数据分析之KAGGLE-泰坦尼克号人员生存预测问题
本文参考 handsye https://blog.csdn.net/handsye/article/details/83999641
对部分内容进行了修正和整理
数据分析之KAGGLE-泰坦尼克号人员生存预测问题
分析目的
完成对什么样的人可能生存的分析。
# 导入相关数据包
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
%matplotlib inline
数据说明
|特征|描述|
|---||
|survival|生存|
|pclass|票类别|
|sex|性别|
|Age|年龄|
|sibsp|兄弟姐妹/配偶|
|parch|父母/孩子的数量|
|ticket|票号|
|fare|乘客票价|
|cabin|客舱号码|
|embarked|登船港口|
train = pd.read_csv("d:\\titanic\\train.csv")
test = pd.read_csv("d:\\titanic\\test.csv")
#看一下数据特征
train.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 891 entries, 0 to 890
Data columns (total 12 columns):
PassengerId 891 non-null int64
Survived 891 non-null int64
Pclass 891 non-null int64
Name 891 non-null object
Sex 891 non-null object
Age 714 non-null float64
SibSp 891 non-null int64
Parch 891 non-null int64
Ticket 891 non-null object
Fare 891 non-null float64
Cabin 204 non-null object
Embarked 889 non-null object
dtypes: float64(2), int64(5), object(5)
memory usage: 83.7+ KB
#默认输出前五行数据
train.head()
| PassengerId | Survived | Pclass | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 0 | 3 | Braund, Mr. Owen Harris | male | 22.0 | 1 | 0 | A/5 21171 | 7.2500 | NaN | S |
| 1 | 2 | 1 | 1 | Cumings, Mrs. John Bradley (Florence Briggs Th... | female | 38.0 | 1 | 0 | PC 17599 | 71.2833 | C85 | C |
| 2 | 3 | 1 | 3 | Heikkinen, Miss. Laina | female | 26.0 | 0 | 0 | STON/O2. 3101282 | 7.9250 | NaN | S |
| 3 | 4 | 1 | 1 | Futrelle, Mrs. Jacques Heath (Lily May Peel) | female | 35.0 | 1 | 0 | 113803 | 53.1000 | C123 | S |
| 4 | 5 | 0 | 3 | Allen, Mr. William Henry | male | 35.0 | 0 | 0 | 373450 | 8.0500 | NaN | S |
train.describe()
| PassengerId | Survived | Pclass | Age | SibSp | Parch | Fare | |
|---|---|---|---|---|---|---|---|
| count | 891.000000 | 891.000000 | 891.000000 | 714.000000 | 891.000000 | 891.000000 | 891.000000 |
| mean | 446.000000 | 0.383838 | 2.308642 | 29.699118 | 0.523008 | 0.381594 | 32.204208 |
| std | 257.353842 | 0.486592 | 0.836071 | 14.526497 | 1.102743 | 0.806057 | 49.693429 |
| min | 1.000000 | 0.000000 | 1.000000 | 0.420000 | 0.000000 | 0.000000 | 0.000000 |
