卡尔曼滤波的原理与思想
卡尔曼滤波是什么
卡尔曼滤波适用于估计一个动态系统的最优状态。即便是观测到的系统状态参数含有噪声,观测值不准确,卡尔曼滤波也能够完成对状态真实值的最优估计。网上大多数的教程讲到卡尔曼的数学公式推导,会让人很头疼,难以把握其中的主线和思想。所以我参考了国外一位学者的文章,讲述卡尔曼滤波的工作原理,然后编写了一个基于OpenCV的小程序给大家做一下说明。下面的这个视频请大家先直观地看看热闹吧~
卡尔曼滤波能做什么
假设我们手头有一辆DIY的移动小车。这辆车的外形是这样的:

这辆车可以在荒野移动,为了便于对它进行控制,需要知道它的位置以及移动速度。所以,建立一个向量,用来存储小车的位置和速度 :
其实,一个系统的状态有很多,选择最关心的状态来建立这个状态向量是很重要的。例如,状态还有水库里面水位的高低、炼钢厂高炉内的温度、平板电脑上面指尖触碰屏幕的位置等等这些需要持续跟踪的物理量。好了,回归到正题,小车上面安装了GPS传感器,这个传感器的精度是10米。但是如果小车行驶的荒野上面有河流和悬崖的话,10米的范围就太大,很容易掉进去进而无法继续工作。所以,单纯靠GPS的定位是无法满足需求的。另外,如果有人说小车本身接收操控着发送的运动指令,根据车轮所转动过的圈数时能够知道它走了多远,但是方向未知,并且在路上小车打滑车轮空转的现象绝对是不可避免。所以,GPS以及车轮上面电机的码盘等传感器是间接地为我们提供了小车的信息,这些信息包含了很多的和不确定性。如果将所有这些信息综合起来,是否能够通过计算得到我们更想要的准确信息呢?答案是可以的!我们不希望小车在荒野当中这样:

卡尔曼滤波的工作原理
卡尔曼滤波的工作原理主要包括先验估计和后验估计。什么意思,请看下文:
1.先验状态估计
为了简化我们的例子,假如小车在一条绝对笔直的线路上面行驶,其运动轨迹是确定的,不确定的是小车的速度大小和位置。于是,套路来了:
创建状态变量:
更直观地,下图表示的是一个状态空间,横坐标是速度,纵坐标是位置,平面上面的任意一个点就唯一地描述出这个小车的运动状态。
 卡尔曼滤波器发生作用的前提是小车的速度和位置量在其定义域内具有正态的高斯分布规律。用数学语言来讲,就是每一个变量都是具有一个平均值
卡尔曼滤波器发生作用的前提是小车的速度和位置量在其定义域内具有正态的高斯分布规律。用数学语言来讲,就是每一个变量都是具有一个平均值(这个值在变量的概率密度函数分布图的最中心位置,代表该数值是最可能发生的)和
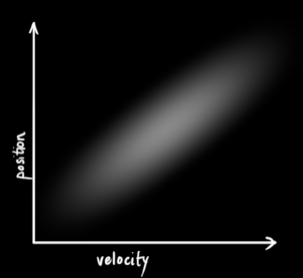
(这个数值代表方差,表示变量的不确定性程度)。那么,一谈到概率统计,我们马上可以想到:相互独立,或者互不相关。即已知其中一个变量的变换规律,我们无法推断出另外一个变量的变化规律。就像下图所示的这样(越亮的区域,表示发生的可能性越高):

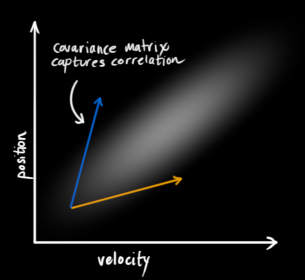
但是,相互独立的反面就是相关。下图所示的规律一看就明白,速度越大,位移也越大,这种情况下,两个变量相关(其实这种情况是很有可能发生的,因为速度越大的话,可能小车就远离我们,速度越小,表明靠近我们)。那么,通过协方差矩阵\Sigma 就能够将几个变量的相关程度描述清楚。矩阵当中的某一个元素 表示的是状态向量的第
个元素和第
个元素之间的相关程度,
。
 要注意的是协方差矩阵是一个对称阵。感兴趣的童鞋可以深入研究一下,协方差矩阵的特征值和特征向量所具有的几何意义:the directions in which the data varies the most.啥意思,就是哪个方向变化快,特征向量指哪儿。
要注意的是协方差矩阵是一个对称阵。感兴趣的童鞋可以深入研究一下,协方差矩阵的特征值和特征向量所具有的几何意义:the directions in which the data varies the most.啥意思,就是哪个方向变化快,特征向量指哪儿。
下面的两个链接供大家参考,有兴趣的要好好看看,知识点融会贯通了才觉得有意思!
