们只想返回第一行或者一定数量的行,这该怎么办呢?
在 MySQL 中,我们可以用 LIMIT 关键字实现这一要求。
LIMIT offset, nums; -- LIMIT 3, 4; --OR LIMIT nums OFFSET offset; -- LIMIT 4 OFFSET 3
如:查询 t_students 表中第3到第5条记录;
对查询结果进行排序
我们可以使用 ORDER BY 子句对查询结果进行排序。
- 对单列排序
如:对数学单科成绩从低到高进行排序。
- 对多列排序
如:对语数外三科成绩进行排序。
- 指定排序方向(ASC, DESC)
如:对语文降序,数学升序,外语降序排序。
练习: 查询总成绩前三名同学的信息。
计算字段
我们想查询同学的总成绩信息,该怎么办?这时候计算字段就可以派上用场了。计算字段并不实际存在于数据库表中。计算字段是运行时在SELECT语句内创建的。
SELECT name, chinese + math + english FROM t_students;
别名
当然,我们可以给 Chinese + math + english 起一个更简单直接一点的名字。AS 关键字就可以做到这一点。
SELECT name, chinese + math + english AS total FROM t_students;
聚合函数
COUNT()
- COUNT(*) 计算表中的总行数;
- COUNT(column_name) 计算指定列下的总行数,计算时将忽略值为NULL的行。
SUM():返回指定列的所有值之和,计算时将忽略值为NULL的行;
AVG():返回指定列的平均值,计算时将忽略值为NULL的行;
MAX():返回指定列的最大值,计算时将忽略值为NULL的行;
MIN():返回指定列的最小值,计算时将忽略值为NULL的行;
练习:
- 查询每个同学的总成绩,平均成绩,并用别名表示;
- 查询数学最大值,并用别名表示;
- 查询外语最小值,并用别名表示;
- 查询全体学生的语数外各科平均成绩,并用别名表示;
分组查询
比如:我们想统计各班学生的人数,该怎么办?这时候我们就得用到分组的概念。在 SQL 中,我们使用 GROUP BY 关键字对数据进行分组。
[GROUP BY {column_names}] [HAVING <filter_condition>]
- 使用 HAVING 过滤分组
如:查询人数大于2的班级
- 多字段分组
GROUP BY 关键字后可以接多个列名,其意思是从左到右,按层次分组。即先按第一个字段分组,然后在第一个字段值相同的记录中,再根据第2个字段的值进行分组…(多个字段看成一个整体)
如:对学生按语文和数学成绩分组。[GROUP_CONCAT() 函数]
- 分组和排序
我们经常发现,用 GROUP BY 分组的数据确实是以分组顺序输出的。此外,即使特定的 DBMS 总是按给出的 GROUP BY 子句排序数据,用户也可能会要求以不同的顺序排序。应该提供明确的 ORDER BY 子句,即使其效果等同于GROUP BY子句。
如:查询人数少于10的班级,并按人数降序排序。
1 ######################################### DML ################################## 2 # a. 插入 3 # 语法:insert into tb_name [(column [, column...])] values (val, [val, ...]) 4 create table t_user ( 5 id int, 6 name varchar(20), 7 age int, 8 gender enum('male', 'female') 9 ); 10 insert into t_user values (1, 'thomas_he', 18, 'male'); 11 insert into t_user (name, id) values ('茜茜', 2); 12 insert into t_user (id, name, age) values (3, '张三', 30), (4, '李四', 40); 13 14 create table user ( 15 id int, 16 name varchar(20), 17 age int, 18 gender enum('male', 'female') 19 ); 20 insert into user (select * from t_user); 21 select * from user; 22 23 # b.修改 24 # 语法:update tb_name set col_name=val [, col_name=val...] [where 子句] 25 # 注意事项:如果没有where子句就会更新所有行 26 # 练习1: 把t_user表中所有人的年龄改为18 27 update t_user set age=18; 28 select * from t_user; 29 # 练习2:把名字为茜茜的用户的年龄改为16, 性别改成female 30 update t_user set age=16, gender='female' where name='茜茜'; 31 select * from t_user; 32 33 # c. 删除 34 # 语法:delete from tb_name [where 子句] 35 # 注意事项: 36 # 1) 删除的基本单位时记录, 如果不想删除记录而只是想删除这条记录某个字段的值, 我们可以用update将该字段置为null 37 # 2) 如果没有where子句,就会删除表中所有的记录 38 # 3) delete只会删除记录,不会删除表。