
最好理解的字符串匹配的KMP算法
字符串匹配是计算机的基本任务之一。
一、KMP 算法简介
举例来说,有一个字符串"BBC ABCDAB ABCDABCDABDE",我想知道,里面是否包含另一个字符串"ABCDABD"?许多算法可以完成这个任务,Knuth-Morris-Pratt算法(简称KMP)是最常用的之一。
KMP 算法是由三位老前辈(D.E.Knuth,J.H.Morris 和 V.R.Pratt )的研究结果,该算法巧妙之处在于避免重复遍历的情况,全称叫做克努特-莫里斯-普拉特算法,简称 KMP 算法,D.E.Knuth,编写了《计算机程序设计艺术》写完了第四卷,这部著作被誉为计算机领域中的“相对论”。
二、算法核心
前缀后缀的概念
以字符串 “bread”为例
前缀的概念:指除了最后一个字符以外,一个字符串的全部头部组合。 b,br,bre,brea
后缀的概念:指除了第一个字符以外,一个字符串的全部尾部组合。 read,ead,ad,d
部分匹配值的计算
"部分匹配值"就是"前缀"和"后缀"的 最长的交集 的长度。以"ABCDABD"为例,
- "A"的前缀和后缀都为空集,没有交集,长度为0;
- "AB"的前缀为[A],后缀为[B],没有交集,长度为0;
- "ABC"的前缀为[A, AB],后缀为[BC, C],没有交集,长度为0;
- "ABCD"的前缀为[A, AB, ABC],后缀为[BCD, CD, D],没有交集,为0;
- "ABCDA"的前缀为[A, AB, ABC, ABCD],后缀为[BCDA, CDA, DA, A],最长的交集为"A",长度为1;
- "ABCDAB"的前缀为[A, AB, ABC, ABCD, ABCDA],后缀为[BCDAB, CDAB, DAB, AB, B],最长的交集为"AB",长度为2;
- "ABCDABD"的前缀为[A, AB, ABC, ABCD, ABCDA, ABCDAB],后缀为[BCDABD, CDABD, DABD, ABD, BD, D],没有交集,长度为0;
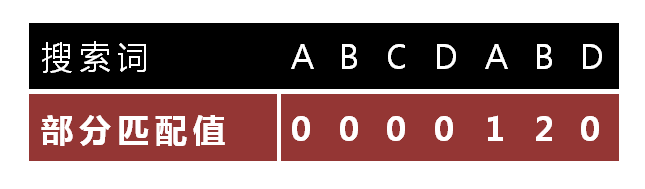
务必要理解上图的 部分匹配值 串
三、开始算法
1.

首先,字符串"BBC ABCDAB ABCDABCDABDE"的第一个字符与搜索词"ABCDABD"的第一个字符,进行比较。因为B与A不匹配,所以搜索词后移一位。
2.

因为B与A不匹配,搜索词再往后移。
3.

就这样,直到字符串有一个字符与搜索词的第一个字符相同为止。
4.

接着比较字符串和搜索词的下一个字符,还是相同。
5.

直到字符串有一个字符,与搜索词对应的字符不相同为止。
6.

