
Hive(8)-常用查询函数
一. 空字段赋值
1. 函数说明
NVL:给值为NULL的数据赋值,它的格式是NVL( value,default_value)。它的功能是如果value为NULL,则NVL函数返回default_value的值,否则返回value的值,如果两个参数都为NULL ,则返回NULL。
2. 案例
-- 如果员工的comm为NULL,则用-1代替 select comm,nvl(comm, -1) from emp;
-- 如果员工的comm为NULL,则用领导id代替 select comm, nvl(comm,mgr) from emp;
二. case when
1. 函数说明

2. 案例

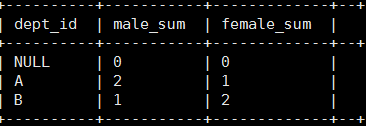
-- 求出不同部门男女各多少人 select dept_id, sum(case sex when '男' then 1 else 0 end) male_sum, sum(case sex when '女' then 1 else 0 end) female_sum from emp_sex group by dept_id;
三. 行转列(concat)
1. 函数说明
CONCAT(string A/col, string B/col…):返回输入字符串连接后的结果,支持任意个输入字符串;
CONCAT_WS(separator, str1, str2,...):它是一个特殊形式的 CONCAT()。第一个参数是剩余参数间的分隔符。分隔符可以是与剩余参数一样的字符串。如果分隔符是 NULL,返回值也将为 NULL。这个函数会跳过分隔符参数后的任何 NULL 和空字符串。分隔符将被加到被连接的字符串之间;
COLLECT_SET(col):函数只接受基本数据类型,它的主要作用是将某字段的值进行去重汇总,产生array类型字段。
2.案例

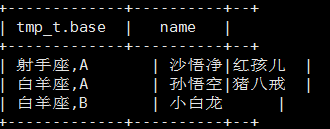
将血型和星座一样的归类到一起
select tmp_t.base, concat_ws("|",collect_set(tmp_t.name)) name from( select concat(constellation,",",blood_type) base, name from person_info ) tmp_t group by tmp_t.base;
四. 列转行(explode)
1.函数说明

EXPLODE(col):将hive一列中复杂的array或者map结构拆分成多行。
LATERAL VIEW :
用法:LATERAL VIEW udtf(expression) tableAlias AS columnAlias
解释:用于和split, explode等UDTF一起使用,它能够将一列数据拆成多行数据,在此基础上可以对拆分后的数据进行聚合。
2.案例
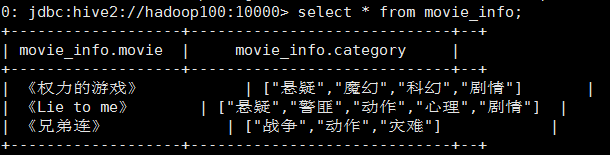
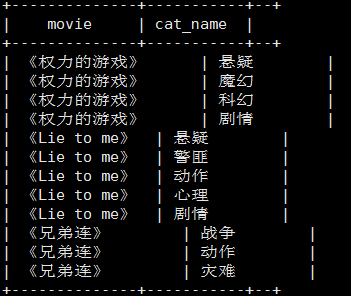
将电影分类中的数组数据展开
select movie, cat_name from movie_info lateral view explode(category) exp_tbl as cat_name;
五. 窗口函数(开窗函数)
1. 语法
UDAF() over (PARTITION By col1,col2 order by col3 窗口子句(rows between .. and ..)) AS 列别名
注意:PARTITION By后可跟多个字段,order By只跟一个字段。
2. 函数说明
over()决定了聚合函数的聚合范围,默认对整个窗口中的数据进行聚合,聚合函数对每一条数据调用一次。
partition by子句:使用Partiton by子句对数据进行分区,可以用paritition by对区内的进行聚合。
order by子句作用:对分区中的数据进行排序;确定聚合哪些行(默认从起点到当前行的聚合)
窗口子句
CURRENT ROW:当前行
n PRECEDING:往前n行数据
n FOLLOWING:往后n行数据
UNBOUNDED:起点,UNBOUNDED PRECEDING 表示从前面的起点, UNBOUNDED FOLLOWING表示到后面的终点
LAG(col,n,default_val):往前第n行数据
LEAD(col,n, default_val):往后第n行数据
NTILE(n):把有序分区中的行分发到指定数据的组中,各个组有编号,编号从1开始,对于每一行,NTILE返回此行所属的组的编号。注意:n必须为int类型。
tips:
通过使用partition by子句将数据进行了分区。如果想要对窗口进行更细的动态划分,就要引入窗口子句。
order by必须跟在partition by后;Rows必须跟在Order by子;(partition by .. order by)可替换为(distribute by .. sort by ..)
什么时候用开窗函数?
开窗函数常结合聚合函数使用,一般来讲聚合后的行数要少于聚合前的行数,但是有时我们既想显示聚集前的数据,
又要显示聚集后的数据,这时我们便引入了窗口函数.
3.案例