如果要删除表,可以使用drop table 39 # 练习1:删除名字为张三的记录 40 delete from t_user where name='张三'; 41 select * from t_user; 42 # 练习2:清空t_user表中的所有记录 43 delete from t_user; 44 select * from t_user; 45 show tables; 46 desc t_user; 47 48 ################################# 数据库备份和恢复 ############################## 49 # a. 恢复 50 # 1) 在cmd中, mysql -u $user -p $db_name < file 51 # 2) 登录mysql服务, 进入数据库 source file (注意:后面不要加分号) 52 53 # b. 备份 54 # 在cmd中, mysqldump -u $user -p $db_name > file 55 56 ################################ 常用运算符 #################################### 57 # a. 算术运算符:+ - * / % 58 # b. 比较运算符:=, <>(!=), >, <, >=, <=, <=>, is null, is not null 59 # between and, in, not in, like 60 # = 和 <=> 61 # 练习:查询没有辅助角色定义的英雄有哪些? 62 select name, role_assist from heros where role_assist = null; 63 select name, role_assist from heros where role_assist <=> null; 64 select name, role_assist from heros where role_assist is null; 65 select name, role_assist from heros where role_assist is not null; 66 67 select null = null; 68 select null <> null; 69 select null <=> null; 70 select 1 <=> 1; 71 72 # between and 73 # 练习:查询hp_max大于等于7000,小于等于8050的英雄有哪些? 74 select name, hp_max from heros where hp_max >= 7000 and hp_max <= 8050; 75 select name, hp_max from heros where hp_max between 7000 and 8050; 76 77 # in, not in 78 # 练习:主要角色定义是战士和法师的英雄有哪些? 79 select name, role_main from heros where role_main = '战士' or role_main = '法师'; 80 select name, role_main from heros where role_main in ('战士', '法师'); 81 82 # 练习:主要角色定义是辅助和坦克的英雄有哪些? 83 select name, role_main from heros where role_main not in ('辅助', '坦克'); 84 85 # like 与通配符搭配使用, 进行模糊查询。 86 # %:匹配任何数目的字符,甚至包括零个字符 87 # _: 匹配一个字符 88 # 不同的DBMS,通配符可能不一样, 比如SQL Server是 * 匹配所有字符, ? 匹配一个字符 89 # 练习:查询名字中包含'太'的英雄。 90 select name from heros where name like '%太%'; 91 # 练习:除第一个字之外,其余字中包含'太'的英雄有哪些? 92 select name from heros where name like '_%太%'; 93 94 # c. 逻辑运算符:NOT(!) AND(&&) OR(||) 95 # d. 位运算符:& | ~ ^ << >> 96 97 ################################ 简单查询 ###################################### 98 # a. 计算表达式和函数的值 99 select 2 * 3; 100 select now(); 101 select year(now()); 102 select concat('ab', 'cd', 'xyz'); 103 select concat('"', trim(' abc xyz '), '"'); 104 select abs(-100); 105 106 # b. 查询表中的字段 107 # 查询单个字段的值,比如:查询 heros 表中所有英雄的名字。 108 select name from heros; 109 # 查询heors表中所有辅助角色定位 110 select role_assist from heros; 111 112 # 查询多个字段的值,多个字段之间用 `,` 分隔。 113 # 比如:查询 heros 表中所有英雄的名字,最大生命值,最大法力值以及主要角色定位。 114 select name, hp_max, mp_max, role_main from heros; 115 116 # 查询所有字段,还可以用 `*` 代指所有字段。比如:查询 heros 表中所有数据。 117 select * from heros; 118 119 # c. 使用 WHERE 子句过滤记录 120 select * from heros where 0; 121 select * from heros where 1; 122 select * from heros where name='花木兰'; 123 124 # d. 