这时,最自然的反应是BF算法(暴力),将搜索词整个后移一位,再从头逐个比较。这样做虽然可行,但是效率很差,因为你要要一位一位的移动。
能不能多多移动几位呢?
我前面都比较那么久了,一个基本事实是,当空格与D不匹配时,你其实知道前面六个字符是"ABCDAB"。
7.开始体现KMP算法的魅力!
KMP算法的想法是,设法利用这个已知信息,多 移动几位!
怎么做到这一点呢?可以针对搜索词,算出一张《部分匹配表》(Partial Match Table)。
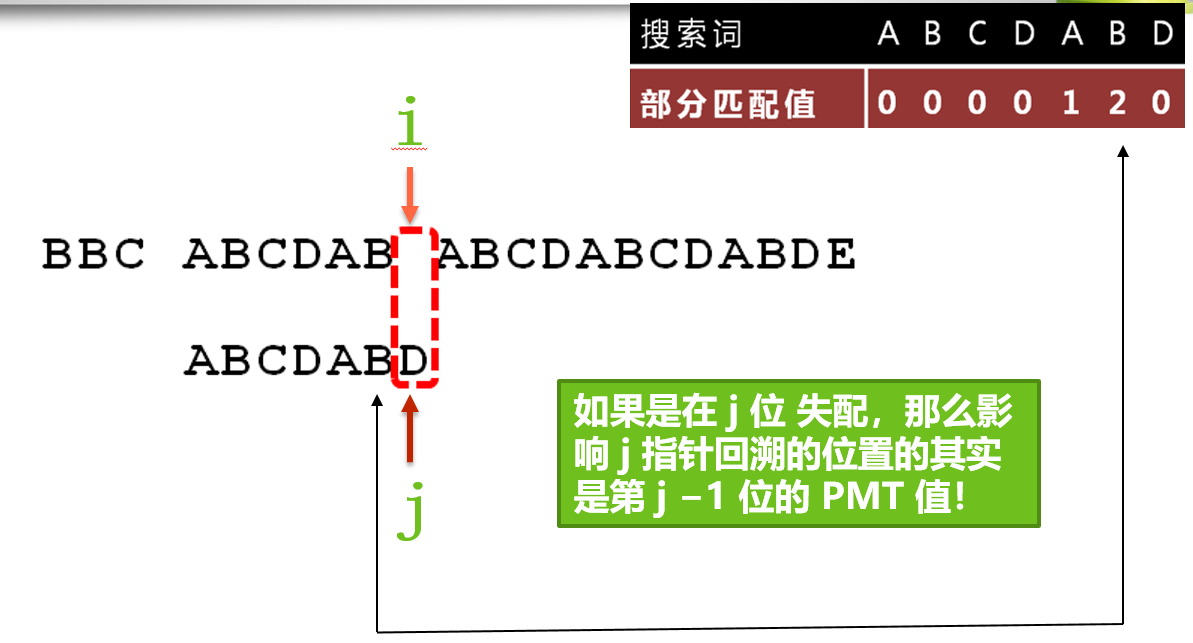
上图很重要!
分析:当计算的此位置的时候,发现 指针i 指向的是空格,指针j 指向的是 D ,不符合。因为j>0,就是前面已经有匹配成功的了,则不能轻易就把j打回到0点。我们希望能多移动几位。
此时,开始 查询 ** j-1 ** 位置的 pmt表(为什么是j-1,因为我考虑的是前面已经匹配成功的部分;pmt表里的值,也是当前位置的以前的字符串的最长匹配值)。

查询结果为 2 ,则将 j 移动到索引为 2 的位置。
发现 的确 可以多移动了几位了,而不是直接 打回 0 。
后面的部分就不再多做解释了,上代码!
def strStr(haystack, needle):
def bfppz(needle): # 部分匹配表的计算
def qianz(aa): # 取出前缀
qianz_list = []
for y in range(len(aa) - 1):
qianz_list.append(aa[:y + 1])
return qianz_list
def houz(bb): # 取出后缀
houz_list = []
for z in range(1, len(bb)):
houz_list.append(bb[z:])
return houz_list
bfppz_list = []
for x in range(1, len(needle) + 1):
len_list = set(qianz(needle[:x])) & set(houz(needle[:x]))
max_len = 0
for m in len_list:
max_len = max(max_len, len(m)) # 取出最大交集长度
bfppz_list.append(max_len) #添加进 pmt表
return bfppz_list
if needle=='':
return 0
haystack_len = len(haystack)
needle_len = len(needle)
if needle_len>haystack_len:
return -1
bfppz_lista = bfppz(needle)
i = 0
j = 0
while i < haystack_len:
if haystack[i] == needle[j]:
i += 1
j += 1
else:
if j==0:
i+=1
else:
j=bfppz_lista[j-1]
if j == needle_len: #匹配成功
return i-needle_len
return -1 #匹配失败
print(strStr("BBC ABCDAB ABCDABCDABDE", "ABCDABD"))
进阶
ABCDABD 子串,在创建部分匹配表的时候,如果暴力求每个字符段的最长前缀(前缀与后缀交集的最长前/后缀,下面都简称最长前缀了)太复杂,特别是字符串长度长了之后,集合的元素个数更是呈指数增长了。更不用说交集什么的了!
力扣里面会给一个几万字符的模式串。如果暴力求pmt的话,直接超时了。

