在回归算法中我们通过SSE,MSE,RMSE,MAE,和R^2来评估我们归回结果的好坏,对于分类算法我也有相应的一系列指标来评估分类结果,这些评估分类结果的指标有:准确率(accuracy),精准率(precision),召回率(recall),精确率和召回率的调和平均值F1-measure。我们通过混淆矩阵来展现这些指标:
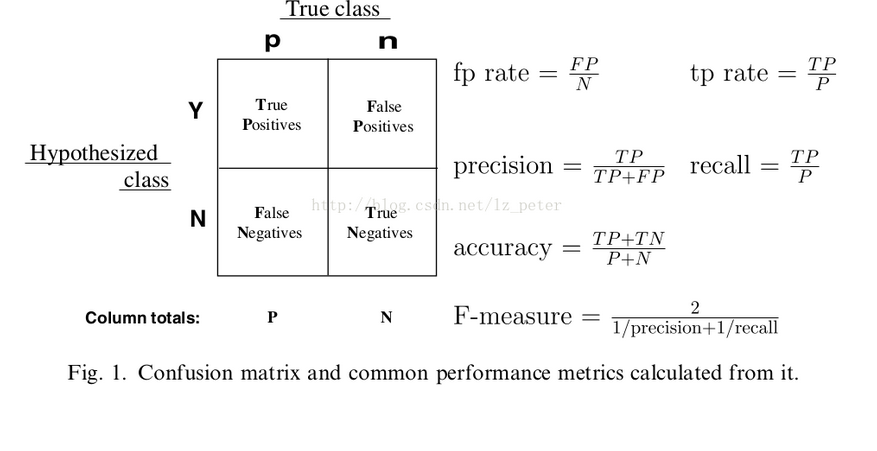
TP:实际为正,预测为正
FP:实际为负,预测为正
FN:实际为正,预测为负
TN:实际为负,预测为负
准确率(accuracy)=TP+TN/TP+FN+FP+TN
精准率(precision)=TP/TP+FP
召回率(recall)=TP/TP+FN
F1-measure=2*precision*recall/percision+recall
需要注意的是,我们经常用准确率来判别我们结果的,但是当我们的数据严重有偏时,使用准确率作为判别指标就显得不准确,比如:对10000人进行癌症预测,实际患癌的人数10人,未患癌的9990人。未患癌的概率99.9%,患癌的概率0.1%,本身未患癌的比例严重有偏,即随便来个人,我们不用任何机器学习算法就可以推断其未患癌的概率99.9%。这个时候我们用准确率来解释我们模型的好坏就显得没有意义。假设我们预测10个人患癌的人中,被我们真实预测出来8人,则我们的recall=8/10=80%,对比下召回率更能反应我们的模型的好坏。
精准率和召回率的区别主要是分母的区别,精准率对应预测结果中的正确预测为正例的样本中占我们预测为正理的比例,召回率是我们正确预测为正理的样本占实际正理的样本比例。
我们当然希望精准率和召回率都高,但是现实情况一般不是这样。这时我们可以通过F-measure来评估,F-measure是精准率和召回率的调和平均数的2倍。调和平均数的意义,是为了衡量A在空间B,C的总体平均分布程度(假设B,C不重叠)。F-measure应该是精准率和召回率之间的一个平衡点。如果多个模型结果进行对比的话,可能更加公平一些。