给字段起别名 125 # `AS` 可以给字段起别名。比如: 126 SELECT name, hp_max AS hp, mp_max AS mp FROM heros; 127 SELECT name, hp_max hp, mp_max mp FROM heros; 128 129 # e. 去除重复行 130 # `DISTINCT` 可以对查询结果去重。 131 # 注意事项: 132 # a. DISTINCT 关键字必须放在所有查询字段的前面 133 # b. DISTINCT 是对所有查询字段的组合进行去重,也就是说每个字段都相同,才认为两条记录是相同 134 # 练习:查询主要角色定位有哪些? 135 select role_main from heros; 136 select distinct role_main from heros; 137 select distinct role_main, role_assist from heros; 138 139 # f.排序 140 # `ORDER BY` 可以对结果集进行排序。`ASC` 表示升序,`DESC` 表示降序,默认情况为升序。 141 # 练习:查询所有英雄,并按最大生命值排序。 142 select name, hp_max from heros order by hp_max; 143 select name, hp_max from heros order by hp_max asc; 144 select name, hp_max from heros order by hp_max desc; 145 146 # 还可以对多个字段进行排序。即先按照第一个字段排序,当第一个字段相同时,再按照第二个字段排序,依此类推。 147 # 练习:查询所有英雄,先按最大生命值排序,再按照最大法力值排序 148 select name, hp_max, mp_max from heros order by hp_max, mp_max; 149 select name, hp_max, mp_max from heros order by hp_max asc, mp_max desc; 150 151 # `ORDER BY` 可以对非选择字段进行排序,也就是说排序的字段不一定要在结果集中。 152 SELECT name, hp_max FROM heros ORDER BY hp_max ASC, mp_max DESC; 153 154 # 甚至,我们还可以对计算字段进行排序。 155 SELECT name, hp_max FROM heros ORDER BY (hp_max + mp_max) DESC; 156 157 # g. 限制结果集 158 # `LIMIT` 可以限制结果集的数量。它有两种使用方式:`LIMIT offset, nums` 和 `LIMIT nums OFFSET offset`。 159 # 注意:不同的 DBMS 用来限制结果集的关键字是不一样的。比如,Microsoft SQL Server 和 Access 使用的是 TOP 关键字。 160 # 练习:我们想查询最大生命值最高的5名英雄。 161 select name, hp_max from heros order by hp_max desc limit 0, 5; 162 select name, hp_max from heros order by hp_max desc limit 5 offset 0; 163 select name, hp_max from heros order by hp_max desc limit 5; 164 165 # 分页查询 (rows, page) limit rows offset rows * (page - 1) 166 167 # h. 计算字段 168 # 计算字段并不实际存在于数据库表中,它是由表中的其它字段计算而来的。一般我们会给计算字段起一个的别名。 169 SELECT name, hp_max + mp_max FROM heros; 170 SELECT name, hp_max + mp_max AS total_max FROM heros; 171 172 # i. 聚合函数 173 # count() 174 # `COUNT(*)` 可以统计记录数。可以统计null行 175 # 练习:查询heros表中有多少条记录 176 select count(*) from heros; 177 create table temp ( 178 a int 179 ); 180 insert into temp values (null); 181 select * from temp; 182 select count(*) from temp; 183 184 # COUNT()` 作用于某个具体的字段,可以统计这个字段的非 `NULL` 值的个数。 185 # 练习:查询有辅助角色定义的英雄有多少个 186 select count(role_assist) from heros; 187 188 # sum() 189 # `SUM()` 用于统计某个字段非 `NULL` 值的和。 190 SELECT SUM(hp_max) FROM heros; 191 192 # avg() 193 # `AVG()` 用于统计某个字段非 `NULL` 值的平均值。 194 # SELECT AVG(hp_max) FROM heros; 195 SELECT round(AVG(hp_max), 2) FROM heros; 196 197 # max() 198 # `MAX()` 用于统计某个字段非 `NULL` 值的最大值。 