| 25% | 223.500000 | 0.000000 | 2.000000 | 20.125000 | 0.000000 | 0.000000 | 7.910400 |
| 50% | 446.000000 | 0.000000 | 3.000000 | 28.000000 | 0.000000 | 0.000000 | 14.454200 |
| 75% | 668.500000 | 1.000000 | 3.000000 | 38.000000 | 1.000000 | 0.000000 | 31.000000 |
| max | 891.000000 | 1.000000 | 3.000000 | 80.000000 | 8.000000 | 6.000000 | 512.329200 |
# train.hist(figsize=(16,14))
# sns.pairplot(train,hue='Survived')
train.plot(kind='box', subplots=True, layout=(3,3), sharex=False,sharey=False, figsize=(16,14))
PassengerId AxesSubplot(0.125,0.657941;0.227941x0.222059)
Survived AxesSubplot(0.398529,0.657941;0.227941x0.222059)
Pclass AxesSubplot(0.672059,0.657941;0.227941x0.222059)
Age AxesSubplot(0.125,0.391471;0.227941x0.222059)
SibSp AxesSubplot(0.398529,0.391471;0.227941x0.222059)
Parch AxesSubplot(0.672059,0.391471;0.227941x0.222059)
Fare AxesSubplot(0.125,0.125;0.227941x0.222059)
dtype: object
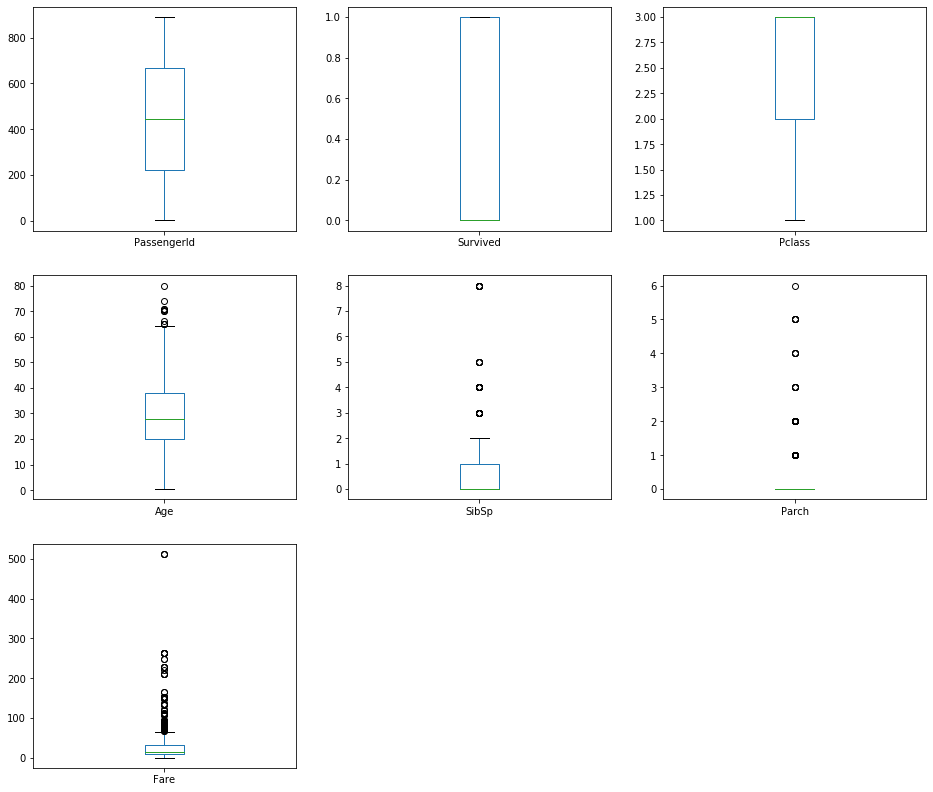
特征分析
数值型变量之间的相关性
# 相关性协方差表,corr()函数
train_corr = train.drop('PassengerId',axis=1).corr()
train_corr
| Survived | Pclass | Age | SibSp | Parch | Fare | |
|---|---|---|---|---|---|---|
| Survived | 1.000000 | -0.338481 | -0.077221 | -0.035322 | 0.081629 | 0.257307 |
| Pclass | -0.338481 | 1.000000 | -0.369226 | 0.083081 | 0.018443 | -0.549500 |
| Age | -0.077221 | -0.369226 | 1.000000 | -0.308247 | -0.189119 | 0.096067 |
| SibSp | -0.035322 | 0.083081 | -0.308247 | 1.000000 | 0.414838 | 0.159651 |
| Parch | 0.081629 | 0.018443 | -0.189119 | 0.414838 | 1.000000 | 0.216225 |
| Fare | 0.257307 | -0.549500 | 0.096067 | 0.159651 | 0.216225 | 1.000000 |
plt.subplots(figsize=(10,4)) # 可以先试用plt设置画布的大小,然后在作图,修改
sns.heatmap(train_corr, annot = True) # 使用热度图可视化这个相关系数矩阵
<matplotlib.axes._subplots.AxesSubplot at 0x1bf5f875c08>
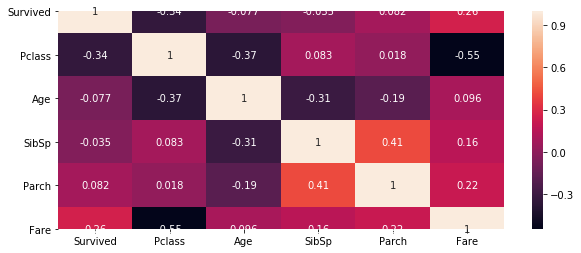
2.2分析每个变量与结果之间的关系
#Pclass 乘客等级
# train_p = train.groupby(['Pclass'])['Pclass','Survived'].mean()
train_p =train[['Pclass','Survived']].groupby(['Pclass']).mean()
train_p
| Survived | |
|---|---|
| Pclass | |
| 1 | 0.629630 |
| 2 | 0.472826 |
| 3 | 0.242363 |
#条形图