1). 查询在2017年4月份购买过的顾客及总人数
select name, count(1) over() from business where orderdate like "2017-04-%" group by name;

2). 查询顾客的购买明细及月购买总额
select name, orderdate, cost, sum(cost) over(partition by month(orderdate)) from business;
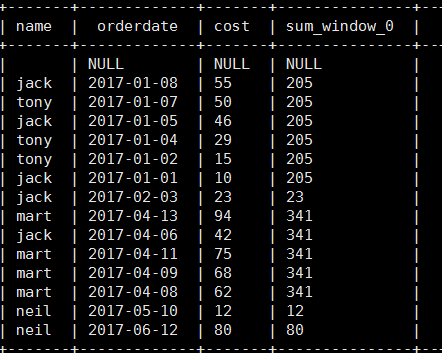
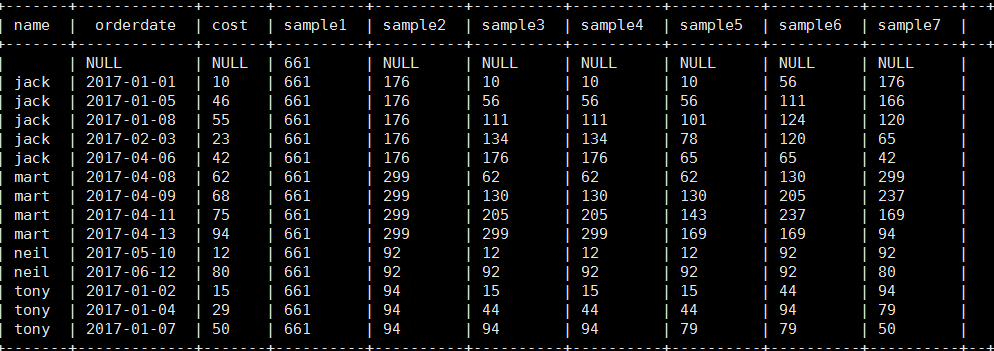
3). 将每个顾客的cost按照日期进行累加
select name,orderdate,cost, sum(cost) over() as sample1,--所有行相加 sum(cost) over(partition by name) as sample2,--按name分组,组内数据相加 sum(cost) over(partition by name order by orderdate) as sample3,--按name分组,组内数据累加 sum(cost) over(partition by name order by orderdate rows between UNBOUNDED PRECEDING and current row ) as sample4 ,--和sample3一样,由起点到当前行的聚合 sum(cost) over(partition by name order by orderdate rows between 1 PRECEDING and current row) as sample5, --当前行和前面一行做聚合 sum(cost) over(partition by name order by orderdate rows between 1 PRECEDING AND 1 FOLLOWING ) as sample6,--当前行和前边一行及后面一行 sum(cost) over(partition by name order by orderdate rows between current row and UNBOUNDED FOLLOWING ) as sample7 --当前行及后面所有行 from business;
4). 查看顾客上次的购买时间
select name,orderdate,cost, lag(orderdate,1,'first_buy') over(partition by name order by orderdate ) from business;

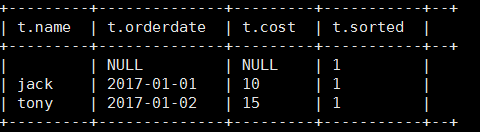
5). 查询前20%时间的订单信息
select * from ( select name,orderdate,cost, ntile(5) over(order by orderdate) sorted from business ) t where sorted = 1;
六. Rank
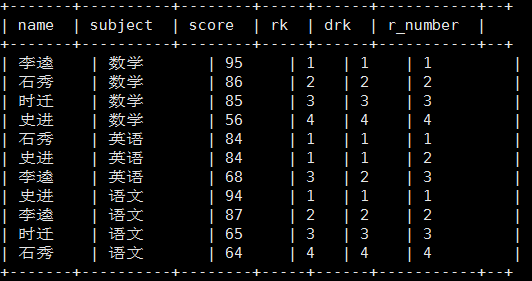
1.函数说明
RANK() 排序相同时会重复,总数不会变
DENSE_RANK() 排序相同时会重复,总数会减少
ROW_NUMBER() 会根据顺序计算
2. 案例

计算每门学科成绩排名
select name, subject, score, rank() over(partition by subject order by score desc) rk, dense_rank() over(partition by subject order by score desc) drk, row_number() over(partition by subject order by score desc) r_number from score;

 浙公网安备 33010602011771号
浙公网安备 33010602011771号