
Semi-Supervised 3D Object Detection via Adaptive Pseudo-Labeling笔记【2021 ICIP】
- 点云初学者,有理解错误的欢迎提出
- **不喜勿喷( ̄y▽, ̄)╭ ( ̄y▽, ̄)╭ **
简述
问题:获得数量巨多的高质量含groud truth的点云数据的成本是高昂的;特别是由于户外场景中点云的稀疏性和城市场景的复杂性导致对户外场景的点云进行标签标注的成本高于室内场景。
目的:设计一种基于伪标签的半监督学习方法来解决户外场景中3d目标检测任务。
实验所采用的数据集:
KITTI基本流程:
- 训练detector
- 根据训练好的detector更新伪标签
- 执行一次1和2称一次迭代,迭代T次。
创新点:
- 设计了Adaptive Class Confidence Selection module(ACCS) 来生成高质量的伪标签。
- 设计了Holistic Point Cloud Augmentation (HPCA)来提高整个模型的鲁棒性。
个人看法:看完似乎这两个创新点有点不是很牛,而且最后的实验比较有点讨巧?别人一般以全监督作为baseline,他是用半监督作为baseline。不过这里面介绍的数据增强方法可以嫖。
OverView
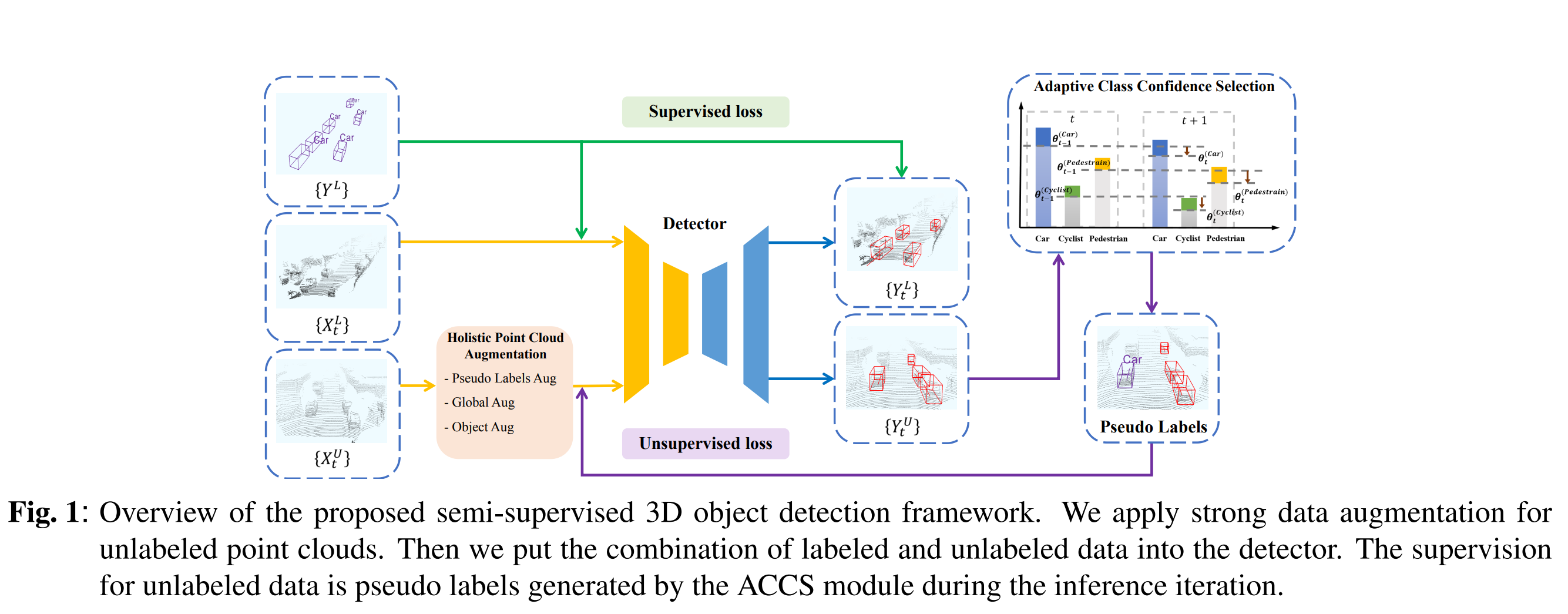
整个算法流程:

符号解释:
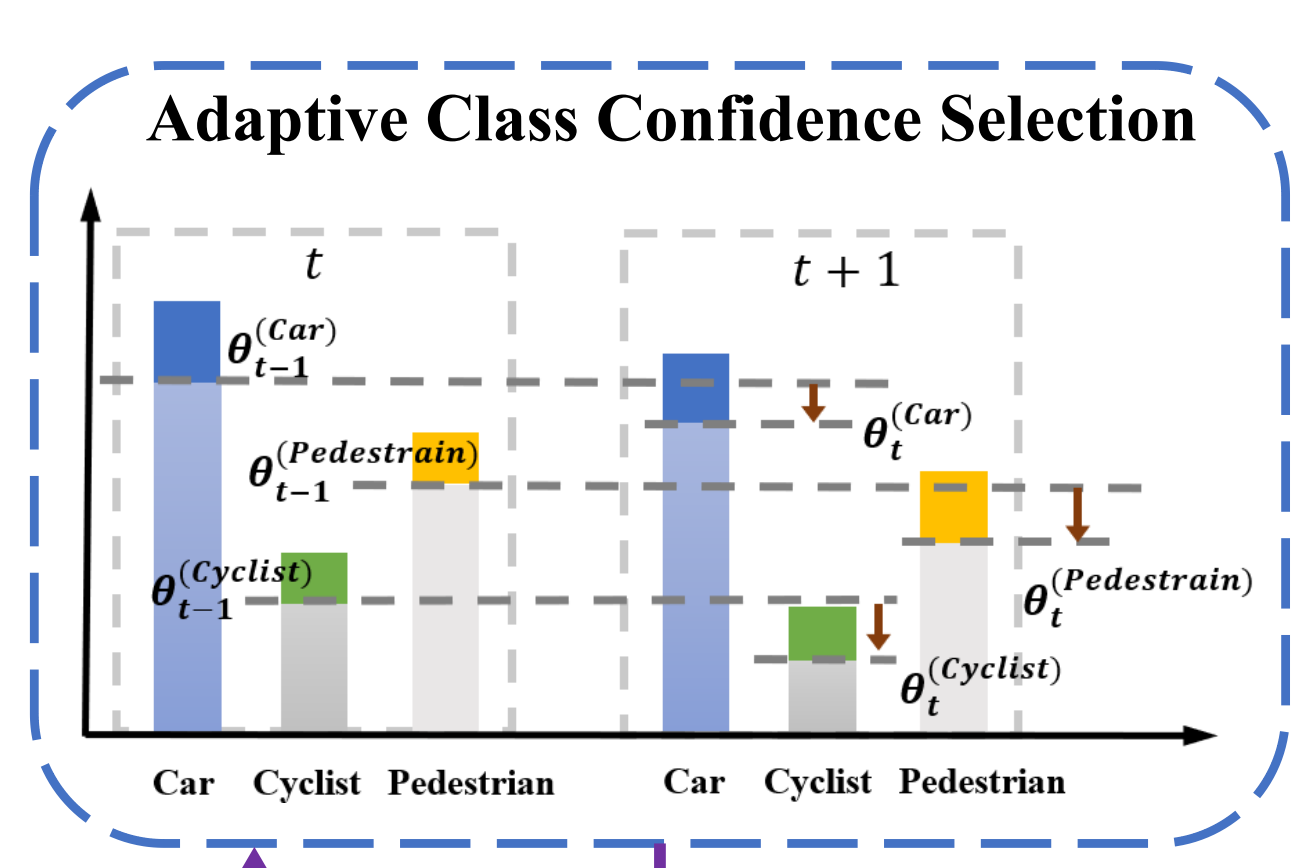
Adaptive Class Confidence Selection(ACCS)
设计该模块原因:
为了能够生成高质量的伪标签我们可以在每个iteration中选择具有高置信度的unlabelled data来更新其标签。如果我们给每个类设置了相同的阈值,由于类间的不平衡问题可能会导致每次更新伪标签时被选中的大部分属于A类(GT中属于A类的点有占大头)【个人理解】。ACCS保证了不同的类有不同的阈值。
基本思路:
刚开始给每个类设置一个相同参数c,将\(\mathcal{P}^U\)送入目标检测网络获得\(x_i^U\)对应的标签,最终得到\(\mathcal{P}^U\)对应的网络预测标签\(Y^U\)。现在每个物体都有对应的网络预测标签及该标签对应的概率值。对这些概率值按不同类别分别排序,预测的概率值在所在类别的前百分之c的就可以加入labelled data作为下一次迭代的训练数据,每一次迭代c就加一点。