train[['Pclass','Survived']].groupby(['Pclass']).mean().plot.bar()
<matplotlib.axes._subplots.AxesSubplot at 0x1bf5f8f8d48>
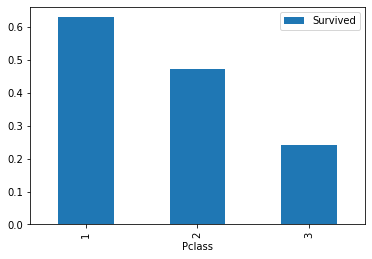
#性别
train_s = train.groupby(['Sex'])['Sex','Survived'].mean()
train_s
| Survived | |
|---|---|
| Sex | |
| female | 0.742038 |
| male | 0.188908 |
#条形图
#女性有更高的存活率
train[['Sex','Survived']].groupby(['Sex']).mean().plot.bar()
<matplotlib.axes._subplots.AxesSubplot at 0x1bf616c8088>
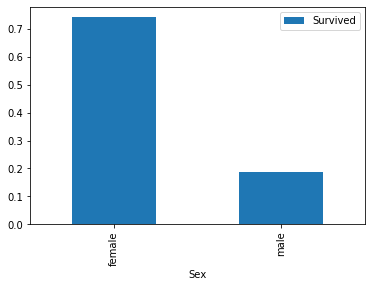
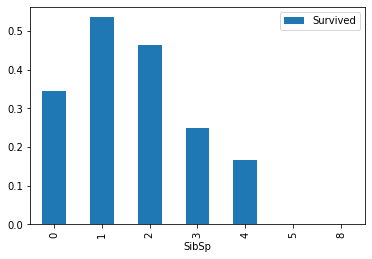
#兄弟姊妹数
train[['SibSp','Survived']].groupby(['SibSp']).mean().plot.bar()
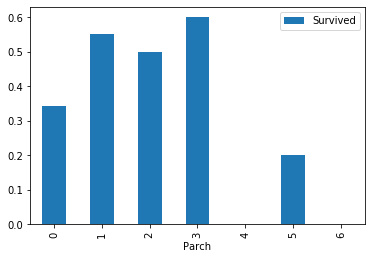
#父母子女数
train[['Parch','Survived']].groupby(['Parch']).mean().plot.bar()
<matplotlib.axes._subplots.AxesSubplot at 0x1bf6175ea48>
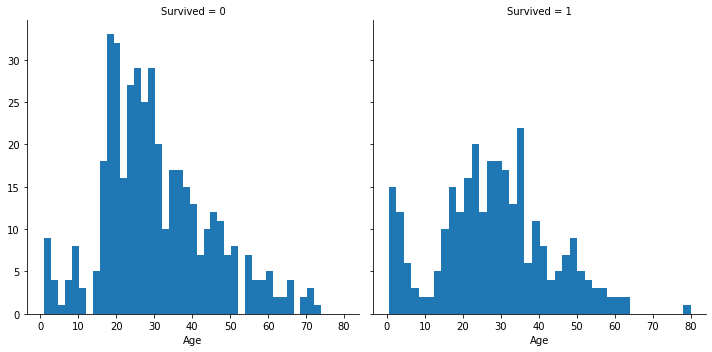
#年龄与生存情况的分析
#年龄是有大部分缺失值的,缺失值需要进行处理,可以使用填充或者模型预测
train_g = sns.FacetGrid(train, col='Survived',height=5)
train_g.map(plt.hist, 'Age', bins=40)
<seaborn.axisgrid.FacetGrid at 0x1bf61802508>
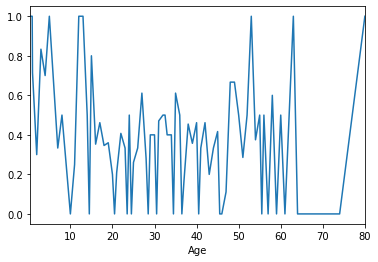
train.groupby(['Age'])['Survived'].mean().plot()
<matplotlib.axes._subplots.AxesSubplot at 0x1bf640973c8>
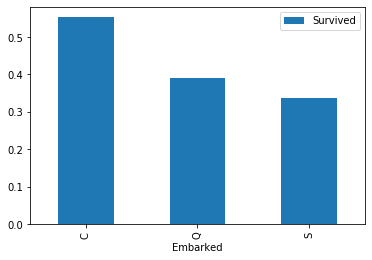
#登港港口与生存情况的分析
#可以看出C地的生存率更高
train_e = train[['Embarked','Survived']].groupby(['Embarked']).mean().plot.bar()
特征工程
#先将数据集合并,一起做特征工程(注意,标准化的时候需要分开处理)
#先将test补齐,然后通过pd.apped()合并
test['Survived'] = 0
#test.head()
train_test = train.append(test,sort=False)
train_test.head()
| PassengerId | Survived | Pclass | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 0 | 3 | Braund, Mr. Owen Harris | male | 22.0 | 1 | 0 | A/5 21171 | 7.2500 | NaN | S |
| 1 | 2 | 1 | 1 | Cumings, Mrs. John Bradley (Florence Briggs Th... | female | 38.0 | 1 | 0 | PC 17599 | 71.2833 | C85 | C |
| 2 | 3 | 1 | 3 | Heikkinen, Miss. Laina | female | 26.0 | 0 | 0 | STON/O2. 3101282 | 7.9250 | NaN | S |
| 3 | 4 | 1 | 1 | Futrelle, Mrs. Jacques Heath (Lily May Peel) | female | 35.0 | 1 | 0 | 113803 | 53.1000 | C123 | S |
| 4 | 5 | 0 | 3 | Allen, Mr. William Henry | male | 35.0 | 0 | 0 | 373450 | 8.0500 | NaN | S |
特征处理
Pclass,乘客等级,1是最高级
