
APPROXIMATING CNNS WITH BAG-OF-LOCALFEATURES MODELS WORKS SURPRISINGLY WELL ON IMAGENET 论文笔记
- 摘要
深度神经网络(DNN)在许多复杂的感知任务中表现出色,但众所周知,很难理解他们如何做出决策。我们在此介绍ImageNet上的高性能DNN架构,其决策更容易解释。我们的模型是ResNet-50架构的一个名为BagNet的简单变体,它根据出现的情况对图像进行分类小的局部图像特征而不考虑它们的空间排序。这种策略与深度学习开始前流行的特征包(BoF)模型密切相关,并且在ImageNet上达到了惊人的高精度(33X33 px特征的top-5准确率为87.6%和17X17 px特征的Alexnet性能)。对局部特征的约束使得直接分析图像的每个部分如何影响分类。此外,BagNets在特征灵敏度,误差分布和图像部分之间的相互作用方面表现类似于最先进的深度神经网络,例如VGG-16,ResNet-152或DenseNet-169。这表明DNN在过去几年中比以前的特征分类器的改进主要通过更好的微调而不是通过质量上不同的决策策略来实现。
- 简介
在本文中,我们表明可以将DNN的性能和灵活性与BoF模型的可解释性结合起来,并且即使仅限于相当小的图像patches,最终的模型系列(称为BagNets)也能够在ImageNet上达到高精度。 考虑到BoF模型的简单性,我们想象许多用例,为了更好的可解释性,可能需要牺牲一点精度,正如这常见的那样。 用于线性函数逼近。 这包括诊断失败案例(例如对抗性案例)或非iid。 设置(例如,域转移),基准诊断工具(例如归因方法)或用作计算机视觉pipeline的可解释部分(例如,在本地特征之上具有关系网络)。
此外,我们证明了BagNets的决策行为与流行的DNN在计算机视觉中的相似性。 这些相似之处表明,当前的网络架构基于大量相对较弱和局部的统计规律做出决策,并且没有充分鼓励 - 无论是通过其架构,训练程序还是任务规范 - 来学习更多可以更好地理解图像的不同部分因果关系的整体特征。
- 模型框架
如果term向量之上的分类器是线性的,则BoF模型易于解释。 在这种情况下,输入的给定部分对分类器的影响独立于输入的其余部分。
基于这种见解,我们构建了一个基于线性DNN的BoF模型如下(参见图1):首先,我们使用多个堆叠的ResNet块从每个大小为qXq像素的图像块推断出2048维特征表示,并应用线性分类器来推断每个patch(热图)的类证据。 我们对所有patch中的类证据进行平均,以推断出图像级别的证据(logits)。 该结构与其他ResNets(He等人,2015)的不同之处仅在于替换了许多3X3的卷积为1X1,从而将最顶层卷积层的感受域大小限制为qXq像素(详见附录)。 视觉词语没有明确的分配。 这可以通过稀疏投影添加到高维嵌入中,但我们没有看到可解释性的好处。 我们将得到的架构表示为BagNet-q并测试q∈[9;17;33]

请注意,我们模型的一个重要组成部分是局部特征表示之上的线性分类器。 这里的线性词指的是在聚合特征之上的线性空间聚合(简单平均)和线性分类器的组合。 分类器和空间聚合都是线性的并且因此可互换的事实允许我们精确地确定来自本地图像块的证据如何被集成到一个图像级决策中。
- 实验结果
在前两个小节中,我们研究了BagNets针对不同patch尺寸的分类性能,并展示了我们可以从其可解释结构中获得的见解。 此后我们比较BagNets与几种广泛使用的高性能DNN(例如VGG-16,ResNet-50,DenseNet-169)的行为,并证明他们的决策有许多相似之处。
对于每个qXq的patch,模型推断出每个ImageNet类的证据,从而产生高分辨率和非常精确的热图,显示图像的哪些部分对某些特定决定贡献最大。 我们将随机选择的十个测试图像的预测类别的热图显示在图2中。显然,大多数证据都围绕着物体的形状(例如crip或桨叶)或某些预测图像特征,如南瓜的发光边界。 此外,对于动物而言,眼睛或腿部很重要。 同样值得注意的是,BagNets几乎忽略了背景特征(如鹿形象中的森林)。

接下来,我们选择一个类并在所有验证图像上运行BagNets,以查找具有最多类证据的patch。这些patch中的一些取自该类的图像(即它们带有“正确的”证据),而其他patch来自另一类的图像(即这些patch可能导致错误分类)。在图3中,我们显示了来自几个类(行)和不同BagNets(列)的正确和不正确图像的前7个patch。这种可视化产生了许多见解:例如,书籍封套主要由封面上的文字识别,导致与T恤或网站上的其他文字混淆。类似地,打字机的键通常被解释为手持计算机的证据。 Tench类是一种大型鱼类,通常用绿色背景前的手指识别。仔细检查发现,tench图像通常以鱼类像奖杯为特征,从而使手和手指保持其非常具有预测性的图像特征。火烈鸟被它们的喙检测到,这使得它们容易与其他鸟类如鹳混淆,而新郎主要通过从西装到颈部的过渡来识别,这是许多其他类别中的图像特征。

