二叉树(binary tree)
二叉树(binary tree)
二叉树(Binary Tree)是一种常见的树状数据结构,它由一组节点组成,每个节点最多有两个子节点,分别称为左子节点和右子节点。二叉树具有以下特点:
- 每个节点最多有两个子节点,分别称为左子节点和右子节点。
- 左子树和右子树也是二叉树,它们的结构与父节点类似。
- 二叉树的顺序不固定,可以是任意形状。
两种特殊形式
二叉树还有两种特殊形式,一个叫作满二叉树 ,另一个叫作完全二叉树
满二叉树
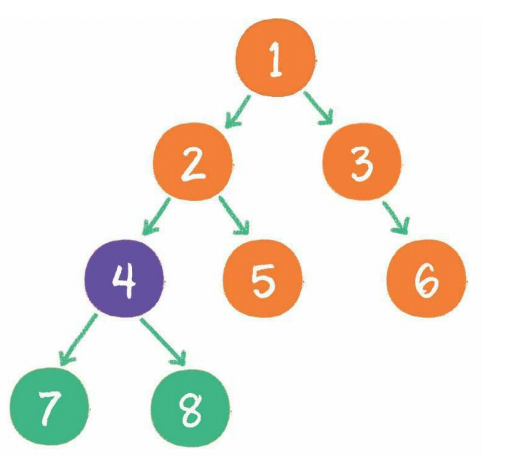
如果该二叉树的所有叶子节点都在最后一层,并且结点总数= 2^n -1,n 为层数,则我们称为满二又树。简单点说,满二叉树的每一个分支都是满的。
完全二叉树
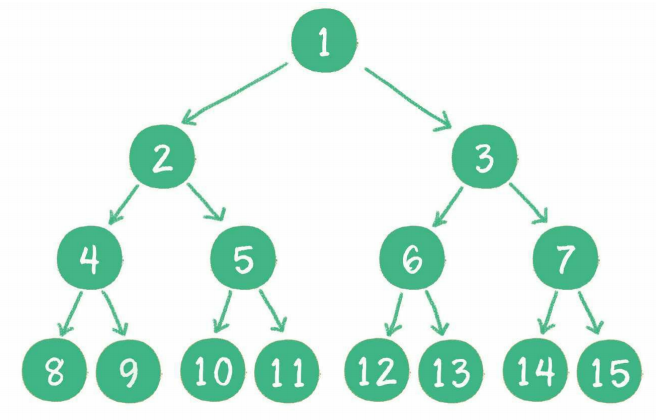
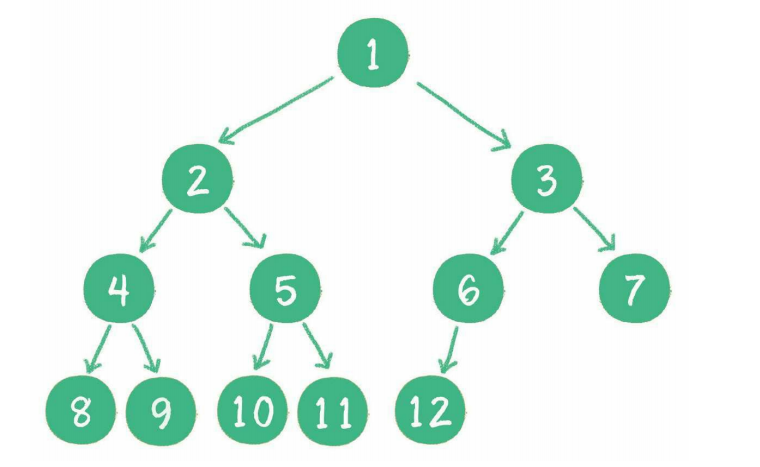
对一个有n个节点的二叉树,按层级顺序编号,则所有节点的编号为从1到n。如果这个树所有节点和同样深度的满二叉树的编号为从1到n的节点位置相同,则这个二叉树为完全二叉树。完全二叉树的条件没有满二叉树那么苛刻: 满二叉树要求所有分支都是满的;而完全二叉树只需保证最后一个节点之前的节点都齐全即可。
遍历二叉树
在计算机程序中,遍历本身是一个线性操作。所以遍历同样具有线性结构的数组或链表,是一件轻而易举的事情。反观二叉树,是典型的非线性数据结构,遍历时需要把非线性关联的点转化成一个线性的序列,以不同的方式来遍历,遍历出的序列顺序也不同。
遍历方式
深度优先和广度优先这两个概念不止局限于二叉树,它们更是一种抽象的算法思想,决定了访问某些复杂数据结构的顺序。在访问树、图,或其他一些复杂数据结构时,这两个概念常常被使用到。
1.深度优先遍历(Depth-First Search,DFS)
所谓深度优先,顾名思义,就是偏向于纵深,“一头扎到底”的访问方式。可能这种说法有些抽象,下面就通过二叉树的前序遍历、中序遍历、后序遍历 ,来看一看深度优先
2.广度优先遍历 (Breadth-First Search,BFS)
如果说深度优先遍历是在一个方向上“一头扎到底”,那么广度优先遍历则恰恰相反:先在各个方向上各走出1步,再在各个方向上走出第2步、第3步......一直到各个方向全部走完。听起来有些抽象,下面让我们通过二叉树的层序遍历
也是一种遍历或搜索树或图的算法。在广度优先遍历中,从根节点开始,按照层级顺序逐层访问节点,先访问当前层的所有节点,然后再访问下一层的节点。广度优先遍历可以使用队列来实现。
前序遍历
根节点 -> 左子树 -> 右子树。在前序遍历中,首先访问根节点,然后按照左子树和右子树的顺序递归地进行前序遍历。
// 前序遍历二叉树(根-左-右)
public static void preOrderTraversal(TreeNode node) {
if (node == null) {
return;
}
System.out.print(node.val + " ");
preOrderTraversal(node.left);
preOrderTraversal(node.right);
}
中序遍历
左子树 -> 根节点 -> 右子树。在中序遍历中,首先按照左子树的顺序递归地进行中序遍历,然后访问根节点,最后按照右子树的顺序递归地进行中序遍历。
// 中序遍历二叉树(左-根-右)
public static void inOrderTraversal(TreeNode node) {
if (node == null) {
return;
}
inOrderTraversal(node.left);
System.out.print(node.val + " ");
inOrderTraversal(node.right);
}
后序遍历
左子树 -> 右子树 -> 根节点。在后序遍历中,首先按照左子树和右子树的顺序递归地进行后序遍历,然后访问根节点。
// 后序遍历二叉树(左-右-根)