train_test = pd.get_dummies(train_test,columns=['Pclass']) #get_dummies 提供 one-hot编码
train_test.head()
| PassengerId | Survived | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked | Pclass_1 | Pclass_2 | Pclass_3 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 0 | Braund, Mr. Owen Harris | male | 22.0 | 1 | 0 | A/5 21171 | 7.2500 | NaN | S | 0 | 0 | 1 |
| 1 | 2 | 1 | Cumings, Mrs. John Bradley (Florence Briggs Th... | female | 38.0 | 1 | 0 | PC 17599 | 71.2833 | C85 | C | 1 | 0 | 0 |
| 2 | 3 | 1 | Heikkinen, Miss. Laina | female | 26.0 | 0 | 0 | STON/O2. 3101282 | 7.9250 | NaN | S | 0 | 0 | 1 |
| 3 | 4 | 1 | Futrelle, Mrs. Jacques Heath (Lily May Peel) | female | 35.0 | 1 | 0 | 113803 | 53.1000 | C123 | S | 1 | 0 | 0 |
| 4 | 5 | 0 | Allen, Mr. William Henry | male | 35.0 | 0 | 0 | 373450 | 8.0500 | NaN | S | 0 | 0 | 1 |
Sex,性别没有缺失值,直接分列
train_test = pd.get_dummies(train_test,columns=["Sex"])
train_test.head()
| PassengerId | Survived | Name | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked | Pclass_1 | Pclass_2 | Pclass_3 | Sex_female | Sex_male | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 0 | Braund, Mr. Owen Harris | 22.0 | 1 | 0 | A/5 21171 | 7.2500 | NaN | S | 0 | 0 | 1 | 0 | 1 |
| 1 | 2 | 1 | Cumings, Mrs. John Bradley (Florence Briggs Th... | 38.0 | 1 | 0 | PC 17599 | 71.2833 | C85 | C | 1 | 0 | 0 | 1 | 0 |
| 2 | 3 | 1 | Heikkinen, Miss. Laina | 26.0 | 0 | 0 | STON/O2. 3101282 | 7.9250 | NaN | S | 0 | 0 | 1 | 1 | 0 |
| 3 | 4 | 1 | Futrelle, Mrs. Jacques Heath (Lily May Peel) | 35.0 | 1 | 0 | 113803 | 53.1000 | C123 | S | 1 | 0 | 0 | 1 | 0 |
| 4 | 5 | 0 | Allen, Mr. William Henry | 35.0 | 0 | 0 | 373450 | 8.0500 | NaN | S | 0 | 0 | 1 | 0 | 1 |
SibSp and Parch 兄妹配偶数/父母子女数
train_test['SibSp_Parch'] = train_test['SibSp'] + train_test['Parch']
train_test = pd.get_dummies(train_test,columns = ['SibSp','Parch','SibSp_Parch'])
Embarked 数据有极少量(3个)缺失值,但是在分列的时候,缺失值的所有列可以均为0,所以可以考虑不填充.
另外,也可以考虑用测试集众数来填充.先找出众数,再采用df.fillna()方法
train_test = pd.get_dummies(train_test,columns=["Embarked"])
name
在数据的Name项中包含了对该乘客的称呼,将这些关键词提取出来,然后做分列处理.