下面是重头戏:数学描述部分:
定义: ,
,
是状态向量,
是协方差。
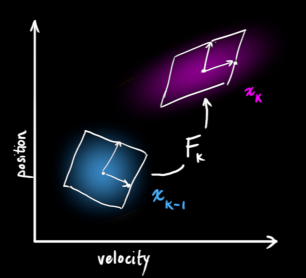
下图描述了一个k-1时刻和
时刻的状态:我们其实是完全有理由根据前一时刻的状态来预测下一时刻的状态,这就是状态更新方程。

于是,习惯性地要写成矩阵的形式:
(1)
状态向量的更新有了,但是还缺少状态向量之间相关性的更新,也就是协方差矩阵。
结合(1)得到:
(先验状态估计向量)
(先验状态估计协方差矩阵)
外部确定性影响
到目前为止,我们只是关心系统内部状态的更新,但是如果在外部对系统产生了确定影响,比如:小车的操控者发出一条刹车的指令,我们通过建模该指令,假如小车的加速度为,根据运动学的公式,得到:
写成矩阵的形式就是:
其中,
是控制矩阵,
是控制向量。由于本例子当中的控制实际上只包含了加速度,所以该向量包含元素的个数为1。
外部不确定性影响
现实世界往往是不那么好描述清楚的,就是存在不确定的外部影响,会对系统产生不确定的干扰。我们是无法对这些干扰进行准确的跟踪和量化的。所以,除了外界的确定项,还需要考虑不确定干扰项。
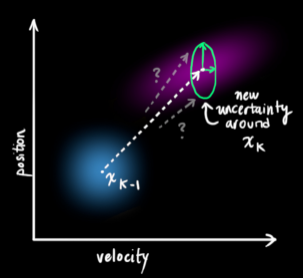
从而,得到最终先验估计的更新方程:
每一次的状态更新,就是在原来的最优估计的基础上面,下一次的状态落在一个新的高斯分布区域,从坐标系上面看就像是一团云状的集合,最优的估计就在这个云团当中的某一处。所以,我们首先要弄清楚这个云团具有什么样的性质,也就是使用过程激励噪声协方差来描述不确定干扰。注意,
。
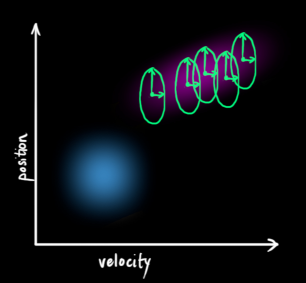
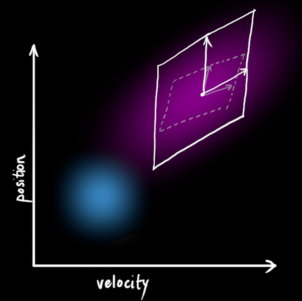
到此,先验估计的过程结束,总结一下,形成如下的公式:
(2)
(3)
重点来了:
先验估计取决于如下三部分:一部分是上一次的最优估计值(也就是上一轮卡尔曼滤波的结果),一部分是确定性的外界影响值,另一部分是环境当中不确定的干扰。先验估计协方差矩阵
,首先是依据第
次卡尔曼估计(后验估计)的协方差矩阵进行递推,再与外界在这次更新中可能对系统造成的不确定的影响求和得到。
2.后验估计(量测更新)
到此,利用和