在图4中,我们分析了由BagNet-33和VGG-16错误分类的图像。 在第一个例子中,由于图像顶部的绿色黄瓜,地面真相类“切肉刀”与“奶奶史密斯”混淆了。 观察每个热图旁边绘制的三个最具预测性的patch,它们显示了绿色黄瓜片的苹果般边缘,这种选择看起来很容易理解。 类似地,如果孤立地观察,“顶针”图像中的局部斑块类似于防毒面具。 “超短裙”图像中的字母非常突出,因此导致“书夹”预测,而在最后一张图像中,绿色毯子具有类似于卡巴克索的纹理。

图像加扰 BoF网络的一个核心组成部分是忽略了图像部分之间的空间关系。 换句话说,在保持计数恒定的同时在图像上加扰部分并不会改变模型决策。 对于像VGG或ResNets这样的当前计算机视觉模型是否同样如此? 不幸的是,由于重叠的感受野,通常不能直接以使特征直方图不变的方式对图像进行加扰。 对于VGG-16而言,接近该目标的算法是基于隐藏层激活的Gram特征的流行纹理合成算法(Gatys等,2015)图5。对于人类而言,加扰严重增加了难度。 VGG-16的性能受到的影响很小(干净率为90.1%,纹理化图像为79.4%)。

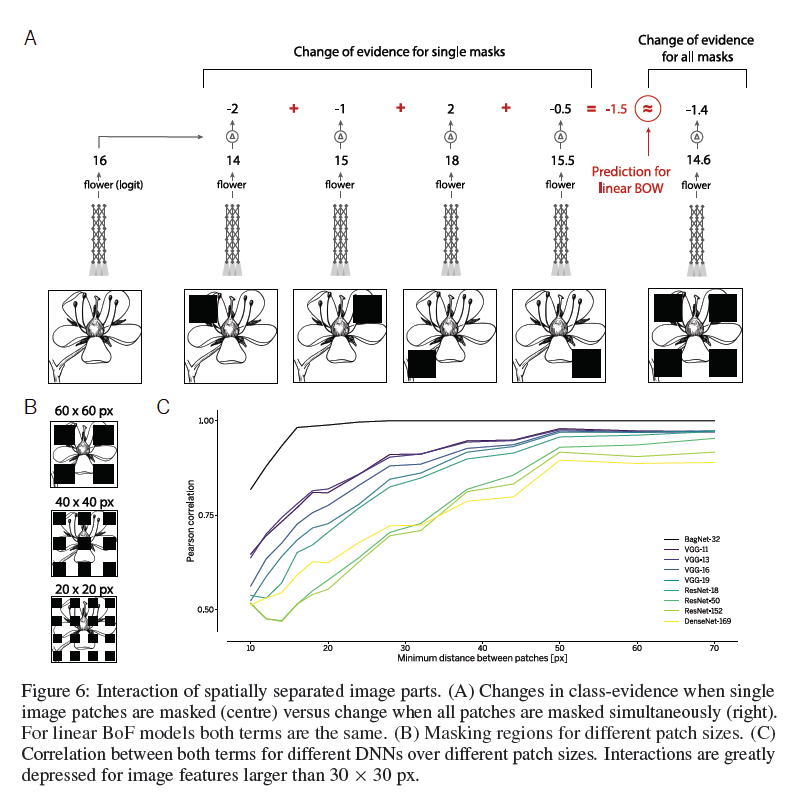
空间灵敏度 为了了解BagNets和DNN是否使用相似的图像部分进行图像分类,我们遵循Zintgraf等人的观点(2017)并测试当我们掩盖最具预测性的图像部分时DNN的预测是如何变化的。在图8(上图)中,我们比较了越来越多的8X8个patch的预测类概率的下降。掩蔽位置由BagNets的热图确定,我们将其与随机掩模以及几种流行的归因技术进行比较(Baehrens等,2010; Sundararajan等,2017; Kindermans等,2018; Shrikumar等, 2017)(我们使用DeepExplain(Ancona等,2017)的实现)直接在测试模型中计算热图。请注意,这些归因方法具有优势,因为它们可以计算关于模型的所有内容(白盒设置)来计算热图。尽管如此,BagNets的热图对类相关的图像部分更具预测性(另见表1)。换句话说,与BagNets相关的图像部分与普通DNN的分类类似。 VGG-16受局部patch掩蔽的影响最大,而更深和更高性能的架构对相对较小的掩模更加鲁棒,这再次表明更深层的架构考虑了更大的空间关系。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号