SegGroup: Seg-Level Supervision for 3D Instance and Semantic Segmentation笔记
点云初学者,有理解错误的欢迎提出。
简述
问题:对原始点云进行全标注的成本过于高昂。
目的:设计一种方法能够在点云上对无标签的点进行自动标注【即:伪标签】。
基本流程:
使用一个 normal-based graph cut 方法对ScanNet数据集进行mesh的过分割(over-segmentation);相较于2d图像面临遮挡和亮度变化的影响,点云数据中不同物体之间有着明显的边界,此特性非常有益于过分割;最后每一个instance可能会被分割成多个segment。(文中指出:虽然有些属于不同instance的部分会被错误合并到一个segment,但是影响不大)
进行seg-level标签标注。
在每个instance上选一个点进行标注。有两种情况:
- 同一个instance被分割成若干个相连的segment
- 同一个instance被分割成多干个不相连的segment
标注策略:情况1,选出最具代表性的segment标注(最大块或最中心),情况2:对每个相连的segments,选一个最具代表性的segment标注。
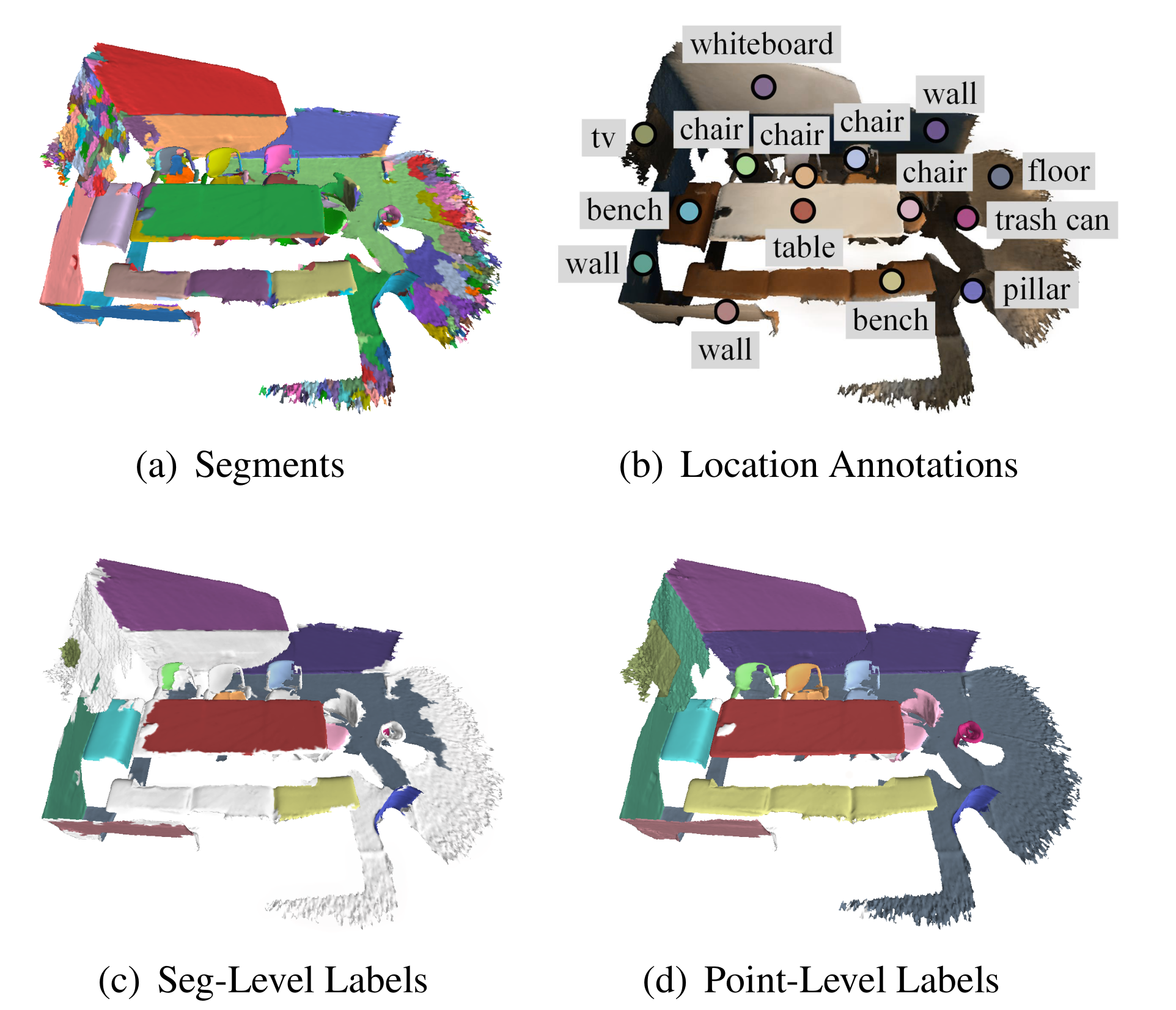
最后平均每个场景仅需要1.93分钟的时间进行seg-level标签标注,归功于过分割仅需对场景0.03%的点进行人工标注就可得到大约29.42%的标签。