#从名字中提取出称呼: df['Name].str.extract()是提取函数,配合正则表达式一起使用
train_test['Name1'] = train_test['Name'].str.extract('.+,(.+)', expand=False).str.extract('^(.+?)\.', expand=False).str.strip()
#将姓名分类处理()
train_test['Name1'].replace(['Capt', 'Col', 'Major', 'Dr', 'Rev'], 'Officer' , inplace = True)
train_test['Name1'].replace(['Jonkheer', 'Don', 'Sir', 'the Countess', 'Dona', 'Lady'], 'Royalty' , inplace = True)
train_test['Name1'].replace(['Mme', 'Ms', 'Mrs'], 'Mrs')
train_test['Name1'].replace(['Mlle', 'Miss'], 'Miss')
train_test['Name1'].replace(['Mr'], 'Mr' , inplace = True)
train_test['Name1'].replace(['Master'], 'Master' , inplace = True)
#分列处理
train_test = pd.get_dummies(train_test,columns=['Name1'])
从姓名中提取出姓做特征
#从姓名中提取出姓 存放在新的一列
train_test['Name2'] = train_test['Name'].apply(lambda x: x.split('.')[1])
#计算数量,然后合并数据集
Name2_sum = train_test['Name2'].value_counts().reset_index()
Name2_sum.columns=['Name2','Name2_sum']
train_test = pd.merge(train_test,Name2_sum,how='left',on='Name2')
#由于出现一次时该特征时无效特征,用one来代替出现一次的姓
train_test.loc[train_test['Name2_sum'] == 1 , 'Name2_new'] = 'one'
train_test.loc[train_test['Name2_sum'] > 1 , 'Name2_new'] = train_test['Name2']
del train_test['Name2']
#分列处理
train_test = pd.get_dummies(train_test,columns=['Name2_new'])
#删掉姓名这个特征
del train_test['Name']
fare 该特征有缺失值,先找出缺失值的那调数据,然后用平均数填充
#从上面的分析,发现该特征train集无miss值,test有一个缺失值,先查看
train_test.loc[train_test["Fare"].isnull()]
#票价与pclass和Embarked有关,所以用train分组后的平均数填充
train.groupby(by=["Pclass","Embarked"]).Fare.mean()
Pclass Embarked
1 C 104.718529
Q 90.000000
S 70.364862
2 C 25.358335
Q 12.350000
S 20.327439
3 C 11.214083
Q 11.183393
S 14.644083
Name: Fare, dtype: float64
#用pclass=3和Embarked=S的平均数14.644083来填充
train_test["Fare"].fillna(14.435422,inplace=True)
Ticket该列和名字做类似的处理,先提取,然后分列
#将Ticket提取字符列
#str.isnumeric() 如果S中只有数字字符,则返回True,否则返回False
train_test['Ticket_Letter'] = train_test['Ticket'].str.split().str[0]
train_test['Ticket_Letter'] = train_test['Ticket_Letter'].apply(lambda x:np.nan if x.isnumeric() else x)
train_test.drop('Ticket',inplace=True,axis=1)
#分列,此时nan值可以不做处理
train_test = pd.get_dummies(train_test,columns=['Ticket_Letter'],drop_first=True)
Age
# 统计缺失值个数
# train_test["Age"].isnull().sum()
# 考虑年龄缺失值可能影响死亡情况,数据表明,年龄缺失的死亡率为0.19."""
train_test.loc[train_test["Age"].isnull()]['Survived'].mean()
0.19771863117870722
# 所以用年龄是否缺失值来构造新特征
train_test.loc[train_test["Age"].isnull() ,"age_nan"] = 1
train_test.loc[train_test["Age"].notnull() ,"age_nan"] = 0
train_test = pd.get_dummies(train_test,columns=['age_nan'])
利用其他组特征量,采用机器学习算法来预测Age
#创建没有['Cabin','Survived']的数据集
missing_age = train_test.drop(['Survived','Cabin'],axis=1)
#将Age完整的项作为训练集、将Age缺失的项作为测试集。
missing_age_train = missing_age[missing_age['Age'].notnull()]
missing_age_test = missing_age[missing_age['Age'].isnull()]
#构建训练集合预测集的X和Y值
missing_age_X_train = missing_age_train.drop(['Age'], axis=1)
missing_age_Y_train = missing_age_train['Age']
missing_age_X_test = missing_age_test.drop(['Age'], axis=1)
# 先将数据标准化
from sklearn.preprocessing import StandardScaler
ss = StandardScaler()
#用测试集训练并标准化
ss.fit(missing_age_X_train)
missing_age_X_train = ss.transform(missing_age_X_train)
missing_age_X_test = ss.transform(missing_age_X_test)
#使用贝叶斯预测年龄
from sklearn import linear_model
lin = linear_model.BayesianRidge()
lin.fit(missing_age_X_train,missing_age_Y_train)
BayesianRidge(alpha_1=1e-06, alpha_2=1e-06, compute_score=False, copy_X=True,
fit_intercept=True, lambda_1=1e-06, lambda_2=1e-06, n_iter=300,
normalize=False, tol=0.001, verbose=False)
#利用loc将预测值填入数据集
train_test.loc[(train_test['Age'].isnull()), 'Age'] = lin.predict(missing_age_X_test)
#将年龄划分是个阶段10以下,10-18,18-30,30-50,50以上