所以为了编程的方便, 我们不直接使用PMT数组,而是将PMT数组向后偏移一位。我们把新得到的这个数组称为next数组。
要注意的一个技巧是,在把PMT进行向右偏移时,第0位的值,我们将其设成了-1,这只是为了编程的方便,并没有其他的意义。
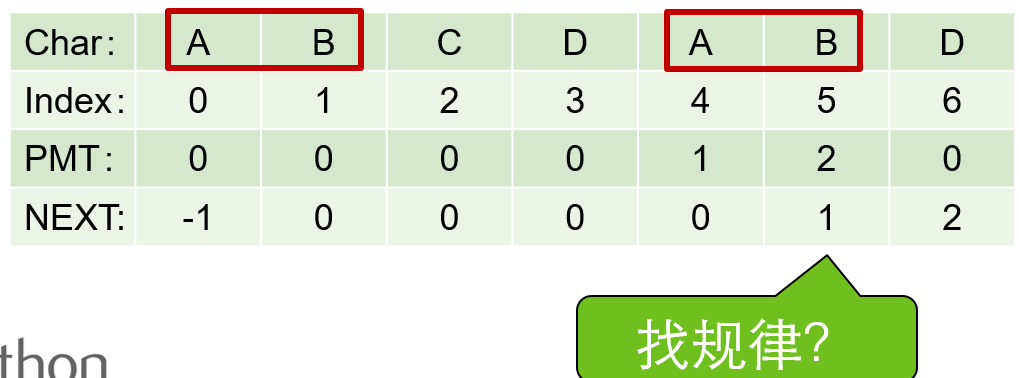
求next数组的过程完全可以看成字符串匹配的过程。
就是从模式字符串的第一位(注意,不包括第0位)开始对自身进行匹配运算。 在任一位置,能匹配的最长长度就是当前位置的next值。
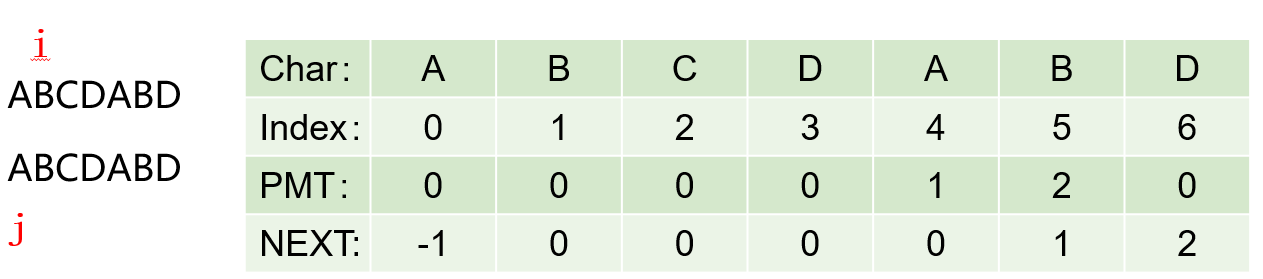
# 求next数组
next = [-1] * len(needle) #主要是第一个 next[0]要设为 -1
if len(needle) > 1: # 这里加if是怕列表越界
next[1] = 0
i, j = 1, 0
while i < len(needle) - 1: # 这里一定要-1,不然会像例子中出现next[8]会越界的
if j == -1 or needle[i] == needle[j]:
i += 1
j += 1
next[i] = j #前面有几位相同,就记录下来
else:
j = next[j]
终极代码
def strStr(haystack, needle):
# 传入一个母串和一个子串
# 返回子串匹配上的第一个位置,若没有匹配上返回-1
test = ''
next = []
if type(haystack) != type(test) or type(needle) != type(test):
return -1
if len(needle) == 0:
return 0
if len(haystack) == 0:
return -1
# 求next数组
next = [-1] * len(needle)
if len(needle) > 1: # 这里加if是怕列表越界
next[1] = 0
i, j = 1, 0
while i < len(needle) - 1: # 这里一定要-1,不然会像例子中出现next[8]会越界的
if j == -1 or needle[i] == needle[j]:
i += 1
j += 1
next[i] = j
else:
j = next[j]
# kmp框架
m = s = 0 # 母指针和子指针初始化为0
while (s < len(needle) and m < len(haystack)):
# 匹配成功,或者遍历完母串匹配失败退出
if s == -1 or haystack[m] == needle[s]:
m += 1
s += 1
else:
s = next[s]
if s == len(needle): # 匹配成功
return m - s
# 匹配失败
return -1
print(strStr("BBC ABCDAB ABCDABCDABDE", "ABCDABD"))
参考原文:http://www.ruanyifeng.com/blog/2013/05/Knuth–Morris–Pratt_algorithm.html
参考了 阮一峰 文章中大量的内容,并根据自己的理解情况作了调整。感谢!

