国庆长假已结束,Python 告诉你 6 亿国人都去哪儿浪了附源码
看到了网上的一篇文章,把完整源码附上
据新华网消息,整个国庆长假外出游玩人次达 6.37 亿人次,那么这么多人都到哪儿去玩了呢,今天我们就用 Python 做一个全国热门景区热点图。
入口
先说程序入口:https://piao.qunar.com/ticket/list_热门景点.html?from=mps_search_suggest_h
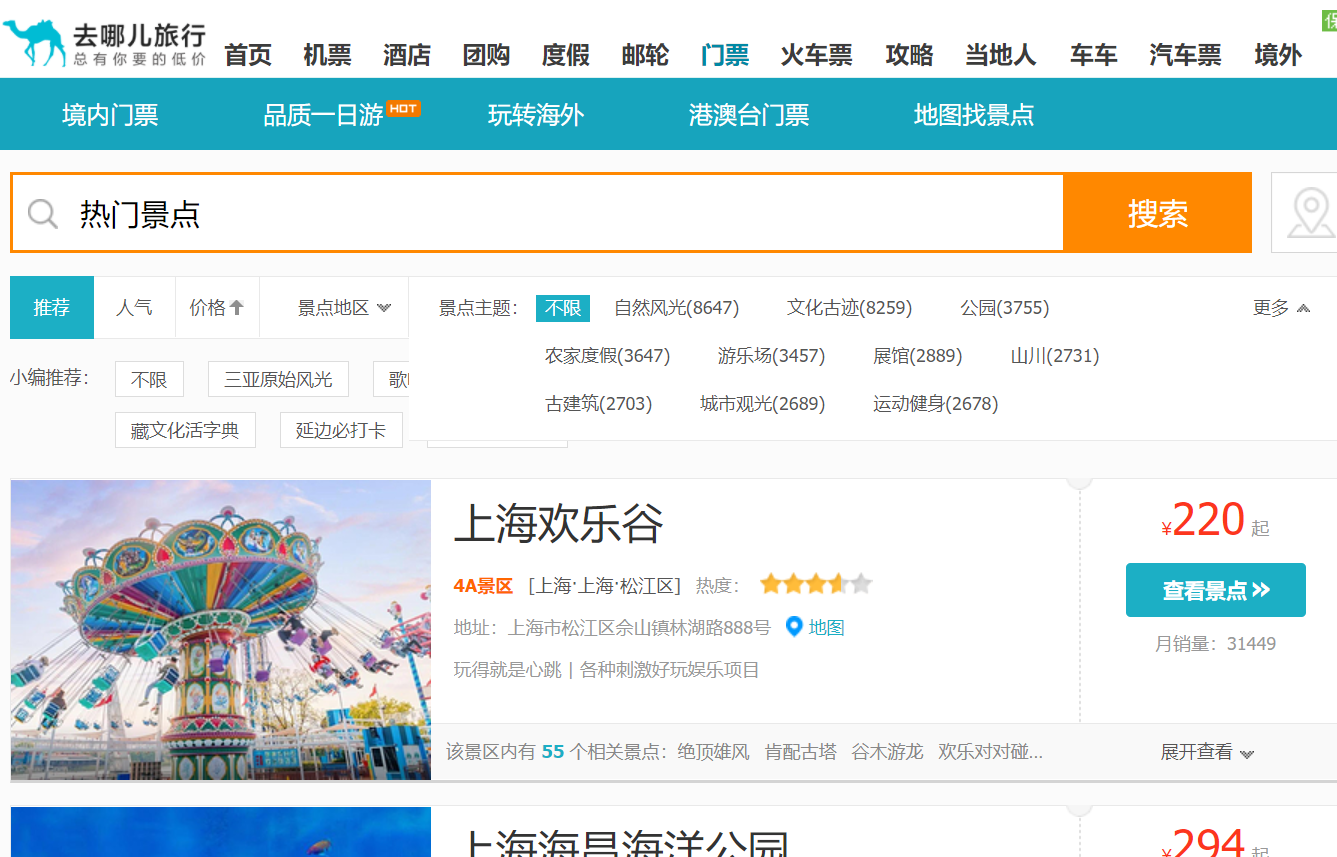
发现去哪儿网有一个「热门景点」的内页,在首页输入框直接输入「热门景点」即可直达该页面。该网站还将这些热门景点进行了分类,比如人文景观,城市风貌,古建筑等。同时我们需要的景点名称,城市,景区级别以及景区地址等信息都可以从该页面获取的到。
打开去哪儿网,首页输入「热门景点」仔细观察页面最上方的 URL 你会发现惊喜。其中 subject 就是景点主题,而 page 看样子则是页码,点击下一页验证一下,page 变成 2 了,没猜错。
分析完 URL 之后,再来看看数据从什么地方获取的,切换到浏览器开发者模式,浏览下我们发现所有的景点数据都在一个叫做 ”search-list“ 的 div 中。针对单个景点,其数据是在一个 class = ‘sight_item’ 的 div 中。接下来就是解析页面原属,将景点,省市,时间,热度等数据做分析。
采集数据
数据源头已经分析完毕,接下来就可以开始我们的爬虫编码了,首先定义好我们的准备获取全国景点的主题。为了方便后续操作,我们可以将解析好的数据保存到 csv 文件中。
import requests
import csv
import time
from bs4 import BeautifulSoup
subjects = ['文化古迹', '自然风光', '农家度假', '游乐场', '展馆', '古建筑', '城市观光']
excel_file = open('data.csv', 'w', encoding='utf-8', newline='')
writer = csv.writer(excel_file)
writer.writerow(['名称', '城市', '类型', '级别', '热度', '地址'])
其次我们需要一个下载网页内容的函数,该函数接受一个 URL 参数,之后返回该 URL 对应的网页内容,同时为了更真实的模拟浏览器请求,需要添加 Headers。
headers = {
'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.102 Safari/537.36',
'accept-encoding': 'gzip, deflate, br',
'accept-language': 'zh-CN,zh;q=0.9,en;q=0.8',
'referer': 'https://piao.qunar.com/',
'cookie': 'xxxyyyzzz...'
}
def get_page_html(url):
try:
response = requests.get(url, headers=headers)
if response.status_code == 200:
return response.text
return None
except RequestException:
return None