能够对系统进行粗略的跟踪,但是还不完善,因为人们总是不能够完全信任自身的经验,也需要另外的一条途径来纠正潜在发生的错误或者是误差。所以,我们很自然的想到在车身安装各类的传感器,比如速度传感器、位移传感器等等,以这些传感器的反馈作为纠正我们推断的依据。下面看看传感器的量测更新是怎么样对最终的估计产生影响的。下图说明的是状态空间向观测空间的映射。
在这里需要说明一下,卡尔曼滤波器的观测系统的维数小于等于动态系统的维数,即观测量可以少于动态系统中状态向量所包含的元素个数。
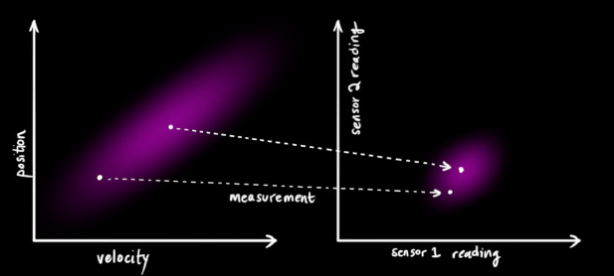
注意,传感器的输出值不一定就是我们创建的状态向量当中的元素,有时候需要进行一下简单的换算。即使是,有可能单位也不对应,所以,需要一个转换。这个转换就是矩阵,在一些文献当中也被称作状态空间到观测空间的映射矩阵。
 通过空间映射矩阵,依据我们先验估计值,在量测空间当中,传感器的测量值理想情况下应该是这样的:
通过空间映射矩阵,依据我们先验估计值,在量测空间当中,传感器的测量值理想情况下应该是这样的:
但是,传感器对系统某些状态的测量真的准确吗?是不是也会有偏差呢?答案是肯定的。系统在某一个状态下,会推断出一组理想值,在另一个状态下,会有另外一组理想值,而对应时刻传感器的测量值一定是无法和理想值保持完全吻合的。由于测量噪声的存在,不同的系统状态下,测量具有一定误差,呈现高斯分布,但是这个高斯分布的最中心还是当前的测量值。所以,还需要一个观测噪声向量以及观测噪声协方差来衡量测量水平,我们将它们分别命名为和
。下面的两张图说明这一点。
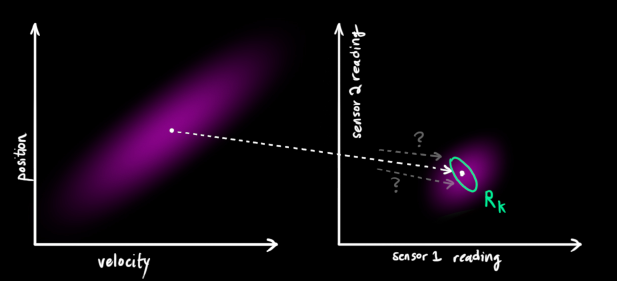
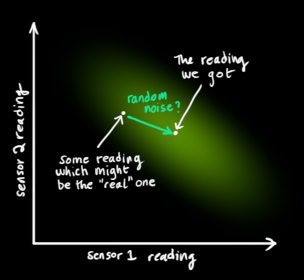
观测向量服从高斯分布,并且其平均值认为就是本次的量测值
。
下图看到的是两个云团,一个是状态预测值,另一个是观测值。那么到底哪一个具体的结果才是最好的呢?现在需要做的是对这两个结果进行合理的取舍(本质就是加权滤波),通过一种方法完成最终的卡尔曼预测。即:从图中粉红色云团和绿色云团当中找到一个最合适的点。
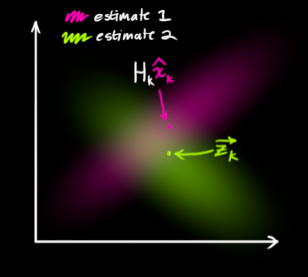
问题来了,怎么找?
首先来直观理解一下:考察观测向量和先验估计
:存在两个事件:事件1传感器的输出是对系统状态真实值的完美测量,丝毫不差;事件2先验状态估计的结果就是系统状态真实值的完美预测,也是丝毫不差。但是大家读到这里心里非常清楚的一点是:两个事件的发生都是概率性的,不能完全相信其中的任何一个!!!!!!!
如果我们具有两个事件,如果都发生的话,从直觉或者是理性思维上讲,是不是认定两个事件发生就找到了那个最理想的估计值?好了,抽象一下,得到:两个事件同时发生的可能性越大,我们越相信它!要想考察它们同时发生的可能性,就是将两个事件单独发生的概率相乘。
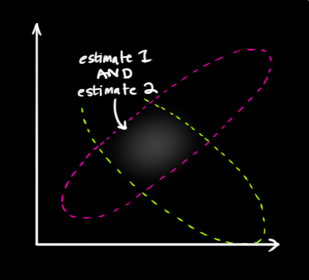 那么,下一步就是对两个云团进行重叠,找到重叠最亮的点(实际上我们能够把云团看做一帧图像,这帧图像上面的每一个像素具有一个灰度值,灰度值大小代表的是该事件发生在这个点的概率密度),最亮的点,从直觉上面讲,就是以上两种预测准确的最大化可能性。也就是得到了最终的结果。非常神奇的事情是,对两个高斯分布进行乘法运算,得到新的概率分布规律仍然符合高斯分布,然后就取下图当中蓝色曲线峰值对应的横坐标不就是结果了嘛。证明如下:
那么,下一步就是对两个云团进行重叠,找到重叠最亮的点(实际上我们能够把云团看做一帧图像,这帧图像上面的每一个像素具有一个灰度值,灰度值大小代表的是该事件发生在这个点的概率密度),最亮的点,从直觉上面讲,就是以上两种预测准确的最大化可能性。也就是得到了最终的结果。非常神奇的事情是,对两个高斯分布进行乘法运算,得到新的概率分布规律仍然符合高斯分布,然后就取下图当中蓝色曲线峰值对应的横坐标不就是结果了嘛。证明如下:
我们考察单随机变量的高斯分布,期望为,方差为
,概率密度函数为:
(4)
如果存在两个这样的高斯分布,只不过期望和方差不同,当两个分布相乘,得到什么结果?

是不是下式成立
(5)
将(4)代入(5),对照(4)的形式,求得:
其中,
以上是单变量概率密度函数的计算结果,如果是多变量的,那么,就变成了协方差矩阵的形式:
(6)
(7)
(8)
K称为卡尔曼增益,在下一步将会起到非常重要的作用。 好了,马上就要接近真相!
卡尔曼估计
下面就是对传感器的量测结果和根据时刻预测得到的结果进行融合。(由于刚才的推导是两个单变量,并且处在同一个空间内,下面的推导为了方便起见,我们将先验状态估计对应的结果映射到观测向量空间进行统一的运算)
第一个要解决的问题是:(7)和(8)两个式子中那个平均值和方差都对应多少?
(9)
(10)
将(9)和(10)代入(6)、(7)、(8)三个式子,整理得到:
其中卡尔曼增益为:
最后一步,更新结果:
其中,
就是第k次卡尔曼预测结果。
是该结果的协方差矩阵。它们都作为下一次先验估计的初始值参与到新的预测当中。总体上来讲,卡尔曼滤波的步骤大致分为两步,第一步是时间更新,也叫作先验估计,第二步是量测更新,也叫作后验估计,而当前的卡尔曼滤波过程的后验估计结果不仅可以作为本次的最终结果,还能够作为下一次的先验估计的初始值。下图是卡尔曼滤波的工作流程:

对卡尔曼滤波原理的理解,我参考了这篇文章,图片取自该文章,该文的图片和公式颜色区分是一大亮点,在此表示对作者的感谢。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号