train_test['Age'] = pd.cut(train_test['Age'], bins=[0,10,18,30,50,100],labels=[1,2,3,4,5])
train_test = pd.get_dummies(train_test,columns=['Age'])
Cabin
cabin项缺失太多,只能将有无Cain首字母进行分类,缺失值为一类,作为特征值进行建模,也可以考虑直接舍去该特征
#cabin项缺失太多,只能将有无Cain首字母进行分类,缺失值为一类,作为特征值进行建模
#按首字母分类
train_test['Cabin_nan'] = train_test['Cabin'].apply(lambda x:str(x)[0] if pd.notnull(x) else x)
train_test = pd.get_dummies(train_test,columns=['Cabin_nan'])
# Cabin_nan把这列按照有无 设定值
train_test.loc[train_test["Cabin"].isnull() ,"Cabin_nan"] = 1
train_test.loc[train_test["Cabin"].notnull() ,"Cabin_nan"] = 0
train_test = pd.get_dummies(train_test,columns=['Cabin_nan'])
train_test.drop('Cabin',axis=1,inplace=True)
特征工程处理完了,划分数据集
数据规约
- 线性模型需要用标准化的数据建模,而树类模型不需要标准化的数据
- 处理标准化的时候,注意将测试集的数据transform到test集上
train_data = train_test[:891] #取前面原训练集部分的数据
test_data = train_test[891:] #取后面原测试集部分的数据
train_data_X = train_data.drop(['Survived'],axis=1) #删除 Survived 列
train_data_Y = train_data['Survived']
test_data_X = test_data.drop(['Survived'],axis=1)
数据标准化
ss = StandardScaler()
#用测试集训练并标准化
ss.fit(train_data_X)
train_data_X_sd = ss.transform(train_data_X)
ss.fit(test_data_X)
test_data_X_sd = ss.transform(test_data_X)
建立模型
模型发现
1.可选单个模型模型有随机森林,逻辑回归,svm,xgboost,gbdt等.
2.也可以将多个模型组合起来,进行模型融合,比如voting,stacking等方法
3.好的特征决定模型上限,好的模型和参数可以无线逼近上限.
4.我测试了多种模型,模型结果最高的随机森林,最高有0.8.
构建模型
随机森林
from sklearn.ensemble import RandomForestClassifier
rf = RandomForestClassifier(n_estimators=150,min_samples_leaf=3,max_depth=6,oob_score=True)
rf.fit(train_data_X,train_data_Y)
test["Survived"] = rf.predict(test_data_X_sd)
RF = test[['PassengerId','Survived']].set_index('PassengerId')
RF.to_csv('D:\\titanic\\RF.csv')
# 随机森林是随机选取特征进行建模的,所以每次的结果可能都有点小差异
# 如果分数足够好,可以将该模型保存起来,下次直接调出来使用0.81339 'rf10.pkl'
from sklearn.externals import joblib
joblib.dump(rf, 'D:\\titanic\\rf10.pkl') #导出模型
['D:\\titanic\\rf10.pkl']
LogisticRegression
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import GridSearchCV
lr = LogisticRegression()
param = {'C':[0.001,0.01,0.1,1,10], "max_iter":[100,250]}
clf = GridSearchCV(lr, param,cv=5, n_jobs=-1, verbose=1, scoring="roc_auc") # GridSearchCV GridSearch+CV=网格搜索+交叉验证
clf.fit(train_data_X_sd, train_data_Y)
# 打印参数的得分情况 最佳参数
print("Best: %f using %s" % (clf.best_score_,clf.best_params_))
Fitting 5 folds for each of 10 candidates, totalling 50 fits
[Parallel(n_jobs=-1)]: Using backend LokyBackend with 8 concurrent workers.
[Parallel(n_jobs=-1)]: Done 34 tasks | elapsed: 3.0s
Best: 0.869078 using {'C': 0.01, 'max_iter': 100}
[Parallel(n_jobs=-1)]: Done 50 out of 50 | elapsed: 3.6s finished
C:\Anaconda3\lib\site-packages\sklearn\linear_model\logistic.py:432: FutureWarning: Default solver will be changed to 'lbfgs' in 0.22. Specify a solver to silence this warning.
FutureWarning)
将最佳参数传入训练模型 lr = clf.best_estimator_
# 将最佳参数传入训练模型
lr = clf.best_estimator_
lr.fit(train_data_X_sd, train_data_Y)
# 输出结果
test["Survived"] = lr.predict(test_data_X_sd)
test[['PassengerId', 'Survived']].set_index('PassengerId').to_csv('D:\\titanic\\LS5.csv')
joblib.dump(rf, 'D:\\titanic\\LS5.pkl') #导出模型
C:\Anaconda3\lib\site-packages\sklearn\linear_model\logistic.py:432: FutureWarning: Default solver will be changed to 'lbfgs' in 0.22. Specify a solver to silence this warning.
FutureWarning)
['D:\\titanic\\LS5.pkl']
SVM
from sklearn import svm
svc = svm.SVC()
clf = GridSearchCV(svc,param,cv=5,n_jobs=-1,verbose=1,scoring="roc_auc")
clf.fit(train_data_X_sd,train_data_Y)
# 打印参数的得分情况 最佳参数
print("Best: %f using %s" % (clf.best_score_,clf.best_params_))
Fitting 5 folds for each of 10 candidates, totalling 50 fits
[Parallel(n_jobs=-1)]: Using backend LokyBackend with 8 concurrent workers.
[Parallel(n_jobs=-1)]: Done 34 tasks | elapsed: 3.5s
Best: 0.841489 using {'C': 1, 'max_iter': 250}
[Parallel(n_jobs=-1)]: Done 50 out of 50 | elapsed: 3.9s finished
C:\Anaconda3\lib\site-packages\sklearn\model_selection\_search.py:814: DeprecationWarning: The default of the `iid` parameter will change from True to False in version 0.22 and will be removed in 0.24. This will change numeric results when test-set sizes are unequal.
DeprecationWarning)
C:\Anaconda3\lib\site-packages\sklearn\svm\base.py:193: FutureWarning: The default value of gamma will change from 'auto' to 'scale' in version 0.22 to account better for unscaled features. Set gamma explicitly to 'auto' or 'scale' to avoid this warning.
"avoid this warning.", FutureWarning)
C:\Anaconda3\lib\site-packages\sklearn\svm\base.py:241: ConvergenceWarning: Solver terminated early (max_iter=250). Consider pre-processing your data with StandardScaler or MinMaxScaler.
% self.max_iter, ConvergenceWarning)
#将最佳参数模型导入
svc = clf.best_estimator_
# 训练模型并预测结果
svc.fit(train_data_X_sd,train_data_Y)
svc.predict(test_data_X_sd)
# 打印结果
test["Survived"] = svc.predict(test_data_X_sd)
SVM = test[['PassengerId','Survived']].set_index('PassengerId')
SVM.to_csv('D:\\titanic\\svm1.csv')
joblib.dump(rf, 'D:\\titanic\\svm1.pkl') #导出模型
C:\Anaconda3\lib\site-packages\sklearn\svm\base.py:193: FutureWarning: The default value of gamma will change from 'auto' to 'scale' in version 0.22 to account better for unscaled features. Set gamma explicitly to 'auto' or 'scale' to avoid this warning.
"avoid this warning.", FutureWarning)
C:\Anaconda3\lib\site-packages\sklearn\svm\base.py:241: ConvergenceWarning: Solver terminated early (max_iter=250). Consider pre-processing your data with StandardScaler or MinMaxScaler.
% self.max_iter, ConvergenceWarning)
['D:\\titanic\\svm1.pkl']
GBDT
from sklearn.ensemble import GradientBoostingClassifier
gbdt = GradientBoostingClassifier(learning_rate=0.7,max_depth=6,n_estimators=100,min_samples_leaf=2)
gbdt.fit(train_data_X,train_data_Y)
test["Survived"] = gbdt.predict(test_data_X)
test[['PassengerId','Survived']].set_index('PassengerId').to_csv('D:\\titanic\\gbdt3.csv')
joblib.dump(rf, 'D:\\titanic\\gbdt3.pkl') #导出模型
['D:\\titanic\\gbdt3.pkl']
xgboostm
import xgboost as xgb
xgb_model = xgb.XGBClassifier(n_estimators=150,min_samples_leaf=3,max_depth=6)
xgb_model.fit(train_data_X,train_data_Y)
test["Survived"] = xgb_model.predict(test_data_X)
XGB = test[['PassengerId','Survived']].set_index('PassengerId')
XGB.to_csv('D:\\titanic\\XGB5.csv')
joblib.dump(rf, 'D:\\titanic\\XGB5.pkl') #导出模型
['D:\\titanic\\XGB5.pkl']
建立模型
模型融合 voting
Voting即投票机制,分为软投票和硬投票两种,其原理采用少数服从多数的思想。
硬投票:对多个模型直接进行投票,最终投票数最多的类为最终被预测的类。
软投票:和硬投票原理相同,增加了设置权重的功能,可以为不同模型设置不同权重,进而区别模型不同的重要度。
备注:此方法用于解决分类问题。
from sklearn.ensemble import VotingClassifier
from sklearn.linear_model import LogisticRegression
lr = LogisticRegression(C=0.1,max_iter=100)
import xgboost as xgb
xgb_model = xgb.XGBClassifier(max_depth=6,min_samples_leaf=2,n_estimators=100,num_round = 5)
from sklearn.ensemble import RandomForestClassifier
rf = RandomForestClassifier(n_estimators=200,min_samples_leaf=2,max_depth=6,oob_score=True)
from sklearn.ensemble import GradientBoostingClassifier
gbdt = GradientBoostingClassifier(learning_rate=0.1,min_samples_leaf=2,max_depth=6,n_estimators=100)
vot = VotingClassifier(estimators=[('lr', lr), ('rf', rf),('gbdt',gbdt),('xgb',xgb_model)], voting='hard')
vot.fit(train_data_X_sd,train_data_Y)
test["Survived"] = vot.predict(test_data_X_sd)
test[['PassengerId','Survived']].set_index('PassengerId').to_csv('D:\\titanic\\vot5.csv')
joblib.dump(rf, 'D:\\titanic\\vot5.pkl') #导出模型
C:\Anaconda3\lib\site-packages\sklearn\linear_model\logistic.py:432: FutureWarning: Default solver will be changed to 'lbfgs' in 0.22. Specify a solver to silence this warning.