获取到内容之后,我们还需要一个解析函数,该函数接收一个网页文本,然后将我们所需要的「名称, 城市, 类型, 级别, 热度, 地址」信息解析出来,并写入 csv 文件。
def parse_content(content, subject):
if not content:
return;
soup = BeautifulSoup(content, "html.parser")
search_list = soup.find(id='search-list')
items = search_list.find_all('div', class_="sight_item")
for item in items:
name = item['data-sight-name']
districts = item['data-districts']
address = item['data-address']
level = item.find('span', class_='level')
level = level.text if level else ''
star = item.find('span', class_='product_star_level')
star = star.text if star else ''
writer.writerow([name, districts, subject, level, star, address])
至此我们已经准备好,下载函数,解析函数,现在只需要直接遍历主题,拼接 URL 调用相关函数即可。为了防止被禁封 IP,每次请求之后让程序暂停 5 秒。
def get_data():
for subject in subjects:
for page in range(5): #抓5页的数据就可以了,盗亦有道啊
page = page + 1
url = F'https://piao.qunar.com/ticket/list.htm?keyword=热门景点®ion=&from=mps_search_suggest&subject={subject}&page={page}&sku='
print(url)
content = get_page_html(url)
parse_content(content, subject, url)
time.sleep(5)
数据分析
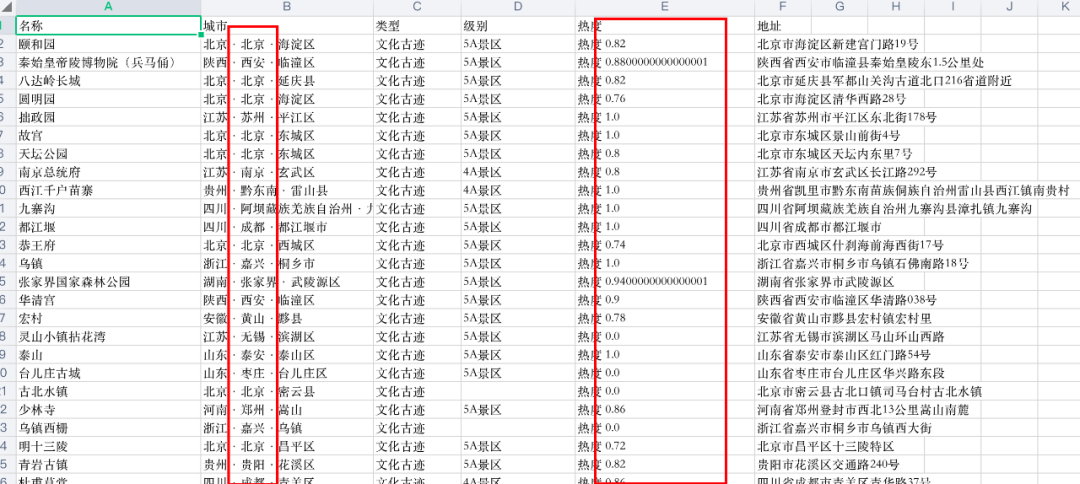
获取到全国的旅游数据之后,就可以开始分析了。为了让操作方便,引入 pandas,先仔细看下我们的数据格式。首先热度一列里面含有中文,需要分割,其次因为热度数值是小数不方便操作,因此我们决定将热度扩大 1000 倍,因为是整体扩大了 1000 倍,因此并不会影响分析结果。
之后我们需要解析出该景点所在的城市。同样是分割字符串。同时因为还有一些地点是地图无法识别的,所以要去除。
import csv
import pandas as pd
from pyecharts.globals import ChartType
from pyecharts.charts import Geo
from pyecharts import options as opts
data = []
with open(r'data.csv', 'r',encoding='utf8') as f:
reader = csv.reader(f)
header = next(reader)
for row in reader:
data.append(row)
df_data = []