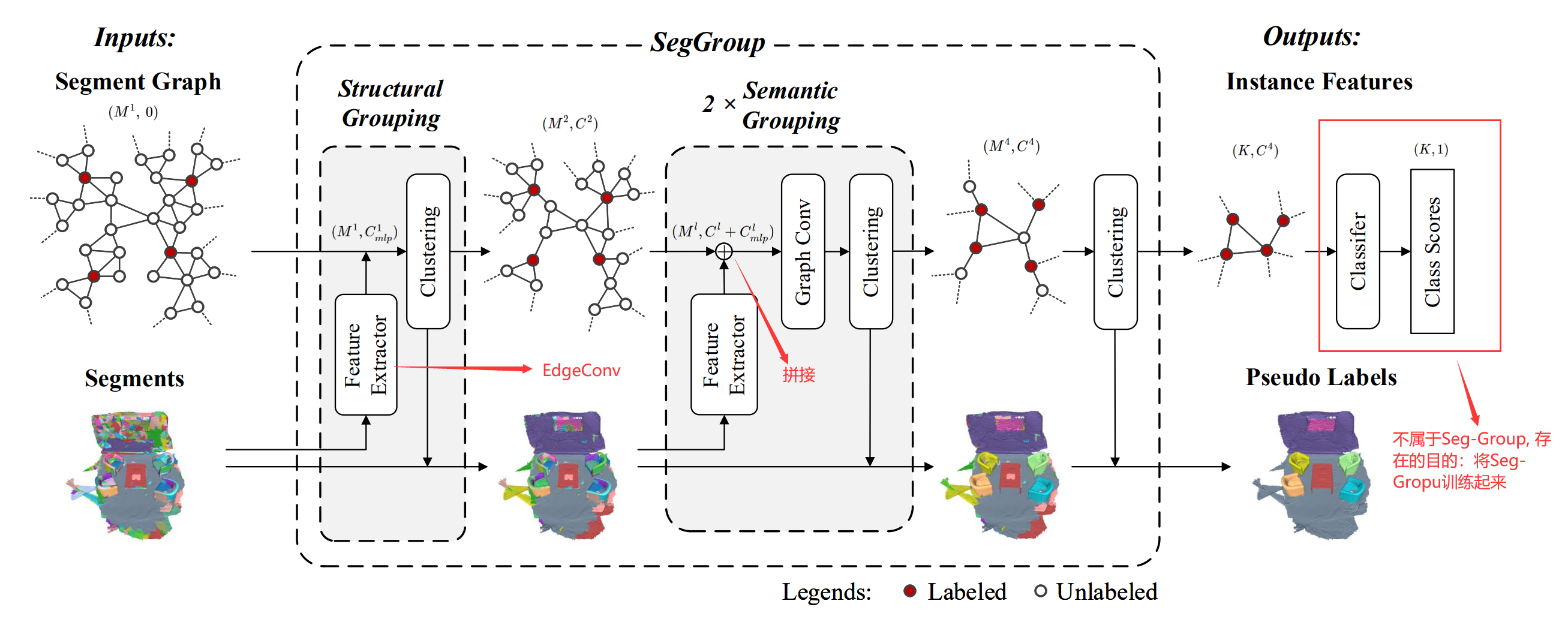
将带有初始标签的训练数据送入Seg-Group网络生成伪标签。
将含有伪标签的训练数据输入一个point-level的网络(别人的)进行语义分割,最后在此网络的实验结果上进行性能评价。
核心:the location of instance 对于3d场景的语义分割任务具有重要价值。
SegGroup
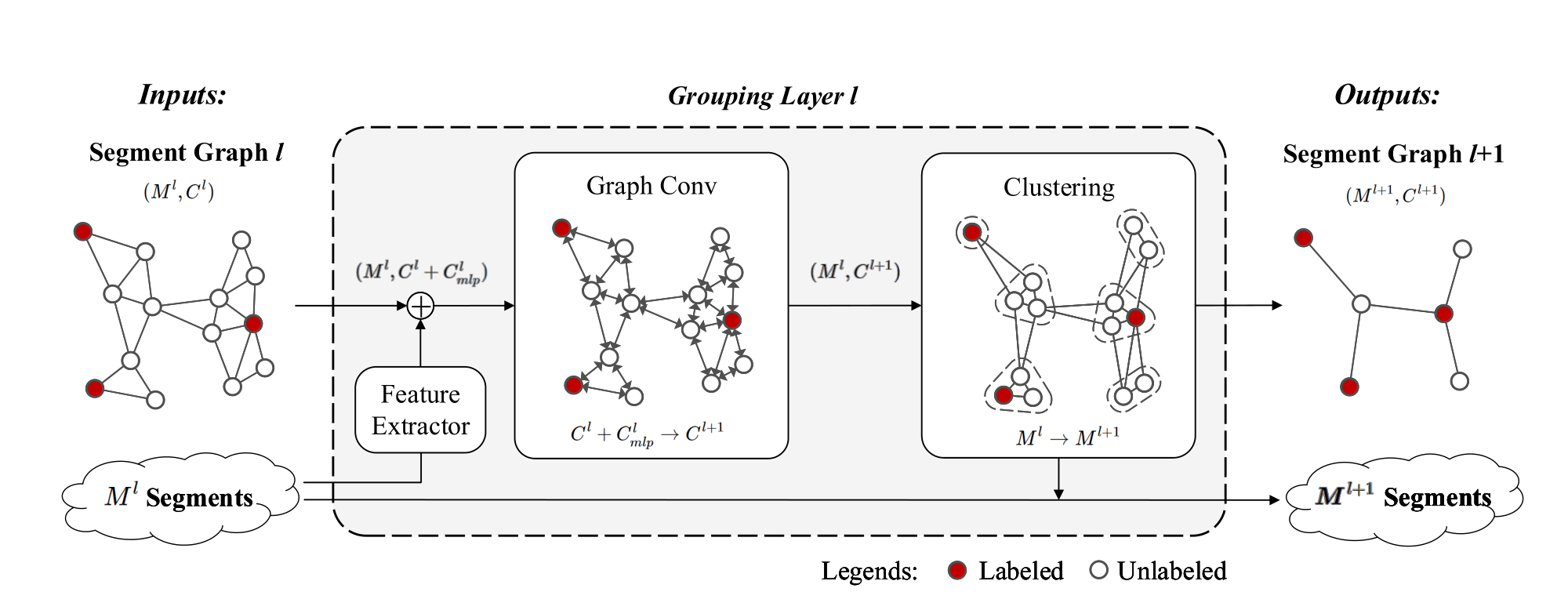
\[\large \begin{eqnarray} M^l&&:&&第l层的输入节点数(即:segment数)\\ C^l&&:&&第l层的节点的输入特征维度\\ M^{l+1}&&:&&第l层的输出节点数(M^{l+1}\le M^l)\\ C^{l+l}&&:&&第l层节点的输出特征维度\\ \vec{h}^l_i&&:&&第l层节点i的特征向量\\ e^l_{ij}&&:&&第l层节点i和j之间的相似度系数(i和j在图中是相连的)\\ a^l_{ij}&&:&&可以看成是边的权重\\ \mathcal{N}^l_i&&:&&第l层节点i的一阶邻域内的节点\\ C^l_{mlp}&&:&&Feature \ Extractor提取的特征维度 \end{eqnarray} \]初始要构建一个图(Graph),假设:a single instance 的所有 segment 是相连的。