public static void postOrderTraversal(TreeNode node) {
if (node == null) {
return;
}
postOrderTraversal(node.left);
postOrderTraversal(node.right);
System.out.print(node.val + " ");
}
public static void main(String[] args) {
// 创建一个二叉树
TreeNode root = new TreeNode(1);
root.left = new TreeNode(2);
root.right = new TreeNode(3);
root.left.left = new TreeNode(4);
root.left.right = new TreeNode(5);
// 前序遍历二叉树
System.out.println("前序遍历结果:");
preOrderTraversal(root);
// 中序遍历二叉树
System.out.println("\n中序遍历结果:");
inOrderTraversal(root);
// 后序遍历二叉树
System.out.println("\n后序遍历结果:");
postOrderTraversal(root);
}
层次遍历
是一种广度优先遍历的应用,它按照层级顺序逐层访问二叉树的节点。在层次遍历中,从根节点开始,先访问根节点,然后按照从左到右的顺序逐层访问每个节点的子节点,一层一层横向遍历各个节点,可以借助于队列实现。
public static void levelOrderTraversal(TreeNode root) {
if (root == null) {
return;
}
Queue<TreeNode> queue = new LinkedList<>();
queue.offer(root); // 将根节点入队
while (!queue.isEmpty()) {
int levelSize = queue.size(); // 当前层级的节点数量
for (int i = 0; i < levelSize; i++) {
TreeNode node = queue.poll(); // 出队当前节点
System.out.print(node.val + " "); // 访问当前节点
if (node.left != null) {
queue.offer(node.left); // 左子节点入队
}
if (node.right != null) {
queue.offer(node.right); // 右子节点入队
}
}
System.out.println(); // 换行表示进入下一层级
}
}
存储结构
顺序结构存储
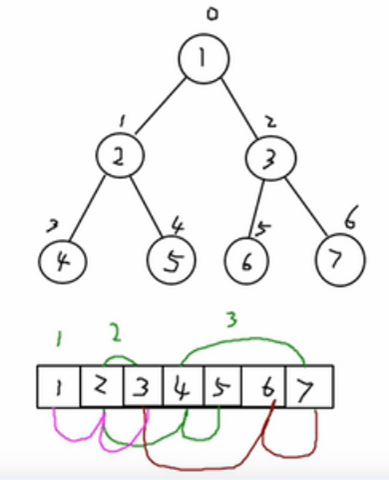
使用数组来表示二叉树的结构。按照层级顺序依次将二叉树节点存储到数组中,空缺位置用特定值(如null)表示。这种存储结构适用于完全二叉树,因为不是完全二叉树会有空间的浪费,可以通过数组下标计算节点之间的关系。
特点:
-
顺序二叉树通常只考虑完全二叉树
-
第n个元素的左子节点为
2* n +1 -
第n个元素的右子节点为
2* n + 2 -
第n个元素的父节点为
(n-1)/2
n: 表示二又树中的第几个元素(按0开始编号如图所示)
代码示例
public class ArrayBinaryTree {
private int[] treeArray;
private int size;
public ArrayBinaryTree(int capacity) {
treeArray = new int[capacity];
size = 0;
}
public void insert(int data) {
if (size >= treeArray.length) {
