
第二阶段-day02_Linked
今天我们主要将了数组和链表。
复习昨天
集合类: a.集合类可以自己调整大小 b.只能存储引用类型的数据 c.有丰富的API Collection 概述: API: 增: boolean add(E e) boolean add(Collection c) 删: void clear() boolean remove(Object o) boolean removeAll(Collection c) boolean retainAll(Collection c) 查: boolean contains(Object o) boolean containsAll(Collection c) 获取集合属性: int size() boolean isEmpty() 遍历: Object[] toArray() Iterator iterator() Iterator 概述: 设计原理:迭代器设计模式 API: boolean hasNext() E next() void remove() 注意事项: a. 警惕并发修改异常 b. 用迭代器遍历的时候,不要使用while循环,可以使用for循环,最好使用foreach List 概述: API: 增: void add(int index,E e) void addAll(int index, Collection c) 删: E remove(int index) 改: E set(int index, E e) 查: E get(int index) int indexOf(Object o) int lastIndexOf(Object o) 获取子串: List subList(int fromIndex, int toIndex) 遍历: ListIterator listIterator() ListIterator listIterator(int index)
接着昨天的List讲
List subList(int fromIndex, int toIndex):获取子串,左包右不包
1 package com.cskaoyan.list; 2 3 import java.util.ArrayList; 4 import java.util.List; 5 6 /* 7 视图技术 8 List subList(int fromIndex, int toIndex) 9 */ 10 public class ListDemo1 { 11 public static void main(String[] args) { 12 List list = new ArrayList(); 13 list.add("hello"); 14 list.add("world"); 15 list.add("java"); 16 17 List subList = list.subList(1, 2); 18 System.out.println(subList); //[world] 19 20 subList.set(0, "WORLD"); 21 System.out.println(subList); //[WORLD] 22 System.out.println(list);//[hello, WORLD, java] 23 } 24 }
发现list里的数据也改变了。→视图技术。
sublist与list公用同一份数据,修改sublist,list中的数据也会修改。
视图技术原理:sublist是以成员内部类的形式存在的,继承了AbstractList,这个抽象类实现了list接口。
∴sublist是以成员内部类的形式存在的,这样,它就可以访问外部类的数据。
视图技术应用场景:总公司的数据是分公司提交上来的。分公司的数据更改,总公司的数据也要改变。
List:
ListIterator<E> listIterator()
ListIterator<E> listIterator(int index)
1 package com.cskaoyan.list; 2 3 import java.util.ArrayList; 4 import java.util.List; 5 import java.util.ListIterator; 6 7 /* 8 List: 9 ListIterator<E> listIterator() 10 ListIterator<E> listIterator(int index) 11 12 ListIterator接口 13 概述:列表迭代器,允许程序员按任一方向遍历列表、迭代期间修改列表,并获得迭代器在列表中的当前位置。 14 API: 15 遍历: 16 boolean hasNext() 17 E next() 18 boolean hasPrevious() 19 E previous() 20 获取位置: 21 int previousIndex() 22 int nextIndex() 23 修改列表: 24 void add(E e) 25 void remove() 26 void set(E e) 27 */ 28 public class ListDemo2 { 29 public static void main(String[] args) { 30 List list = new ArrayList(); 31 list.add("hello"); 32 list.add("world"); 33 list.add("java"); 34 35 // ListIterator it = list.listIterator(); 36 /*ListIterator it = list.listIterator(2); 37 System.out.println(it.next()); //java*/ 38 39 // 正向遍历 40 /*for(ListIterator it = list.listIterator(); it.hasNext(); ){ 41 String s = (String) it.next();// 为什么会报错呢? 