for row in data:
try: #可能某些数据有错误,所以加上一个监测
city = row[1].split('·')[1]
except:
continue
if city in ['保亭', '德宏', '湘西', '陵水', '黔东南', '黔南']:
continue
star = row[4].split('热度')[1].strip()
star = int(float(star) * 1000)
df_data.append([row[0], city, row[3], star])
df = pd.DataFrame(df_data, columns=['name', 'city', 'level', 'star'])
data = df.groupby(by=['city'])['star'].sum()
citys = list(data.index)
city_stars = list(data)
data = [list(z) for z in zip(citys, city_stars)]
生产热点地图
geo = (
Geo()
.add_schema(maptype="china")
.add(
"热点图", #图题
data,
type_=ChartType.HEATMAP, #地图类型
)
.set_series_opts(label_opts=opts.LabelOpts(is_show=False)) #设置是否显示标签
.set_global_opts(
visualmap_opts=opts.VisualMapOpts(max_ = 5000), #设置legend显示的最大值
title_opts=opts.TitleOpts(title=""), #左上角标题
)
)
geo.render_notebook() #notebook渲染
# geo.render('geo.html') #输出到html文件
生成柱状图
from pyecharts.charts import Bar
data.sort(key=lambda x:x[1], reverse=True)
xaxis=[]
yaxis=[]
for x in range(15):
xaxis.append(data[x][0])
yaxis.append(data[x][1])
bar1=(
Bar() ##定义为柱状图
.add_xaxis(xaxis) ##X轴的值
.add_yaxis(' TOP 15 的热点旅游城市',yaxis) # #y的值和y的一些数据配置项
)
# bar1.render('bar1.html') ###输出html文件
bar1.render_notebook()
生产饼图
from pyecharts.charts import Pie
data3 = df.groupby(by=['name'])['star'].sum()
names = list(data3.index)
name_stars = list(data3)
data3 = [list(z) for z in zip(names, name_stars)]
data3.sort(key=lambda x:x[1], reverse=True)
pie = Pie()
pie.add('',data3[:10])
pie.render_notebook()


 浙公网安备 33010602011771号
浙公网安备 33010602011771号