
kano模型
KANO模型是一种质量管理工具,用于帮助企业了解客户需求和期望。它由日本学者狩野纯提出,并于1984年首次发表。
KANO模型基于对产品或服务特性与客户满意度之间关系的理解。
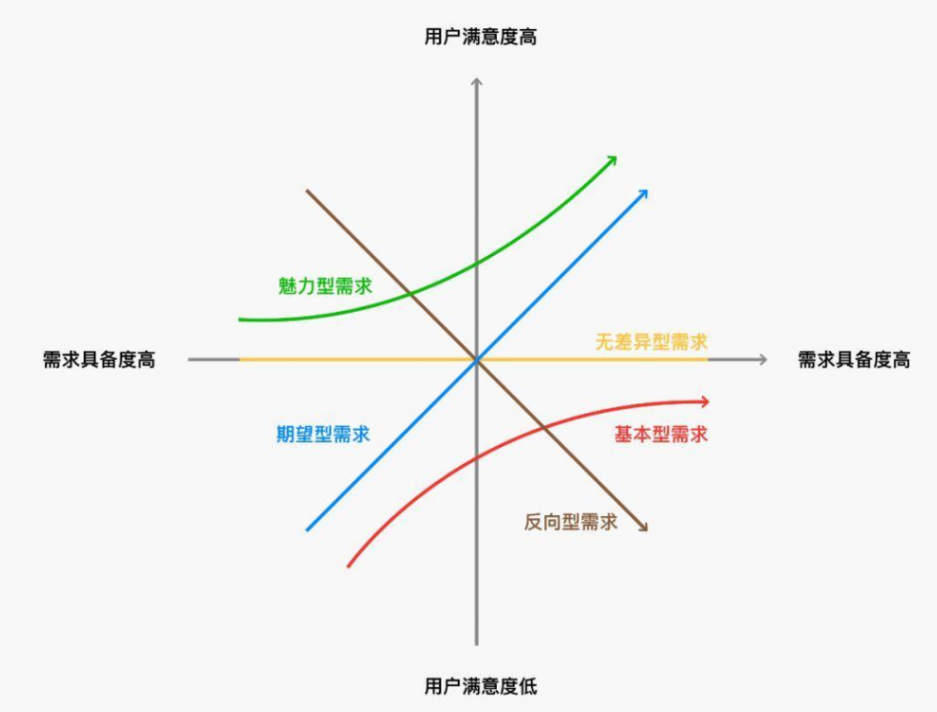
它将客户需求分为五个类别:
- 基本要素(Basic Factors):这些是客户对产品或服务的基本要求,如果没有满足这些要求,客户会非常不满意。但是,满足了这些要求并不能带来额外的满意度。例如,一台电视必须能够正常显示图像和声音。
- 期望要素(Performance Factors):这些是客户明确要求的特性,满足了这些要求可以提高客户的满意度。客户期望产品或服务在这些方面表现良好,但不满足这些要求不会导致极度不满意。例如,电视的画质清晰度和声音质量。
- 意外要素(Excitement Factors):这些是客户未明确要求但却非常令人满意的特性。它们超出了客户的期望,并给客户带来惊喜和额外的满意度。例如,电视具有智能功能或特殊的设计风格。
- 无差异型要素(Indifferent Factors):这些是对客户没有影响的特性。无论满足与否,都不会对客户的满意度产生显著影响。例如,电视外壳的颜色对大多数客户来说并不重要。
- 反向要素(Reverse Factors):这些是本来以为能带来满意度的特性,但实际上却导致了客户的不满意。在这种情况下,满足这些要求反而会降低客户的满意度。例如,电视遥控器上按钮布局不合理。
通过使用KANO模型,企业可以更好地了解客户的需求和期望,并根据不同类型的要素来制定产品或服务的策略。这有助于提高客户满意度,增强竞争力,并推动业务的持续发展。
通过使用KANO模型,企业可以更好地了解客户的需求和期望,并根据不同类型的要素来制定产品或服务的策略。这有助于提高客户满意度,增强竞争力,并推动业务的持续发展。
调研问卷设计
KANO 问卷中每个功能都要有正向和反向两个问题,例如:

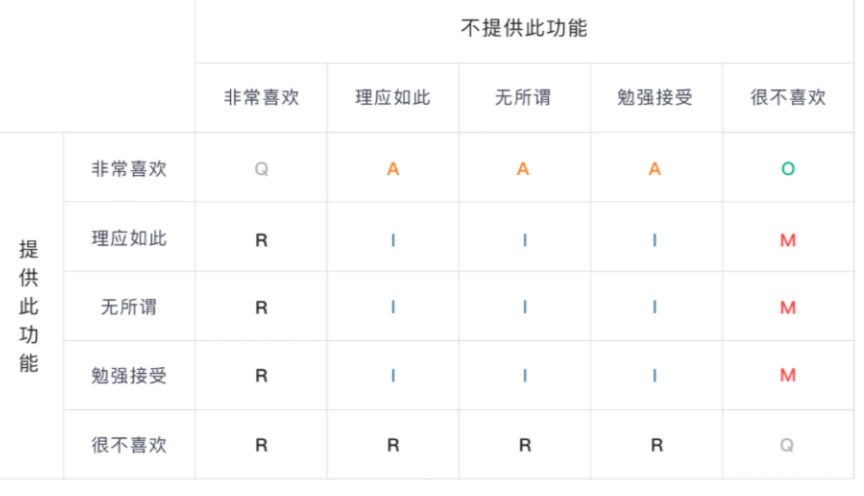
按照用户对增加功能态度与不增加功能态度(每个功能都是两个问题),最终我们可以通过下表定位某功能对于用户来说是什么需求。
M:基本(必备)型需求;O:期望(意愿)型需求;A:兴奋(魅力)型需求
I:无差异型需求;R:反向(逆向)型需求;Q:可疑结果
设定矩阵
数据分析统计
将某个功能的两个问题的结果对照 上图矩阵,得出结果。
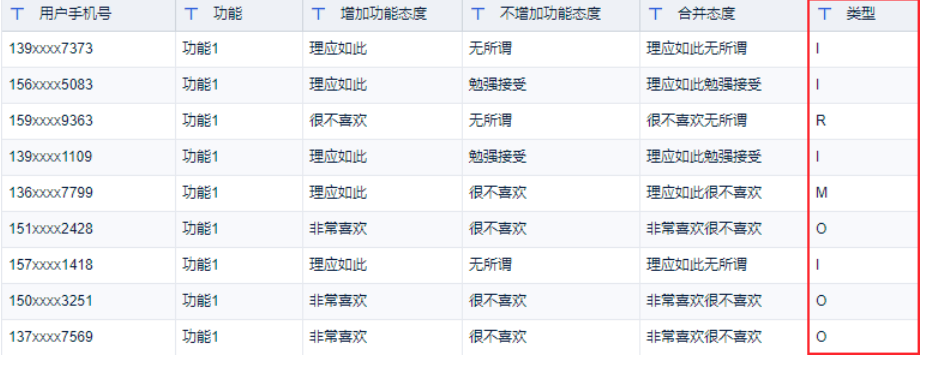
统计分析 M O A I R 各类型的占比!
使用 better-worse 系数
如下图所示:
better-增加某功能后提升的满意系数:
better=(A占比+O占比)/(A占比+O占比+M占比+I占比),越接近 1,则表示用户满意度提升的效果会越强,满意度上升的越快。
worse-不增加某功能用户的不满意系数:
worse=-1*(O占比+M占比)/(A占比+O占比+M占比+I占比),越接近 -1,则表示对用户不满意度的影响越大,满意度下降的越快。