42 System.out.println(s); 43 }*/ 44 45 // 逆向遍历 46 /* for(ListIterator it = list.listIterator(list.size()); it.hasPrevious(); ) { 47 String s = (String) it.previous(); 48 System.out.println(s); 49 }*/ 50 51 // int previousIndex() 52 // int nextIndex() 53 /* ListIterator it = list.listIterator(1); 54 // it.previous(); 55 it.next(); 56 it.next(); 57 System.out.println(it.previousIndex()); // 2 58 System.out.println(it.nextIndex());// 3*/ 59 60 61 // void add(E e) 在哪个位置添加元素?光标后面 62 /*ListIterator it = list.listIterator(2); 63 it.add("HelloKitty"); 64 System.out.println(list);*/ 65 66 //练习:在world后面添加"HelloKitty" 67 /*for(ListIterator it = list.listIterator(); it.hasNext(); ){ 68 String s = (String) it.next(); 69 // if ("world".equals(s)) it.add("HelloKitty"); 70 *//*if ("world".equals(s)) { 71 int index = it.nextIndex(); 72 list.add(index, "HelloWorld"); 73 }*//* 74 } 75 System.out.println(list);*/ 76 77 //练习:在world前面添加"HelloKitty" 78 /* for(ListIterator it = list.listIterator(list.size()); it.hasPrevious(); ) { 79 String s = (String) it.previous(); 80 if ("world".equals(s)) it.add("HelloKitty"); 81 } 82 System.out.println(list);*/ 83 84 // void remove() 删除哪个元素?删除的是最近返回的元素 85 /*ListIterator it = list.listIterator(); 86 it.next(); 87 it.remove(); 88 System.out.println(list);*/ 89 90 /*ListIterator it = list.listIterator(list.size()); 91 it.previous(); 92 it.remove(); 93 System.out.println(list);*/ 94 95 // 如果最近没有返回元素,会怎样 96 /*ListIterator it = list.listIterator(); 97 it.remove();*/ // IllegalStateException 98 99 /*ListIterator it = list.listIterator(); 100 it.next(); 101 it.add("Allen"); 102 it.remove(); //IllegalStateException 103 System.out.println(list);*/ 104 105 // 并发修改异常 106 /*for(ListIterator it = list.listIterator(); it.hasNext();) { 107 // if ("hello".equals(it.next())) it.remove(); 108 if ("hello".equals(it.next())) { 109 int index = it.previousIndex(); 110 list.remove(index); 111 } 112 } 113 System.out.println(list);*/ 114 115 // void set(E e) 替换哪个元素?最近返回的元素 116 // 练习:把"java"替换成"javaSE" 117 /*for(ListIterator it = list.listIterator(); it.hasNext();) { 118 // if ("java".equals(it.next())) it.set("javaSE"); 119 if ("java".equals(it.next())) { 120 int index = it.previousIndex(); 121 list.set(index, "javaSE"); 122 } 123 }*/ 124 ListIterator it = list.listIterator(); 125 // it.set("javaSE"); // IllegalStateException 126 it.next(); 127 it.remove(); 128 it.set("javaSE"); // IllegalStateException 129 System.out.println(list); 130 } 131 }
常见的数据结构
- 数组
- 链表
- 栈
- 队列
- 树
- 哈希表
- 图
数组
Q1: 数组我们都很熟悉,那你理解的数组是什么样的呢?它的最主要特点是什么呢?
Q2: 为什么数组的索引是一般都是从0开始的呢?
Q3: 为什么数组的效率比链表高?
Q1: 数组我们都很熟悉,那你理解的数组是什么样的呢?它的特点是什么呢?
A1:数组的本质是固定大小的连续的内存空间,并且这片连续的内存空间又被分割成等长的小空间。它最主要的特点是随机访问。
数组的长度是固定的
数组只能存储同一种数据类型的元素
数组只能存储同一种数据类型的元素
注意:在Java中只有一维数组的内存空间是连续,多维数组的内存空间不一定连续。
那么数组又是如何实现随机访问的呢?
寻址公式:i_address = base_address + i * type_length
Q2: 为什么数组的索引是一般都是从0开始的呢?
假设索引不是从0开始的,而是从1开始的,那么我们有两种处理方式:
寻址公式变为: i_address = base_address + (i – 1) * type_length
浪费开头的一个内存空间,寻址公式不变。
在计算机发展的初期,不管是CPU资源,还是内存资源都极为宝贵,所以在设计编程语言的时候,索引就从0开始了,而我们也一直延续了下来。
Q3: 为什么数组的效率比链表高?