以每个 segment 为图中节点,如果在过分割结果中两个segment是毗邻的的,则在Graph中二者之间存在一条边,边的权重\(a^l_{ij}\)由以下公式计算:
\[\large \begin{eqnarray} e^l_{ij}=&&exp(-\lambda||\vec{h}^l_i-\vec{h}^l_j||_2)\\ &&\lambda>0,如果节点i和j得相似度越高则e_{ij}越大\\ 归一化得:&&\\ a^l_{ij}=&&\frac{e^l_{ij}}{e^l_{ii}+\sum_{k\in \mathcal{N}^l_i}e^l_{ik}} \end{eqnarray} \]整个Seg-Group网络可以分为三个组件:一个 Structural Grouping 和两个 Semantic Grouping。Structural Grouping和Semantic Grouping相比后者多了一个Graph Conv,故介绍Semantic Grouping即可,基本流程图如下:
- Feature Extractor
采用EdgeConv来获得每个segment的特征,每个Feature Extractor的输出维度是64维。Structural Grouping里面的Feature Extractor有点不同,首先对每个segment进行FPS采样得到64个点,再对这64个点归一化至一个球体,每个点的特征是xyz+RGB,输入网络然后每个segment进行最大池和平均池,二者拼接得到一个128维的特征向量【存疑,后面两个Grouping Layer的Feature Extractor是怎么实现的】
- Graph Conv
目的:在语义上缩小属于同一实例的节点之间的差异,扩大属于不同实例的节点之间的差异
本质上就是GCN,只是公式的表述形式不同
- Clustering
一共有四个Clustering操作,看SegGroup网络图就可以看出。前三个Clustering的目的和采用的算法是一样的,设置一个阈值,如果这一个有标签的segment和一个没有标签的segment在Graph中是相连的且二者特征向量的欧氏距离小于设定的阈值;则把没有标签的segment与有标签的segment合并。最后一个Clustering不设置阈值,对每个没有标签的segment计算它与一阶邻居segment的欧式距离,选出值最小的那个labelled segment的标签赋予其自身。
网络如何训练(存疑)
SegGroup网络图里面的K应该等于初始有标记的segment数,不过最后为何是(K,1)而不是(K,类别数)看不懂。
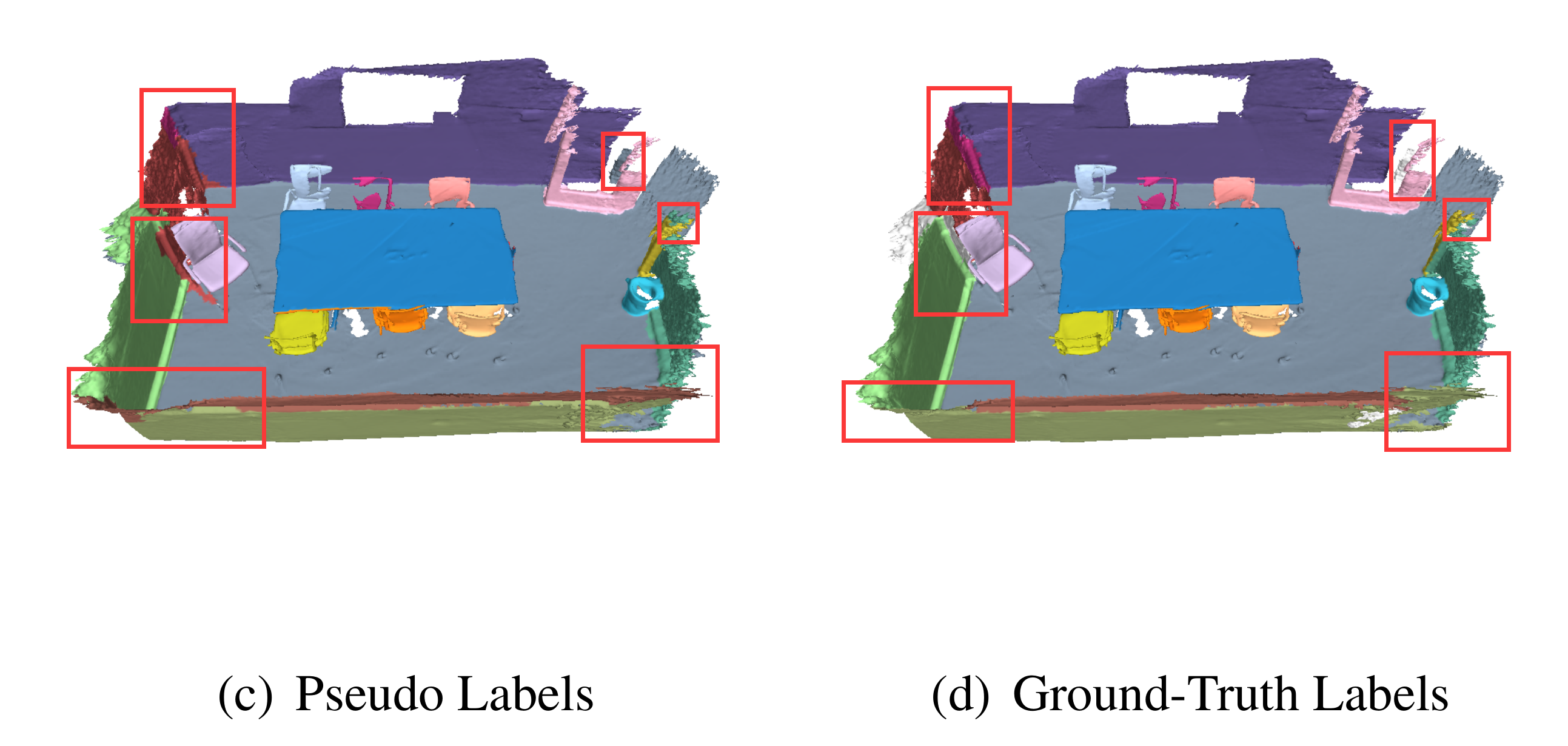
训练完SegGroup就得到训练数据的伪标签。可视化结果如下。
补充
弱监督
简介: