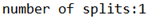Hadoop(14)-MapReduce框架原理-切片机制
1.FileInputFormat切片机制
切片机制

比如一个文件夹下有5个小文件,切片时会切5个片,而不是一个片
案例分析

2.FileInputFormat切片大小的参数配置
源码中计算切片大小的公式

切片大小设置

获取切片大小API

3. CombineTextInputFormat切片机制
框架默认的TextInputFormat切片机制是对任务按文件规划切片,不管文件多小,都会是一个单独的切片,都会交给一个MapTask,这样如果有大量小文件,就会产生大量的MapTask,处理效率极其低下。
1)应用场景
CombineTextInputFormat用于小文件过多的场景,它可以将多个小文件从逻辑上规划到一个切片中,这样,多个小文件就可以交给一个MapTask处理。
2)虚拟存储切片最大值设置
CombineTextInputFormat.setMaxInputSplitSize(job, 4194304);// 4m
注意:虚拟存储切片最大值设置最好根据实际的小文件大小情况来设置具体的值
3)切片机制
生成切片过程包括:虚拟存储过程和切片过程二部分

(1)虚拟存储过程:
将输入目录下所有文件大小,依次和设置的setMaxInputSplitSize值比较,如果不大于设置的最大值,逻辑上划分一个块。如果输入文件大于设置的最大值且大于两倍,那么以最大值切割一块;当剩余数据大小超过设置的最大值且不大于最大值2倍,此时将文件均分成2个虚拟存储块(防止出现太小切片)。
例如setMaxInputSplitSize值为4M,输入文件大小为8.02M,则先逻辑上分成一个4M。剩余的大小为4.02M,如果按照4M逻辑划分,就会出现0.02M的小的虚拟存储文件,所以将剩余的4.02M文件切分成(2.01M和2.01M)两个文件。
(2)切片过程:
(a)判断虚拟存储的文件大小是否大于setMaxInputSplitSize值,大于等于则单独形成一个切片。
(b)如果不大于则跟下一个虚拟存储文件进行合并,共同形成一个切片。
(c)测试举例:有4个小文件大小分别为1.7M、5.1M、3.4M以及6.8M这四个小文件,则虚拟存储之后形成6个文件块,大小分别为:
1.7M,(2.55M、2.55M),3.4M以及(3.4M、3.4M)
最终会形成3个切片,大小分别为:
(1.7+2.55)M,(2.55+3.4)M,(3.4+3.4)M
4.CombineTextInputFormat案例实操
准备四个小文件,大小在1M左右,以之前的wordcount代码为基础
直接运行代码,观察console

在WcDriver.class中,增加如下代码
// 如果不设置InputFormat,它默认用的是TextInputFormat.class job.setInputFormatClass(CombineTextInputFormat.class); //虚拟存储切片最大值设置4m CombineTextInputFormat.setMaxInputSplitSize(job, 4194304);
观察console
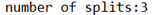
继续修改Wcdriver.class
//虚拟存储切片最大值设置20m CombineTextInputFormat.setMaxInputSplitSize(job, 20971520)
观察console