CPU、内存和IO设备,它们传输数据的速率是存在很大差异的。
那么根据木桶理论:木桶能装多少水,取决于最短的那块木板。程序的性能主要取决于IO设备的性能?也就是说,我们提升CPU和内存的传输速率收效甚微。
实际是这样的吗?当然不是!那我们是怎么解决它们之间的速率差异的呢?
CPU 和 内存
高速缓存(预读)
编译器的指令重排序
高速缓存(预读)
编译器的指令重排序
内存和 IO
缓存:将磁盘上的数据缓存在内存。
缓存:将磁盘上的数据缓存在内存。
CPU 和 IO
中断技术
数组可以更好地利用CPU的高速缓存!
中断技术
数组可以更好地利用CPU的高速缓存!
数组的基本操作

总结: 数组增删慢,查找快。
链表
形象地说,链表就是用一串链子将结点串联起来。
结点:包含数据域和指针域。
数据域:数据
指针域:下一个结点的地址
数据域:数据
指针域:下一个结点的地址
结点 ![]()
链表 ![]()
链表的分类:
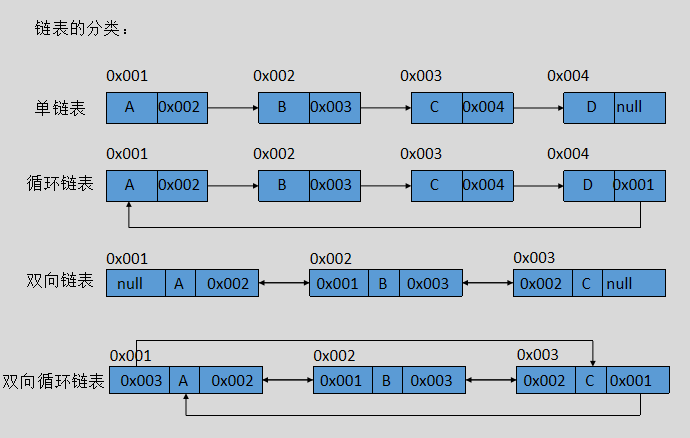
循环链表我们用的一般比较少,但是当处理的数据具有环形结构时,就特别适合用循环链表,比如约瑟夫问题。接下来我们讨论下单链表和双向链表。
单链表:

总结:链表增删快,查找慢。
双向链表:
很容易验证,前面那些操作,双向链表和单链表的时间复杂度是一样的。那为什么在工程上,我们用的一般是双向链表而不是单链表呢 (比如JDK中的 LinkedList & LinkedHashMap)?
那自然是双向链表有单链表没有的独特魅力——它有一条指向前驱结点的链接。
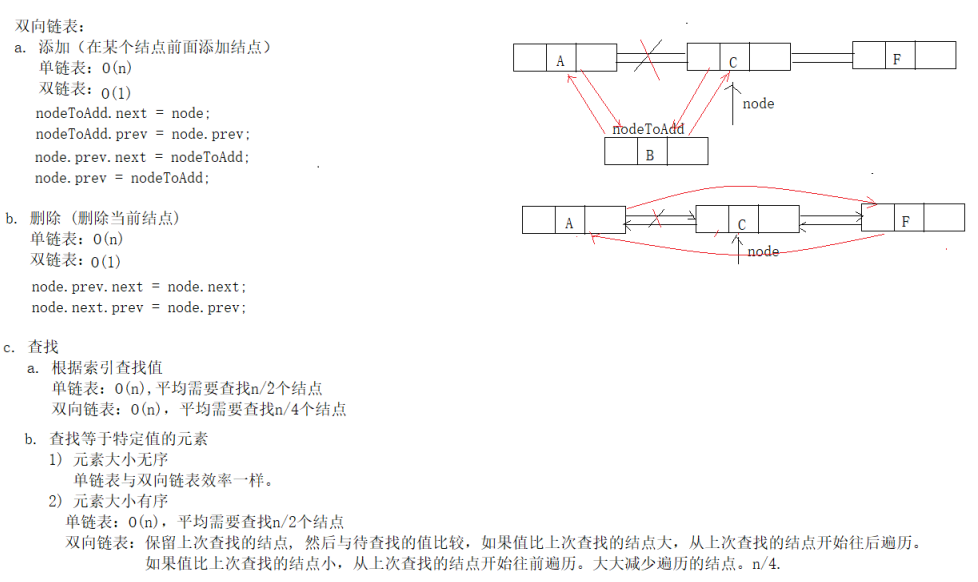
总结:虽然双向链表更占用内存空间,但是它在某些操作上的性能是优于单链表的。
思想:用空间换取时间。
缓存就是一种用空间换取时间的技术。
内存大小是有限的,所以缓存不能无限大。那么当缓存满的时候,再向缓存中添加数据,该怎么办呢?
缓存淘汰策略:
① FIFO (First In First Out)
② LFU (Least Frequently Used)
③ LRU (Least Recently Used)
① FIFO (First In First Out)
② LFU (Least Frequently Used)
③ LRU (Least Recently Used)
LRU算法中我们就用到了链表!

练习:
- 求链表的中间元素
- 判断链表中是否有环
- 反转单链表
1 package com.cskaoyan.exercise; 2 3 public class Node { 4 int value; 5 Node next; 6 7 public Node(int value) { 8 this.value = value; 9 } 10 11 public Node(int value, Node next) { 12 this.value = value; 13 this.next = next; 14 } 15 }
1.求链表的中间元素
1 package com.cskaoyan.exercise; 2 /* 3 求链表的中间元素 4 示例: 5 输入:1 --> 2 --> 3 6 输出:2 7 输入:1 --> 2 --> 3 --> 4 8 输出:2 9 10 Q1:如果是数组,我们可以求中间元素? 11 arr[(arr.length-1) / 2] 12 Q2: 13 1.先求得长度length 14 2.再从头开始遍历,一边遍历,一边计算当前结点得索引。 15 当索引为 (length-1)/2 时,返回这个结点的值。 16 */ 17 public class Ex1 { 18 public static int middleElement(Node head) { 19 // 求链表的长度 20 int length = 0; 21 Node x = head; 22 while (x != null) { 23 length++; 24 x = x.next; //x指向下一个结点 25 } 26 // 从头开始遍历,找索引为 (length-1)/2 的结点 27 int index = 0; 28 x = head; 29 while (index < (length - 1) / 2) { 30 index++; 31 x = x.next; 32 } 33 return x.value; 34 } 35 36 public static void main(String[] args) { 37 // 1 --> 2 --> 3 38 /*Node head = new Node(3); 39 head = new Node(2, head); 40 head = new Node(1, head); 41 System.out.println(middleElement(head));*/ 42 43 // 1 --> 2 --> 3 --> 4 44 /* Node head = new Node(4); 45 head = new Node(3, head); 46 head = new Node(2, head); 47 head = new Node(1, head); 48 System.out.println(middleElement(head));*/ 49 } 50 }
2.判断链表中是否有环
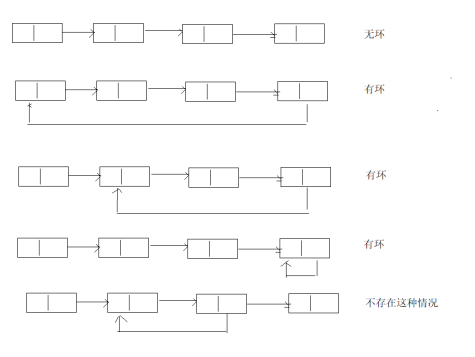
1 package com.cskaoyan.exercise; 2 /* 3 判断链表中是否有环 4 1. 给一个阈值(10ms),如果在遍历链表的过程中10ms还没有结束,就认为有环。 5 2. 迷雾森林 6 Collection visited = new ArrayList(); 7 */ 8 public class Ex2 { 9 public static boolean hasCircle(Node head) { 10 11 } 12 }

 浙公网安备 33010602011771号
浙公网安备 33010602011771号