System.out.println("The tree is full");
return;
}
treeArray[size] = data;
size++;
}
public void inorderTraversal(int index) {
if (index >= size) {
return;
}
inorderTraversal(index * 2 + 1); // 访问左子树
System.out.print(treeArray[index] + " "); // 访问当前节点
inorderTraversal(index * 2 + 2); // 访问右子树
}
public static void main(String[] args) {
ArrayBinaryTree tree = new ArrayBinaryTree(10);
tree.insert(1);
tree.insert(2);
tree.insert(3);
tree.insert(4);
tree.insert(5);
System.out.print("Inorder Traversal: ");
tree.inorderTraversal(0); // 输出: 4 2 5 1 3
}
}
链式存储
用节点对象和指针来表示二叉树的结构。每个节点包含一个数据元素和左右子节点的指针。用链表来表示一棵二叉树,即用链来指示元素的逻辑关系。 通常的方法是链表中每个结点由三个域组成,数据域和左右指针域,左右指针分别用来给出该结点左孩子和右孩子所在的链结点的存储地址 。这种存储结构可以灵活地表示任意形状的二叉树。

class TreeNode {
int val;
TreeNode left;
TreeNode right;
public TreeNode(int val) {
this.val = val;
this.left = null;
this.right = null;
}
}
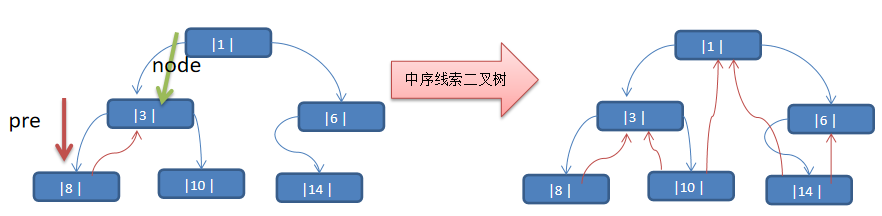
线索化二叉树
线索二叉树是对普通二叉树的一种扩展,它通过在空指针位置存储指向当前节点的前驱节点和后继节点的指针,使得二叉树的遍历更加方便。可以有效地减少遍历的次数,同时也可以避免空指针的浪费。
-
n个结点的二又链表中含有
n+1[公式2n-(n-1)=n+1] 个空指针域。利用二又链表中的空指针域,存放指向该结点在某种遍历次序下的前驱和后继结点的指针(这种附加的指针称为"线索") -
这种加上了线索的二叉链表称为线索链表,相应的二叉树称为线索二叉树(Threaded BinaryTree)。根据线索性质的不同,线索二叉树可分为前序线索叉树、中序线索二叉树和后序线索二叉树三种
-
一个结点的前一个结点,称为前驱结点,一个结点的后一个结点,称为后继结点
代码实现
class TreeNode {
int val;
TreeNode left;
TreeNode right;
private int leftType; // 0:左子树 1:前驱节点
private int rightType; // 0:右子树 1:后继节点
public TreeNode(int val) {
this.val = val;
this.left = null;
this.right = null;
}
// 省略get set方法
}
class ThreadedBinaryTree {
private TreeNode root;
//为了实现线索化,需要创建要给指向当前结点的前驱结点的指针
//在递归进行线索化时,pre 总是保留前一个结点
private TreeNode pre = null;
public void setRoot(TreeNode root) {
this.root = root;
}
public void threadedNodes(){
this.threadedNodes(root);
}
// 线索化节点 中序线索化
public void threadedNodes(TreeNode node){