目标检测网络的损失函数见论文,由于论文采用的是其他论文里面的介绍的损失函数,这里就不过多解释(真实原因就是我还没看原论文介绍),想要理解的看原论文。
Holitic Point Cloud Augumentation
目的:通过添加扰动和噪声到unlabelled data来提高模型的泛化能力。
- Pseudo Labels Augumentation
类似下采样?【不太理解】
- Global Augumentation
对整个点云进行随机缩放,沿z轴进行随机选择和沿x轴随机水平翻转。
- Object Augumetation
对每个检测框里面的点添加随机噪声:旋转和线性平移。
实验
以PointRCNN为Detector。Ratios指的是初始有标签数据的占比。
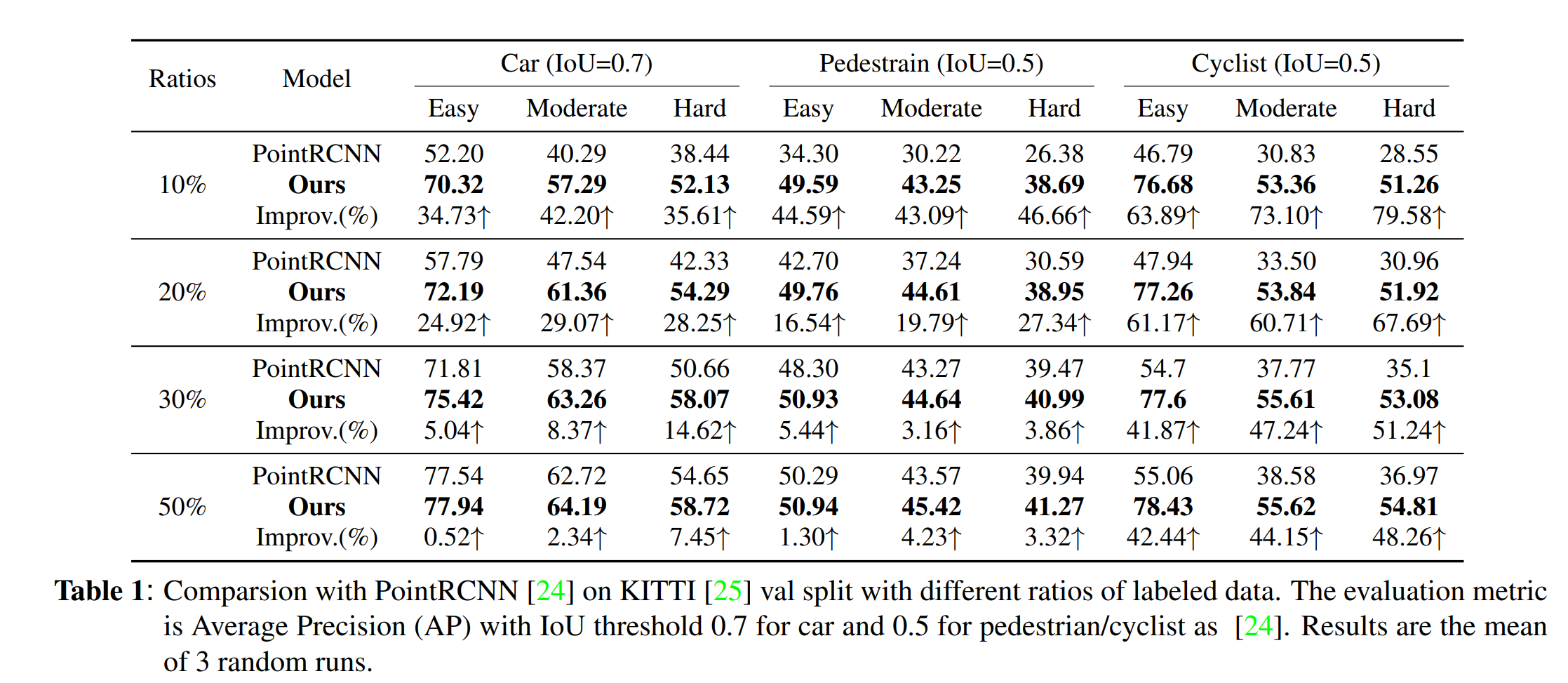
图中PointRCNN那一行的性能是指:只在初始\(X^L\)的训练下得到的性能【讨巧的比较手法?】。

