回归评价指标MSE、RMSE、MAE、R-Squared
简书 原作者 skullfang https://www.jianshu.com/p/9ee85fdad150
https://blog.csdn.net/zrh_CSDN/article/details/81190001
分类问题的评价指标是准确率,那么回归算法的评价指标就是MSE,RMSE,MAE、R-Squared
1.均方误差(MSE)
MSE (Mean Squared Error)叫做均方误差。看公式
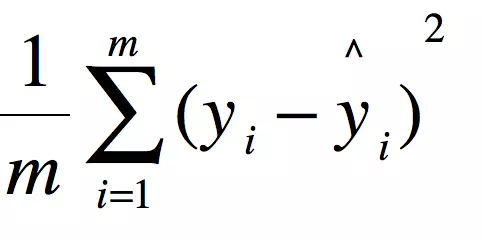
这里的两个y分别是 真实值 和 测试集 上的 预测值 。
用 真实值-预测值 然后 平方 之后 求和 平均。
就是线性回归的损失函数!! 在线性回归的时候我们的目的就是让这个损失函数最小。那么模型做出来了,我们把损失函数丢到测试集上去看看损失值不就好了嘛。
2.均方根误差(RMSE)
RMSE(Root Mean Squard Error)均方根误差。
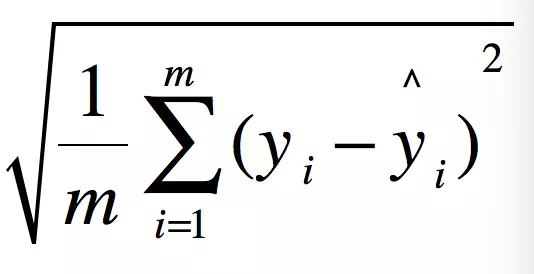
就是MSE开个根号么。实质是一样的。只不过用于数据更好的描述。
例如:要做房价预测,每平方是万元,我们预测结果也是万元。那么差值的平方单位应该是 千万级别的。不利于描述。开完根号 就是一个数量级别的了。
MAE(平均绝对误差)
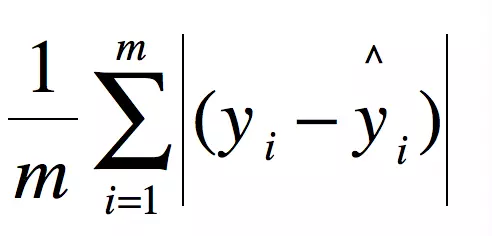
R Squared
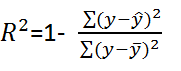
上式中,分子部分表示真实值与预测值的平方差之和,类似于均方差 MSE;分母部分表示真实值与均值的平方差之和,类似于方差 Var。根据 R-Squared 的取值,来判断模型的好坏:如果结果是 0,说明模型拟合效果很差;如果结果是 1,说明模型无错误。一般来说,R-Squared 越大,表示模型拟合效果越好。R-Squared 反映的是大概有多准,因为,随着样本数量的增加,R-Square必然增加,无法真正定量说明准确程度,只能大概定量。
某些情况下,单独看 R-Squared,并不能推断出增加的特征是否有意义。通常来说,增加一个特征,R-Squared 可能变大也可能保持不变,两者不一定呈正相关。
如果使用校正决定系数(Adjusted R-Square):
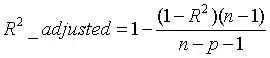
其中,n 是样本数量,p 是特征数量。Adjusted R-Square 抵消样本数量对 R-Square的影响,做到了真正的 0~1,越大越好。
各种评价指标 scikit-learn中的写法
from sklearn.metrics import mean_squared_error #均方误差
from sklearn.metrics import mean_absolute_error #平方绝对误差
from sklearn.metrics import r2_score#R square
#调用
mean_squared_error(y_test,y_predict)
mean_absolute_error(y_test,y_predict)
r2_score(y_test,y_predict)


 浙公网安备 33010602011771号
浙公网安备 33010602011771号