199 SELECT MAX(hp_max) FROM heros; 200 # min() 201 # `MIN()` 用于统计某个字段非 `NULL` 值的最小值。 202 SELECT MIN(hp_max) FROM heros; 203 204 # distinct 205 # 我们还可以对字段中不同的值进行统计。先用 `DSITINCT` 去重,再用聚合函数统计。 206 select count(hp_max) from heros; 207 SELECT COUNT(DISTINCT hp_max) FROM heros; 208 209 # j.分组 210 # `GROUP BY` 可以对记录进行分组。 211 # 1) 搭配聚合函数使用 212 # 练习:按照主要角色定位进行分组,并统计每一组的英雄数目。 213 select role_main, count(*) from heros group by role_main; 214 # 练习:按照次要角色定位进行分组,并统计每一组的英雄数目。 215 select role_assist, count(*) from heros group by role_assist; 216 217 # 2) GROUP_CONCAT 218 # 如果我们想知道每种角色的英雄都有哪些? 219 # select role_main, name from heros group by role_main; 220 select role_main, group_concat(name) from heros group by role_main; 221 222 # 3) 多字段分组 223 # 我们可以对多个字段进行分组。也就是说,每个字段的值都相同的记录为一组。 224 SELECT COUNT(*) AS num, role_main, role_assist 225 FROM heros 226 GROUP BY role_main, role_assist 227 ORDER BY num DESC; 228 229 # 4) HAVING 过滤分组 230 # `HAVING` 可以过滤分组。 231 # 我们想要按照英雄的主要角色定位,次要角色定位进行分组,并且筛选分组中英雄数目大于 5 的组, 232 # 最后根据每组的英雄数目从高到低进行排序。 233 SELECT COUNT(*) AS num, role_main, role_assist 234 FROM heros 235 GROUP BY role_main, role_assist 236 HAVING num > 5 237 ORDER BY num DESC; 238 239 # 练习:筛选最大生命值大于 6000 的英雄,按照主要角色定位,次要角色定位分组, 240 # 并且筛选英雄数目大于 5 的分组,最后按照英雄数目从高到低进行排序。 241 SELECT COUNT(*) AS num, role_main, role_assist 242 FROM heros 243 WHERE hp_max > 6000 244 GROUP BY role_main, role_assist 245 HAVING num > 5 246 ORDER BY num DESC;
SELECT语句的执行顺序
- 关键字的顺序
SELECT…FROM…WHERE…GROUP BY…HAVING…ORDER BY…LIMIT; - 底层执行的顺序
FROM > WHERE > GROUP BY > HAVING > SELECT字段 > DISCTINCT > ORDER BY > LIMIT;

作业:
在王者荣耀的heros表中,做如下查询:
- 查询名字长度为3的近战英雄(提示:char_length()函数可以求字符串的长度)
- 查询既有主要角色定位,又有辅助角色定位的英雄有哪些?
- 查询李姓的英雄有哪些?
- 查询不同的攻击范围?
- 查询最大生命值在[6500, 8000]范围, 并且主要角色定位为刺客或者战士的英雄有哪些,并且按照生命值从大到小排序。
- 查询初始物理攻击最高的前3名英雄
1 use king_of_honor; 2 # a. 查询名字长度为3的近战英雄(提示:char_length()函数可以求字符串的长度) 3 select name,attack_range from heros where char_length(name)=3 and attack_range='近战'; 4 5 # b. 查询既有主要角色定位,又有辅助角色定位的英雄有哪些? 6 select name, role_main, role_assist from heros where role_main is not null and role_assist is not null; 7 8 # c. 查询李姓的英雄有哪些? 9 select name from heros where name like '李%'; 10 11 # d. 查询不同的攻击范围? 12 select distinct attack_range from heros; 13 14 # e. 查询最大生命值在[6500, 8000]范围, 并且主要角色定位为刺客或者战士的英雄有哪些,并且按照生命值从大到小排序。 15 select name, hp_max, role_main 16 from heros 17 where hp_max between 6500 and 8000 18 and role_main in ('刺客','战士') 19 order by hp_max desc; 20 21 # f. 查询初始物理攻击最高的前3名英雄 22 select name,attack_start 23 from heros 24 order by attack_start desc 25 limit 3 offset 0;

 浙公网安备 33010602011771号
浙公网安备 33010602011771号