
CUDA __shared__ thread、block、grid之间的一维关系 (例子chapter5 dot点积(GPU高性能编程))
chapter5里重要的例子是dot,来解释一个block内多个thread的共享内存和同步。
__shared__共享内存:“对于在GPU上启动的每个线程块,cuda c编译器都将创建该变量的一个副本。线程块中的每个线程都共享这块内存,并和其他线程块无关,这使一个线程块中多个线程能够在计算上进行通信和协作”
__syncthreads():确保线程块中的每个线程都执行完__syncthreads()前面的语句后,在往下执行。
例子是Grid->一维Block->一维Thread:
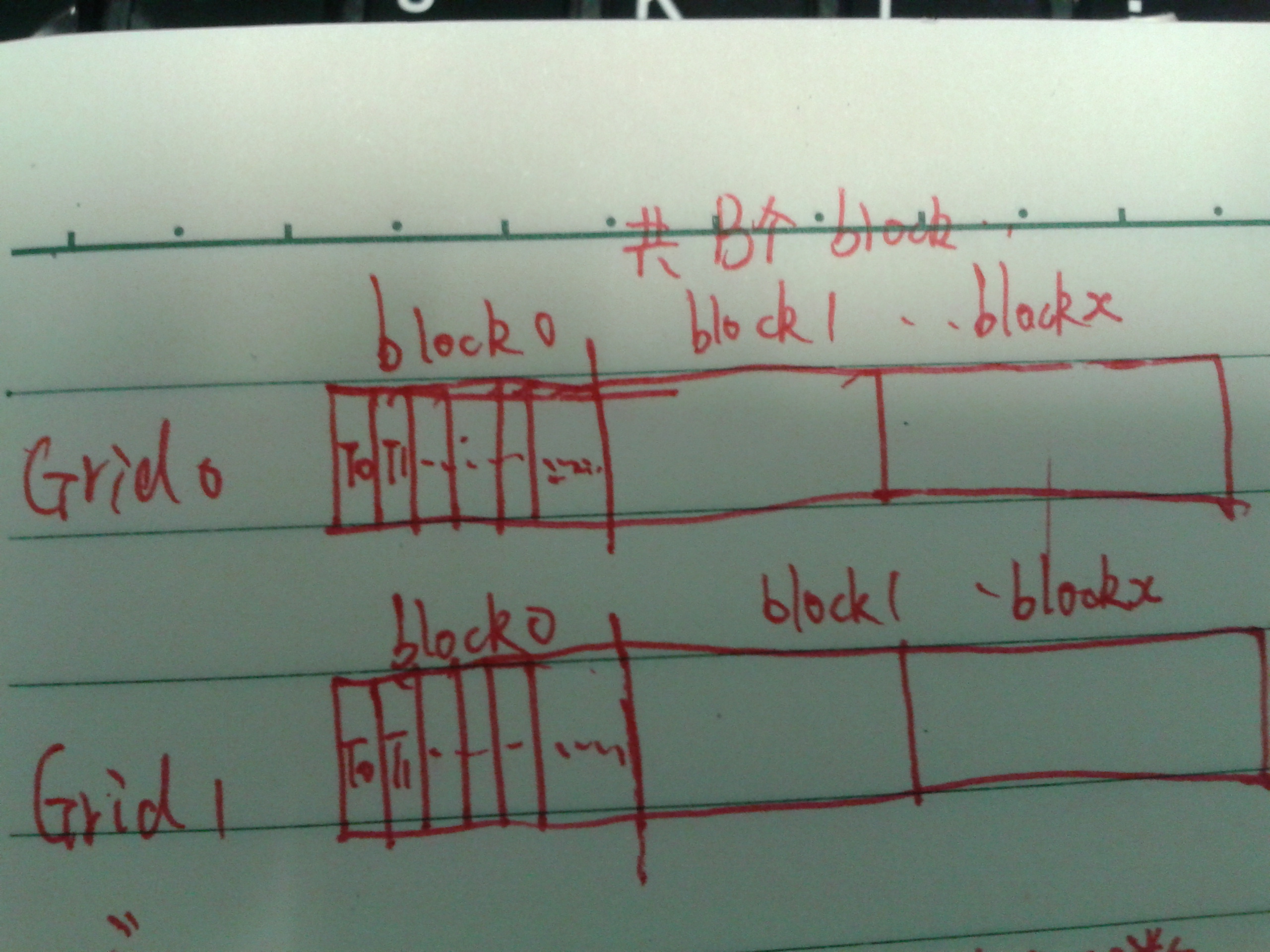

通过实例代码来分析:
#include <iostream>
#include "cuda_runtime.h"
#include "device_launch_parameters.h"
#include "book.h"
#include "cpu_bitmap.h"
//1.minFun 对于每个Grid而言,选取block数比较少的,这样可以减少每个grid中最后一个block内thread的冗余。
int imin(int a,int b)
{
if(a>b)
{
return b;
}else{
return a;
}
}
const int N = 33*1;//整体线程的数量,即向量(a)*(b)中每个向量数组的大小
const int ThreadNumsPerBlock =256;//每个block中thread的数量
const int BlockNumsPerGrid = imin(32,(N+ThreadNumsPerBlock-1)/ThreadNumsPerBlock);//每个grid中block的数量,
__global__ void dot(float* a,float* b,float* c)//输入两个向量:a,b ;结果c大小为一个grid内block的大小,grid内每个block的位置对应数组c每个下标对应的数据,每个数据为多个grid相同的block下标下的thread的和,如图-1。
{
int everyThreadIndex = threadIdx.x+blockIdx.x*blockDim.x;//获取一个grid中thread的index
int cacheIndex = threadIdx.x;//获取一个block中thread的index
__shared__ float cache[ThreadNumsPerBlock];
float temp = 0;
while(everyThreadIndex<N)//多个grid的跳跃index,
{
temp += a[everyThreadIndex]*b[everyThreadIndex];
everyThreadIndex += blockDim.x*gridDim.x;//
}
cache[cacheIndex] = temp;//得到多个grid中 一个block里相应的一个thread的乘积的和
__syncthreads();
int i= blockDim.x/2;
while(i!=0) //一直纳闷这个怎么在多个线程中执行啊?应该是:一个thread执行到这里后,__syncthreads()之前一个语句等啊等,等到所有一个block里的threads全都执行一遍后,才往下进行
{
if(cacheIndex<i)
{
cache[cacheIndex]= cache[cacheIndex]+cache[cacheIndex+i];//while里的这句是在block里不同的thread里执行的
}
__syncthreads();
i=i/2;//当每个thread都执行后,才能进行长度折半
}
if(0==cacheIndex)
{
c[blockIdx.x] = cache[0];
}
}
int main(void)//
{
float *host_a,*host_b,*host_c;
