
【python】 爬虫-爬取新闻
最近,在数据挖掘课,要交课设了,打算做一个通过机器学习进行新闻分类,首先要有大量的文本(新闻),去做训练,并通过爬虫爬取大量的新闻
一,思路如下:
0.首先确定获取数据的网站
1.通过BeautifulSoup来切取链接
2. 然后使用python的第三方框架newspaper3k,直接通过给指定的链接,然后返回新闻文本(当然也可通过BeautifulSoup切出文本)
二,过程如下:
1.选定网址 新浪新闻 https://news.sina.com.cn/roll/#pageid=153&lid=2509&k=&num=50&page=1

页面如上
2.查看更多新闻可以使用拼接url 也可以模拟点击,我这里用的模拟点击
使用python 框架 selenium 来进行模拟点击
selenium 是一套完整的web应用程序测试系统,用它来进行模拟点击,需要配合Google Chrome或着火狐 浏览器使用,配合不同的驱动
定位点击按钮时,不同的元素
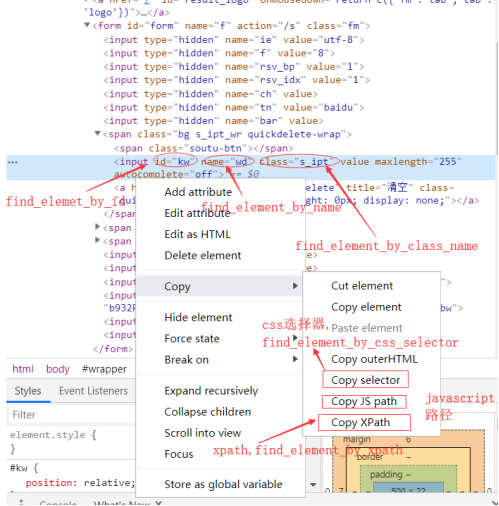
对于新浪网来说如下:

这个点击定位是找到页面中所有对应的id,自上向下,第一个是我们想要的
browser.find_elements_by_class_name("pagebox_pre")[1]
然后每次点击,得到下一页,获取整个界面,切除url,重复
3.利用BeautifulSoup切出新闻的url
def geturl(html): #获取所有新闻链接
sleep(2)
soup = BeautifulSoup(html , "html.parser")
bd = soup.find(attrs = {"class" : "d_list_txt"})
b1 = bd.findAll(attrs = {"class" : "c_tit"})
for u in b1:
urlList.append(u.findAll('a')[0].get("href")) #获取所有新闻链接
4.使用python的第三方框架newspaper3k,直接通过给指定的链接,然后返回新闻文本
def captive( url ): #获取新闻内容
news = Article( url , language='zh')
sleep(1)
news .download() #下载
news .parse() #解析
newsList.append(news.text) #新闻正文
三,具体代码如下
#! /usr/bin/env python
#coding=utf-8
import io
import sys
from tqdm import tqdm
sys.stdout = io.TextIOWrapper(sys.stdout.buffer,encoding='gb18030')
from selenium import webdriver
from time import sleep
import requests
from bs4 import BeautifulSoup
from newspaper import Article
from selenium.webdriver.common.action_chains import ActionChains
'''
8 军事 https://news.sina.com.cn/roll/#pageid=153&lid=2514&k=&num=50&page=2
6 娱乐 https://news.sina.com.cn/roll/#pageid=153&lid=2513&k=&num=50&page=2
5 体育 https://news.sina.com.cn/roll/#pageid=153&lid=2512&k=&num=50&page=2
2 科技 https://news.sina.com.cn/roll/#pageid=153&lid=2515&k=&num=50&page=2
1 财经 https://news.sina.com.cn/roll/#pageid=153&lid=2516&k=&num=50&page=2
7 国际 https://news.sina.com.cn/roll/#pageid=153&lid=2968&k=&num=50&page=2
'''
url = "https://news.sina.com.cn/roll/#pageid=153&lid=2515&k=&num=50&page=26"
urlList = [] #url 列表
newsList = [] #newsn内容列表
def captive( url ): #获取新闻内容
news = Article( url , language='zh')
sleep(1)
news .download() #下载
news .parse() #解析
newsList.append(news.text) #新闻正文
def gethtml( url , n ): #新闻的url 及获取的次数1次点击50条
browser.get(url)
for i in range(0,n):
sleep(2)
label_bel = browser.find_elements_by_class_name("pagebox_pre")[1] #定位点击键
html = browser.page_source # 获取网页
geturl(html)
label_bel.click() # 进行点击加载更多
sleep(2)
currentPageUrl = browser.current_url
browser.get(browser.current_url)
def geturl(html): #获取所有新闻链接
sleep(2)
soup = BeautifulSoup(html , "html.parser")
bd = soup.find(attrs = {"class" : "d_list_txt"})
b1 = bd.findAll(attrs = {"class" : "c_tit"})
for u in b1:
urlList.append(u.findAll('a')[0].get("href")) #获取所有新闻链接
browser = webdriver.Chrome() # 加载浏览器
gethtml( url , 20 )
#for url1 in urlList: #测试链接
# print(url1)
print(len(urlList))
for newsurl in tqdm(urlList):
try:
captive( newsurl )
except:
pass
continue
sleep(0.1)
for i in tqdm(range(len(newsList))): #存入文件
try:
f = open(r"datass\2_" + str(1000 + i) + ".txt",'a',encoding="utf-8")
f.write(newsList[i])
f.close()
except:
pass
continue
sleep(0.1)
print("结束")
#print(newsList[0])
#f=open('./1.html',mode="w",encoding="utf-8") #这三行为测试使用
#f.write(html)
四,项目配置
以大部分为python的模块,都可以pip安装,简单介绍:
1 . 预防万一,为了全程的一遍通过,首先更新下pip
python -m pip install --upgrade pip
pip使用总结 https://www.cnblogs.com/xueweihan/p/4981704.html
2. 安装newspaper (强大的获取网页新闻框架)
pip install newspaper3k
使用教程:https://github.com/codelucas/newspaper
3.安装Beautifulsoup
pip install beautifulsoup4
使用教程 :https://www.cnblogs.com/TryFirst/p/9305001.html
4.安装selenium (selenium 是一套完整的web应用程序测试系统,用它来进行模拟点击,需要配合浏览器使用)
pip install selenium
4.1 与之对应的配置
这里用到的是Google Chrome浏览器
下载浏览器对应的驱动 http://chromedriver.storage.googleapis.com/index.html
查看浏览器版本号
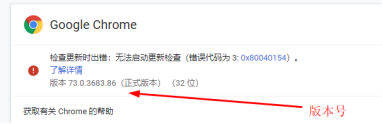
然后将驱动安装到python的目录

使用教程:https://www.cnblogs.com/TryFirst/p/9305001.html
以上全部配置步骤完成
推荐一个网站:https://hellogithub.com 里面有许多有意思的项目值得去学习,研究