if (node == null){
return;
}
// 先线索化左子树
threadedNodes(node.getLeft());
// 线索化当前节点
if (node.getLeft() == null){
//让当前结点的左指针指向前驱结点
node.setLeft(pre);
node.setLeftType(1);
}
//处理后继结点
if (pre != null && pre.getRight() == null) {
//让前驱结点的右指针指向当前结点
pre.setRight(node);
//修改前驱结点的右指针类型
pre.setRightType(1);
}
// 让当前结点是下一个结点的前驱结点
pre = node;
pre = node;
// 线索化右子树
threadedNodes(node.getRight());
}
}
遍历线索化二叉树
因为线索化后,各个结点指向有变化,因此原来的遍历方式不能使用,这时需要使用新的方式遍历线索化二叉树,各个节点可以通过线型方式遍历,因此无需使用递归方式,这样也提高了遍历的效率。 遍历的次序应当和中序遍历保持一致。
代码实现
// 遍历线索化二叉树
public void threadedNodeList(){
//定义一个变量,存储当前遍历的结点,从root开始
TreeNode node = root;
while (node != null){
while (node.getLeftType() == 0){
node = node.getLeft();
}
System.out.println(node);
while (node.getRightType() == 1){
node = node.getRight();
System.out.println(node);
}
node = node.getRight();
}
}
以上面图中的例子,进行代码测试
public class ThreadedBinaryTreeDemo {
public static void main(String[] args) {
TreeNode root = new TreeNode(1);
TreeNode node2 = new TreeNode(3);
TreeNode node3 = new TreeNode(6);
TreeNode node4 = new TreeNode(8);
TreeNode node5 = new TreeNode(10);
TreeNode node6 = new TreeNode(14);
root.setLeft(node2);
root.setRight(node3);
node2.setLeft(node4);
node2.setRight(node5);
node3.setLeft(node6);
//测试中序线索化
ThreadedBinaryTree threadedBinaryTree = new ThreadedBinaryTree();
threadedBinaryTree.setRoot(root);
threadedBinaryTree.threadedNodes();
//测试: 以10号节点测试
TreeNode leftNode = node5.getLeft();
TreeNode rightNode = node5.getRight();
System.out.println("10号结点的前驱结点是 =" + leftNode); //3
System.out.println("10号结点的后继结点是=" + rightNode); //1
// 测试遍历
System.out.println("使用线索化的方式遍历 线索化二叉树");
threadedBinaryTree.threadedNodeList(); // 8, 3, 10, 1, 14, 6
}
}


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY