
统计学知识笔记
统计和概率
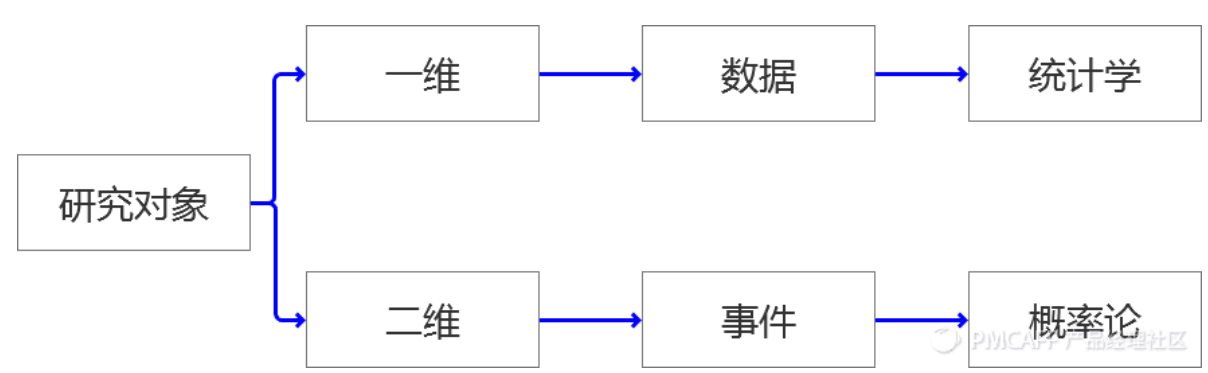
一维:就是当前摆在我们面前的“一组”,“一批”,哪怕是“一坨”数据。这里我们会用到统计学的知识去研究这类对象。
二维:就是研究某个“事件”,笔者认为事件是依托于“时间轴”存在的,过去是否发生,现在是可能会出现几种情况,每种情况未来发生的可能性有多大?这类问题是属于概率论的范畴。
分析:
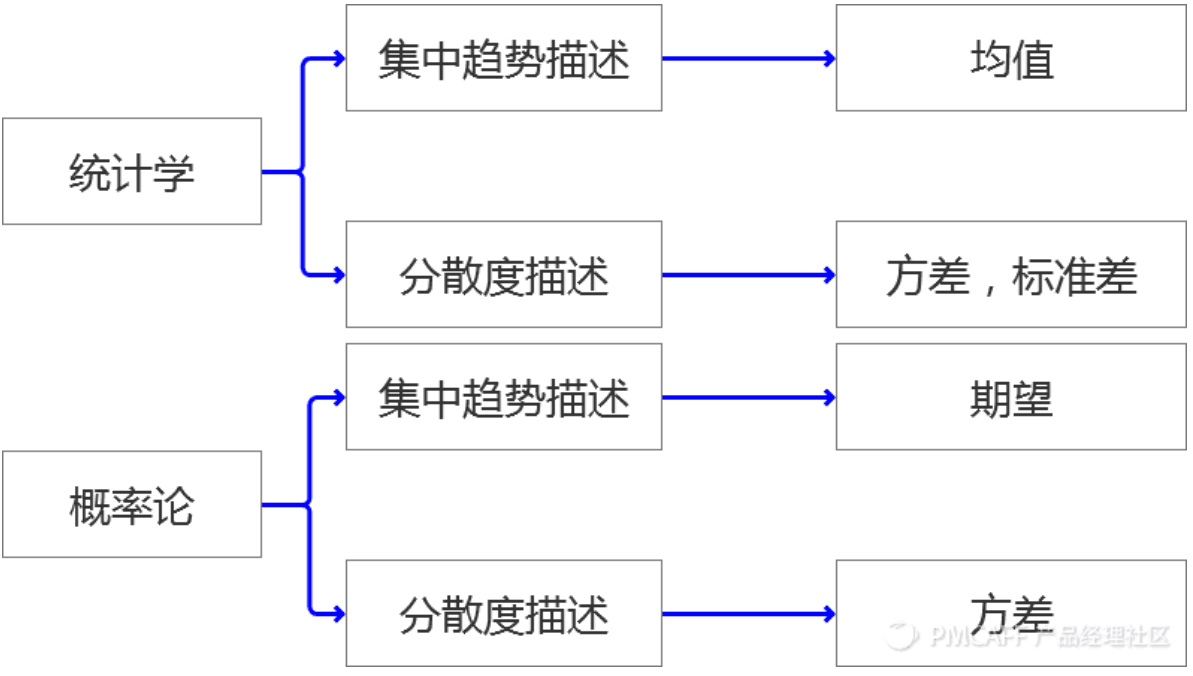
第一部分对“数据”的描述性分析
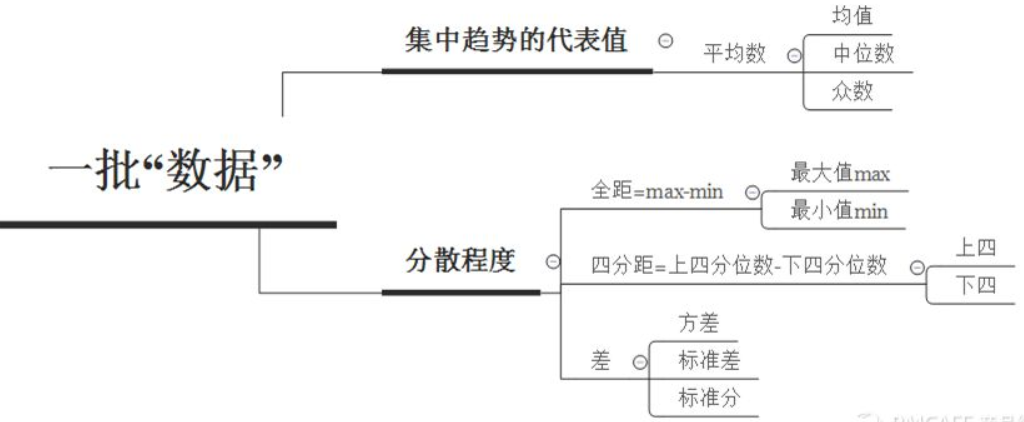
集中趋势量度:为这批数据找到它们的“代表”:
- 均值 的局限性:数据中存在异常值的情况,会产生偏差
- 中位数,又称中点数,中值。是按顺序排列的一组数据中居于中间位置的数。
- 众数,是样本观测值在频数分布表中频数最多的那一组的组中值。
分散性与变异性的量度
全距=max-min 全距也叫“极差”极差。它是一组数据中最大值与最小值之差。可以用于度量数据的分散程度。
四分位数,所有观测值从小到大排序后四等分,处于三个分割点位置的数值就是四分位数:Q1,Q2和Q3。
- Q1:第一四分位数 (Q1),又称“较小四分位数”,等于该样本中所有数值由小到大排列后第25%的数字。
- Q2:第二四分位数 (Q2),又称“中位数”,等于该样本中所有数值由小到大排列后第50%的数字。
- Q3:第三四分位数 (Q3),又称“较大四分位数”,等于该样本中所有数值由小到大排列后第75%的数字。
迷你距 也叫“四分位距”:它是一组数据中较小四分位数与较大四分位数之差。即:迷你距= 上四分位数 - 下四分位数。反映中间50%的数据。如果出现了极大或极小的异常值,将会被排除在中心数据50%以外。因此使用迷你距可以剔除数据中异常值。
全距,四分位距,箱形图可以表征一组数据极大和极小值之间的差值跨度,一定程度上反应了数据的分散程度,但是却无法精准的告诉我们,这些数值具体出现的频率,那么我们该如何表征呢?
我们度量每批数据中数值的“变异”程度时,可以通过观察每个数据与均值的距离来确定,各个数值与均值距离越小,变异性越小数据越集中,距离越大数据约分散,变异性越大。方差和标准差就是这么一对儿用于表征数据变异程度的概念。
方差 是数值与均值的距离 的平方数 的平均值。
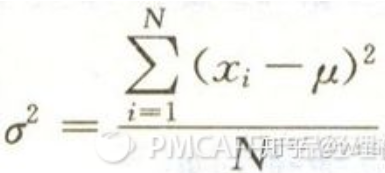
标准差 为方差的开方。
标准分——表征了距离均值的标准差的个数(倍数)。
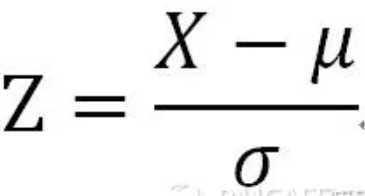
标准分为我们提供了解决方法,当比较均值和标准差各不相同的数据集时,我们可以把这些数值视为来自同一个标准的数据集,然后进行比较。标准分将把每一个数据集转化为通用的分布形态,进行比较。
第一部分小节
-
描述一批数据,通过集中趋势分析,找出其“代表值” ;通过分散和变异性的描述,查看这批数据的分散程度。
-
集中趋势参数:均值,中位数,众数
-
分散性和变异性参数 : 全距,四分位距,方差,标准差,标准分
第二部分 关于“事件”的研究分析概率论
概率论中最核心的概念以及概念之间彼此的关系
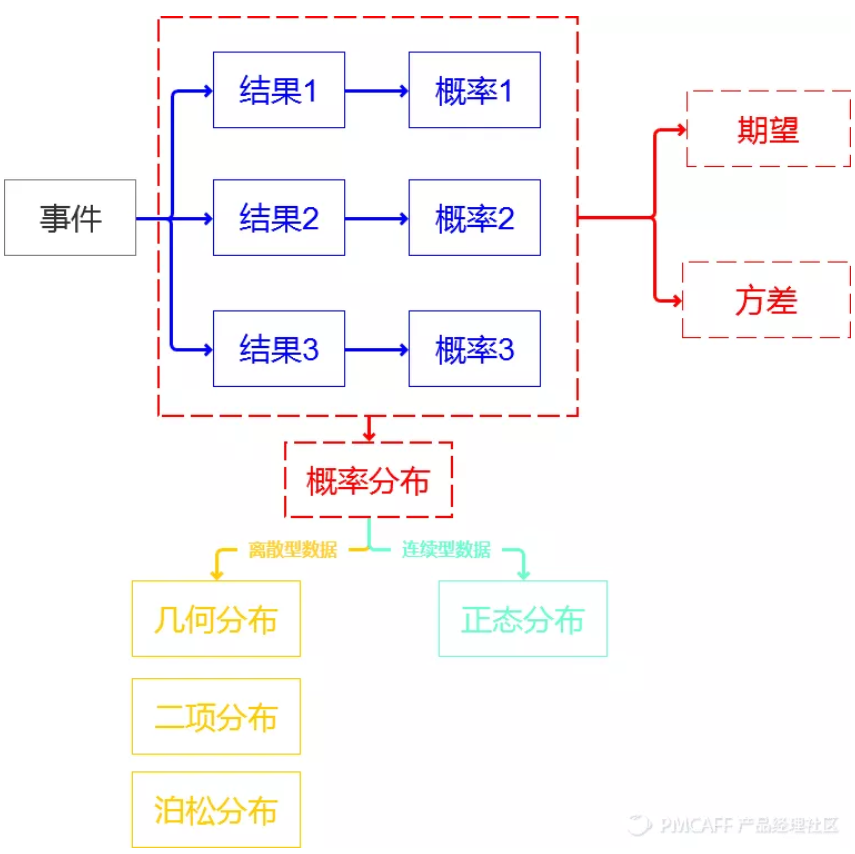
事件:有概率可言的一件事情,一个事情可能会发生很多结果,结果和结果之间要完全穷尽,相互独立。
概率:每一种结果发生的可能性。所有结果的可能性相加等于1,也就是必然!!!
概率分布:我们把事件和事件所对应的概率组织起来,就是这个事件的概率分布。
概率分布可以是图象,也可以是表格。如下图1和表2都可以算是概率分布
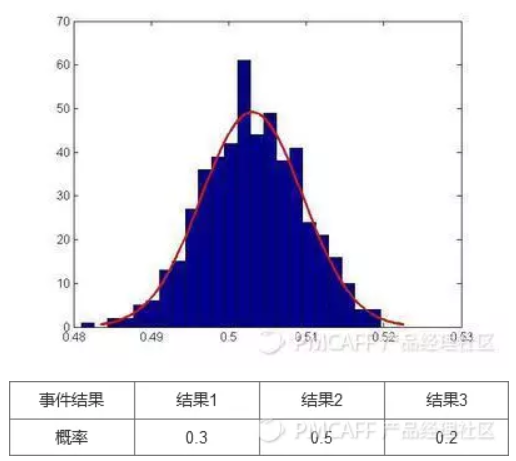
期望:表征了综合考虑事情的各种结果和结果对应的概率后这个事情的综合影响值。(一个事件的期望,就是代表这个事件的“代表值”,类似于统计里面的均值)
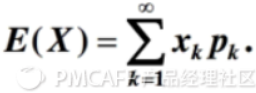
方差:表征了事件不同结果之间的差异或分散程度。
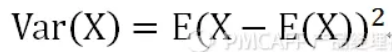
细说分布
真实的生活中别说去算一个事件的期望,即使把这个事件的概率分布能够表述完整,每个事件对应的概率值得出来就已经是一件了不起的事情了。
因此,为了能更快更准确的求解出事件的概率分布,当某些事件,满足某些特定的条件,那么我们可以直接根据这些条件,来套用一些固定的公式,来求解这些事件的分布,期望以及方差。
“离散型”数据和“连续性”数据差异:
离散数据: 一个粒儿,一个粒儿的数据就是离散型数据。
连续数据: 一个串儿,一个串儿的数据就是连续型数据。
离散型和连续型数据是一对相对概念,同样的数据既可能是离散型数据,又可能是连续型数据。
判别一个数据是连续还是离散最本质的因素在于,一个数据组中数据总体的量级和数据粒度之间的差异。差异越大越趋近于连续型数据,差异越小越趋近于离散型数据。
离散型分布
离散数据的概率分布,就是离散分布。这三类离散型的分布,在“0-1事件”中可以采用,就是一个事只有成功和失败两种状态。

连续型分布
连续型分布本质上就是求连续的一个数据段概率分布。
正态分布
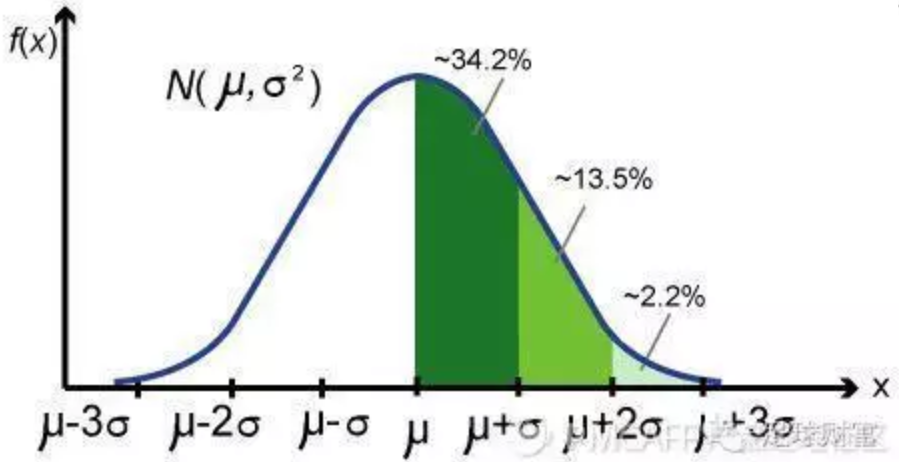
- f(x)----是该关于事件X的概率密度函数
- μ --- 均值
- σ^2 ---方差
- σ ---标准差
- 绿色区域的面积 ---该区间段的概率
正态分布概率的求法
step1 --- 确定分布和范围 ,求出均值和方差
step2 --- 利用标准分将正态分布转化为标准正态分布 (还记得 第一部分的标准分吗?)
step3 ---查表找概率
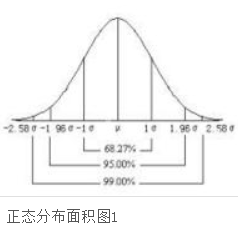
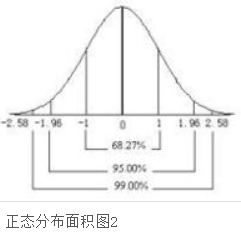
正态分布的那三个数是:99.74%、95.45%、68.27%。
标准正态分布是一个在数学、物理及工程等领域都非常重要的概率分布,在统计学的许多方面有着重大的影响力。期望值μ=0,即曲线图象对称轴为Y轴,标准差σ=1条件下的正态分布,记为N(0,1)。
正态分布在横轴区间(μ-σ,μ+σ)内的面积为68.268949%,横轴区间(μ-1.96σ,μ+1.96σ)内的面积为95.449974%,横轴区间(μ-2.58σ,μ+2.58σ)内的面积为99.730020%。也就是说在这三个置信区间内的概率分别是68.27%、95.45%、99.74%。
多个事件的情况:“概率树”和“贝叶斯定理”
对立事件:如果一个事件,A’包含所有A不包含的可能性,那么我们称A’和A是互为对立事件
穷尽事件:如何A和B为穷尽事件,那么A和B的并集为1
互斥事件:如何A和B为互斥事件,那么A和B没有任何交集
独立事件:如果A件事的结果不会影响B事件结果的概率分布那么A和B互为独立事件。
例子:10个球,我随机抽一个,放回去还是10个球,第二次随机抽,还是10选1,那么第一次和第二次抽球的事件就是独立的。
相关事件:如果A件事的结果会影响B事件结果的概率分布那么A和B互为独立事件。
条件概率(条件概率,概率树,贝叶斯公式)
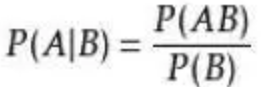
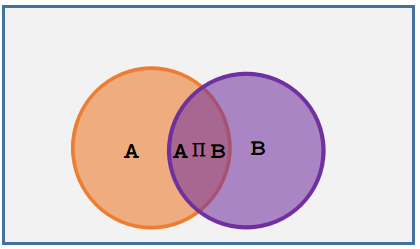
条件概率代表:已知B事件发生的条件下,A事件发生的概率
概率树 --- 一种描述条件概率的图形工具。
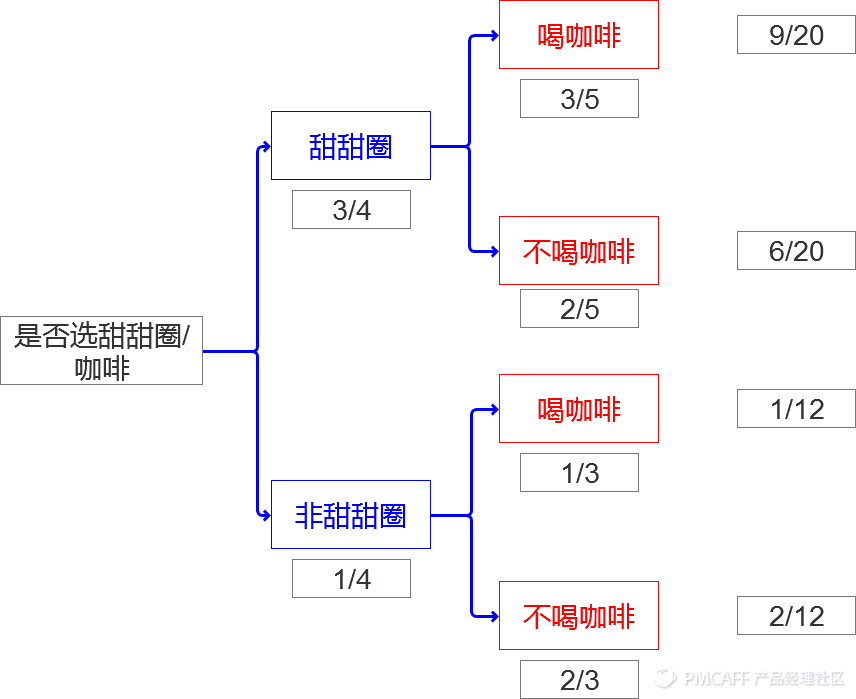
假设有个甜品店,顾客买甜甜圈的概率是3/4 ;不买甜甜圈直接买咖啡的概率是1/3 ;同时买咖啡和甜甜圈概率是9/20。
从图中我们可以发现以下两个信息
1. 顾客买不买甜甜圈可以影响喝不喝咖啡的概率,所以事件甜甜圈与事件咖啡是一组相关事件
2. 概率树每个层级分支的概率和都是1
贝叶斯公式 ----提供了一种计算逆条件概率的方法
贝叶斯公式用于以下场景,当我们知道A发生的前提下B发生的概率,我们可以用贝叶斯公式来推算出B发生条件下A发生的概率。
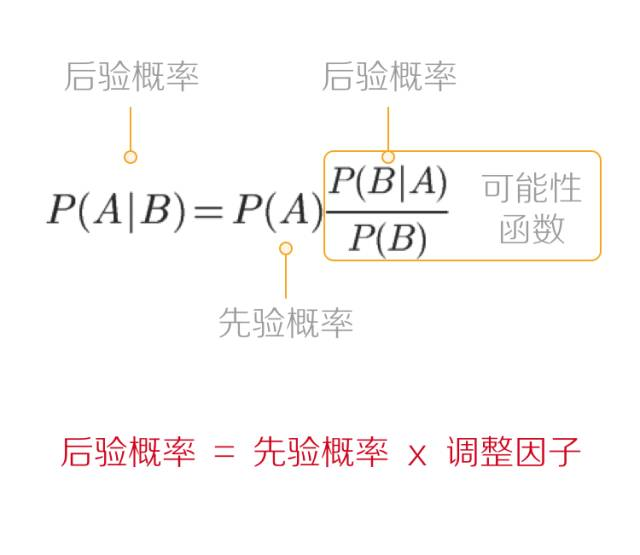
重点是 公式怎么记住!!! AB AB AB
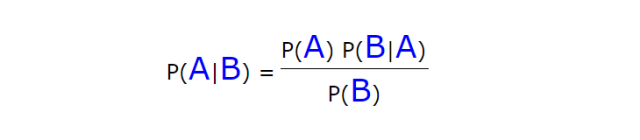
第二部分小节
1. 事件,概率,概率分布之间的关系
2. 期望,方差的意义
3. 连续型数据和离散型数据之间的区别和联系
4. 几何分布,二项分布,泊松分布,正态分布,标准正态分布
5. 离散分布和正态分布可以转化
6. 多个事件之间的关系,相关事件和独立事件,条件概率和贝叶斯公式
第三部分 关于“小样本”预测“大总体”
现实生活中,总体的数量如果过于庞大我们无法获取总体中每个数据的数值,进行对总体的特征提取进而完成分析工作。

1、抽取样本
总体:你研究的所有事件的集合
样本:总体中选取相对较小的集合,用于做出关于总体本身的结论
偏倚:样本不能代表目标总体,说明该样本存在偏倚
简单随机抽样: 随机抽取单位形成样本。
分成抽样: 总体分成几组或者几层,对每一层执行简单随机抽样
系统抽样:选取一个参数K,每到第K个抽样单位,抽样一次。
2、预测总体(点估计预测,区间估计预测)
点估计量--- 一个总参数的点估计量就是可用于估计总体参数数值的某个函数或算式。
场景1: 样本无偏的情况下,已知样本,预测总体的均值,方差。
(1) 样本的均值 = 总体的估算均值(总体均值的点估计量) ≈ 总体实际均值(误差是否可接受)
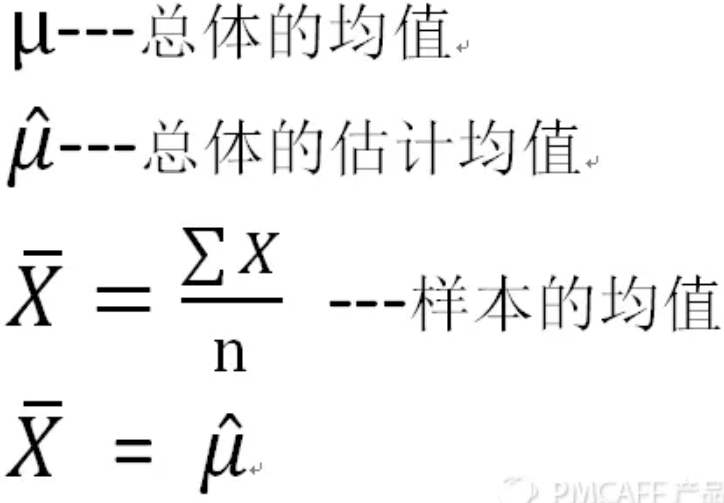
(2)总体方差 估计总体方差
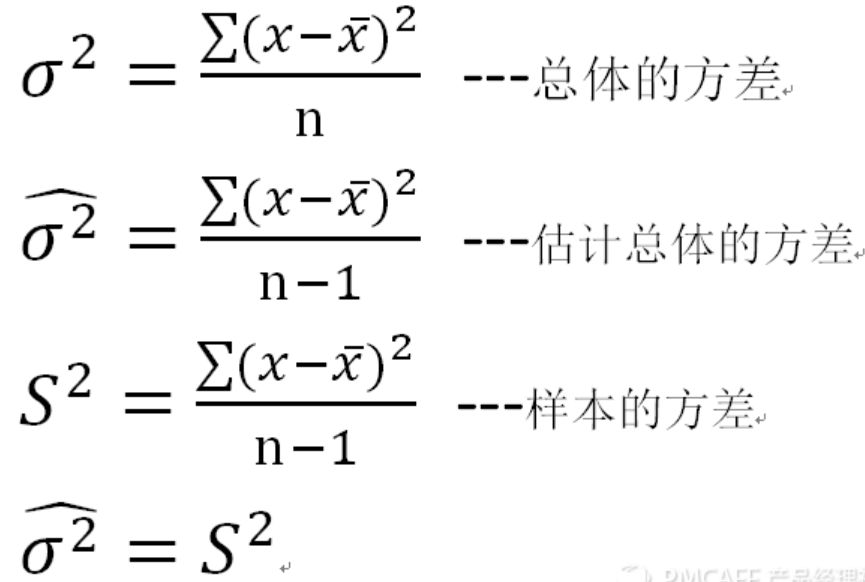
场景2:已知总体,研究抽取样本的概率分布
比例抽样分布:考虑从同一个总体中取得所有大小为n的可能样本,由这些样本的比例形成一个分布,这就是“比例抽样分布”。样本的比例就是随机变量。
举个栗子:已知所有的糖球(总体)中红色糖球比例为0.25。从总体中随机抽n个糖球,我们可以求用比例抽样分布求出这n个糖球中对应红球各种可能比例的概率。

样本均值分布:考虑同一个总体中所有大小为n的可能样本,然后用这个样本的均值形成分布,该分布就是“样本均值分布” ,样本的均值就是随机变量。
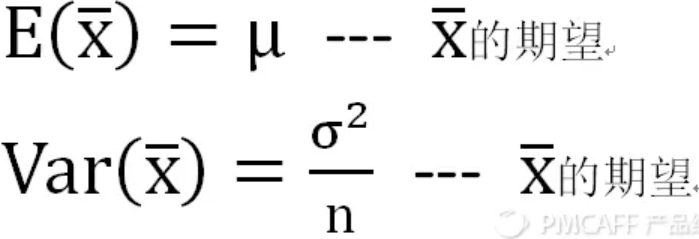
中心极限定理:如果从一个非正态总体X中抽出一个样本,且样本极大(至少大于30),则样本的分布近似正态分布。
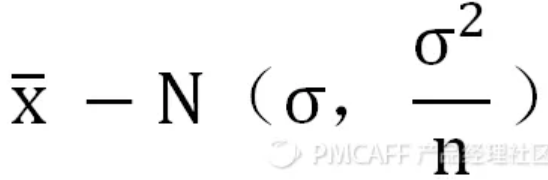
区间估计量:点估计量是利用一个样本对总体进行估计,区间估计是利用样本组成的一段区间对样本进行估计。
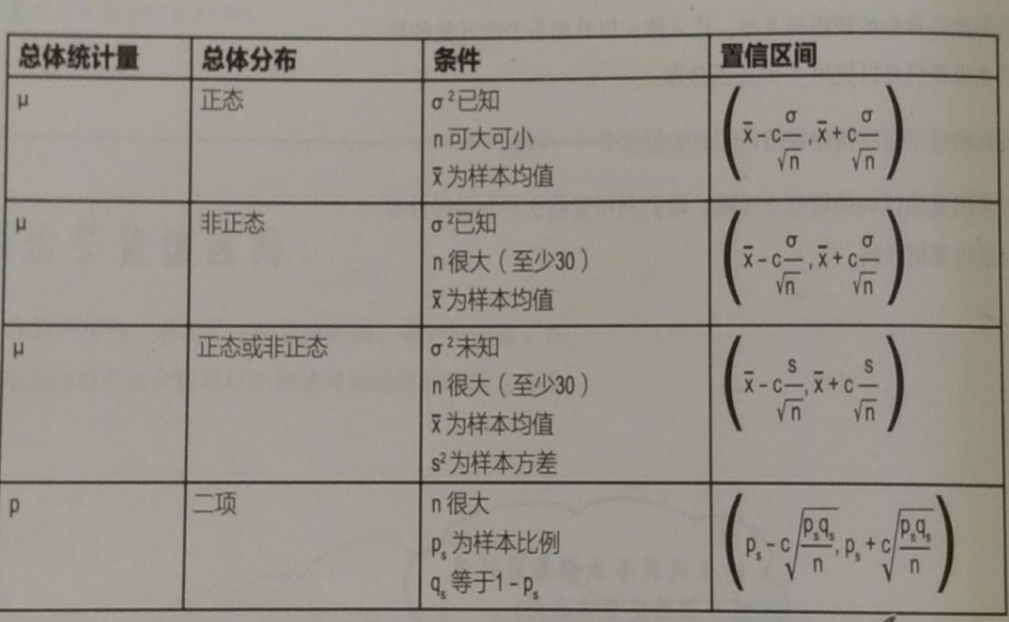
区间估计(interval estimation)是从点估计值和抽样标准误差出发,按给定的概率值建立包含待估计参数的区间。其中这个给定的概率值称为置信度或置信水平(confidence level),这个建立起区间估计来的包含待估计参数的区间称为置信区间(confidence interval),指总体参数值落在样本统计值某一区内的概率;而置信区间是指在某一置信水平下,样本统计值与总体参数值间误差范围。置信区间越大,置信水平越高。划定置信区间的两个数值分别称为置信下限(lower confidence limit,lcl)和置信上限(upper confidence limit,ucl)
如何求置信区间?

求置信区间简便公式
关于C值参数:置信水平 90% C=1.64 , 95% C=1.96 , 99% C=2.58
t分布
我们之前的区间预测有个前提,就是利用了中心极限定理,当样本量足够大的时候(通常大于30),均值抽样分布近似于正态分布。若样本量不够大呢?这是同样的思路,只是样本均值分布将近似于另一种分布处理更加准确,那就是t分布。
3验证结果(假设检验)
假设检验是一种方法用于验证结果是否真实可靠。具体操作分为六个步骤。

两类错误---即使我们进行了“假设检验”依然无法保证决策是百分百正确的,会出现两类错误
第一类错误: 拒绝了一个正确的假设,错杀了一个好人
第二类错误:接收了一个错误的假设,放过了一个坏人
第三部分小节
1. 无偏抽样
2. 点估计量预测(已知样本预测总体,已知总体预测样本)
3. 区间估计量预测(求置信区间)
4. 假设检验


 浙公网安备 33010602011771号
浙公网安备 33010602011771号