float *device_a,*device_b,*device_c;
host_a = (float*)malloc(N*sizeof(float));
host_b = (float*)malloc(N*sizeof(float));
host_c = (float*)malloc(BlockNumsPerGrid*sizeof(float));
for (int i=0; i<N; i++) {
host_a[i] = i;
host_b[i] = i*2;
}
//gpu上分配内存
cudaMalloc((void**)&device_a,N*sizeof(float));
cudaMalloc((void**)&device_b,N*sizeof(float));
cudaMalloc((void**)&device_c,BlockNumsPerGrid*sizeof(float));
cudaMemcpy(device_a,host_a,N*sizeof(float),cudaMemcpyHostToDevice);
cudaMemcpy(device_b,host_b,N*sizeof(float),cudaMemcpyHostToDevice);
dot<<<BlockNumsPerGrid,ThreadNumsPerBlock>>>(device_a,device_b,device_c);
cudaMemcpy(host_c,device_c,BlockNumsPerGrid*sizeof(float),cudaMemcpyDeviceToHost);
float c=0;
for(int i=0;i<BlockNumsPerGrid;i++)
{
c = c + host_c[i];
}
#define sum_squares(x) (x*(x+1)*(2*x+1)/6)
std::cout<<"结果1:"<<c<<"结果2:"<<2 * sum_squares( (float)(N - 1) )<<std::endl;
cudaFree(device_a);
cudaFree(device_b);
cudaFree(device_c);
free(host_a);
free(host_b);
free(host_c);
return 0;
}
书中最后讲解了错误的修改方式:
while(i!=0)
{
if(cacheIndex<i)
{
cache[cacheIndex]= cache[cacheIndex]+cache[cacheIndex+i];//while里的这句是在block里不同的thread里执行的
__syncthreads();
}
i=i/2;//当每个thread都执行后,才能进行长度折半
}
原则是“线程执行相同的指令,不同的数据运算”
__syncthreads()中,cuda架构要确保一个block中每个thread都执行__syncthreads(),否则没有任何thread执行__syncthreads之后的操作。
当一些thread执行一条指令,而其他线程不需要时,这种情况称作线程发散(Thread Divergence).这种情况下要注意__syncthreads的位置。
小结:
1. dim3 a(x,y); dim3 b(x,y); <<<a,b>>> a:Grid中启动block的数量 b:Block中启动thread数量
2.注意线程块的向后取整(取上限); 还有通过 if(threadIndex<N)来确保thread的范围
3.__shared__和__syncthreads()的正确用法,并注意线程发散情况
4.使用线程与使用线程块相比有什么优势? :一:解决线程块数量的限制 二:进行部分的数据共享和通讯
5.一维:threadIdx.x: block中的thread索引 blockIdx.x :Grid中block索引 blockDim.x:一个Block中thread数量; gridDim.x:一个Grid中Block数量

 浙公网安备 33010602011771号
浙公网安备 33010602011771号