FutureWarning)
['D:\\titanic\\vot5.pkl']
模型融合 stacking
stacking是一种分层模型集成框架。
以两层为例,第一层由多个基学习器组成,其输入为原始训练集,第二层的模型则是以第一层基学习器的输出作为训练集进行再训练,从而得到完整的stacking模型。
stacking两层模型都使用了全部的训练数据。
# 划分train数据集,调用代码,把数据集名字转成和代码一样
X = train_data_X_sd
X_predict = test_data_X_sd
y = train_data_Y
# 模型融合中使用到的各个单模型
from sklearn.linear_model import LogisticRegression
from sklearn import svm
import xgboost as xgb
from sklearn.ensemble import RandomForestClassifier
from sklearn.ensemble import GradientBoostingClassifier
clfs = [LogisticRegression(C=0.1,max_iter=100),
xgb.XGBClassifier(max_depth=6,n_estimators=100,num_round = 5),
RandomForestClassifier(n_estimators=100,max_depth=6,oob_score=True),
GradientBoostingClassifier(learning_rate=0.3,max_depth=6,n_estimators=100)]
# 创建n_folds
from sklearn.model_selection import StratifiedKFold
n_folds = 5
skf = list(StratifiedKFold(n_splits=n_folds).split(X,y))
# 创建零矩阵
dataset_blend_train = np.zeros((X.shape[0], len(clfs)))
dataset_blend_test = np.zeros((X_predict.shape[0], len(clfs)))
# 建立模型
for j, clf in enumerate(clfs):
# 依次训练各个单模型
# print(j, clf)
dataset_blend_test_j = np.zeros((X_predict.shape[0], len(skf)))
for i, (train, test) in enumerate(skf):
#、使用第i个部分作为预测,剩余的部分来训练模型,获得其预测的输出作为第i部分的新特征。
# print("Fold", i)
X_train, y_train, X_test, y_test = X[train], y[train], X[test], y[test]
clf.fit(X_train, y_train)
y_submission = clf.predict_proba(X_test)[:, 1]
dataset_blend_train[test, j] = y_submission
dataset_blend_test_j[:, i] = clf.predict_proba(X_predict)[:, 1]
# 对于测试集,直接用这k个模型的预测值均值作为新的特征。
dataset_blend_test[:, j] = dataset_blend_test_j.mean(1)
# 用建立第二层模型
clf2 = LogisticRegression(C=0.1,max_iter=100)
clf2.fit(dataset_blend_train, y)
y_submission = clf2.predict_proba(dataset_blend_test)[:, 1]
test = pd.read_csv("D:\\titanic\\test.csv")
test["Survived"] = clf2.predict(dataset_blend_test)
test[['PassengerId','Survived']].set_index('PassengerId').to_csv('D:\\titanic\\stack3.csv')
joblib.dump(rf, 'D:\\titanic\\stack3.pkl') #导出模型
C:\Anaconda3\lib\site-packages\sklearn\linear_model\logistic.py:432: FutureWarning: Default solver will be changed to 'lbfgs' in 0.22. Specify a solver to silence this warning.
FutureWarning)
C:\Anaconda3\lib\site-packages\sklearn\linear_model\logistic.py:432: FutureWarning: Default solver will be changed to 'lbfgs' in 0.22. Specify a solver to silence this warning.
FutureWarning)
C:\Anaconda3\lib\site-packages\sklearn\linear_model\logistic.py:432: FutureWarning: Default solver will be changed to 'lbfgs' in 0.22. Specify a solver to silence this warning.
FutureWarning)
C:\Anaconda3\lib\site-packages\sklearn\linear_model\logistic.py:432: FutureWarning: Default solver will be changed to 'lbfgs' in 0.22. Specify a solver to silence this warning.
FutureWarning)
C:\Anaconda3\lib\site-packages\sklearn\linear_model\logistic.py:432: FutureWarning: Default solver will be changed to 'lbfgs' in 0.22. Specify a solver to silence this warning.
FutureWarning)
C:\Anaconda3\lib\site-packages\sklearn\linear_model\logistic.py:432: FutureWarning: Default solver will be changed to 'lbfgs' in 0.22. Specify a solver to silence this warning.
FutureWarning)
['D:\\titanic\\stack3.pkl']


 浙公网安备 33010602011771号
浙公网安备 33010602011771号