一句话理解nlp
词向量?
词向量指的是一组用来表示单词的低纬稠密向量,这里的低纬稠密是和onehot的高维稀疏对应的。
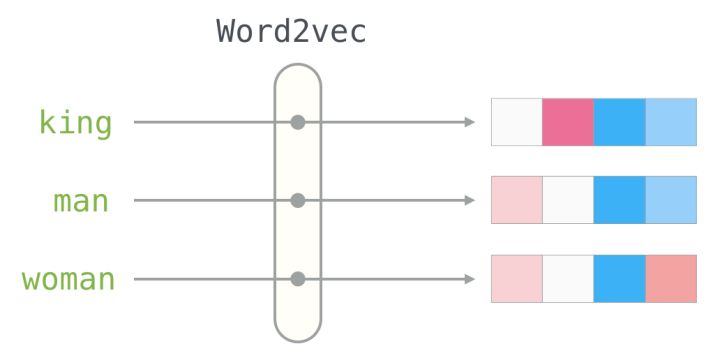
词向量顾名思义, 也就是把每个词(w)用一个固定维度的向量(V)来表示
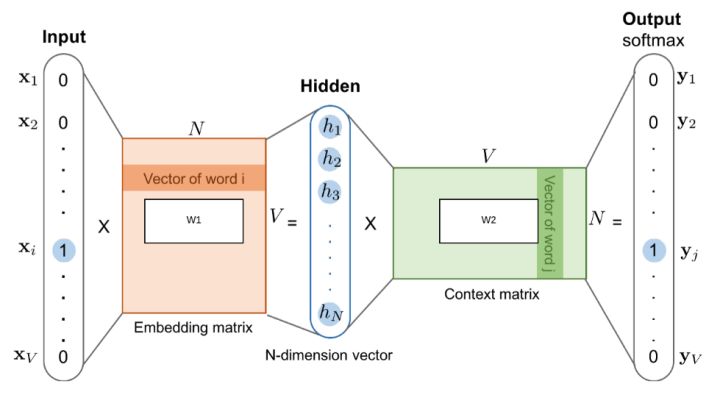
从网络结构和线性代数来看: 词向量是通过, 对词的encoding 点乘 上 Embedding Matrix (图二中的hidden layer).
预训练模型是指一个训练好的 Embedding Matrix. 而通过这个举证, 把所有的 x 映射出来, 就是词向量的结果
什么是 token embedding?
输入一个word,在字典里查找得到它对应的下标就是token,然后用该数字下标去lookup表查找得到该词对应的词向量(词嵌入)就是embedding
word2vec
Word2vec使用两层神经网络结构来为大量文本数据的语料库生成单词的分布式表达,并在数百维向量空间中表达每个单词的特征。
在该向量空间中,假设在语料库中共享公共上下文的词彼此相似,并且将向量分配给这些词,以使它们在向量空间中彼此接近。
2013年,Google开源了一款用于词向量计算的工具——word2vec。
首先,word2vec可以在百万数量级的词典和上亿的数据集上进行高效地训练;
其次,该工具得到的训练结果——词向量(word embedding),可以很好地度量词与词之间的相似性。
2013年,Mikolov等人提出了word2vec工具,其中包含了CBOW(Continue Bag of Words)模型和Skip-gram模型[2-3],该工具仅仅利用海量的单语数据,通过无监督的方法训练得到词嵌入。
Word2vec(Mikolov et al.2013)是用于学习单词向量的框架。想法:
-
我们有大量的语料库;
-
固定词汇表中的每个单词都由一个向量表示;
-
遍历文本中的每个位置t,该位置具有中心词c和上下文(“outside”)词o;
-
使用c和o的词向量的相似度来计算o给定c的概率(反之亦然);
- 不断调整单词向量以最大程度地提高这种可能性。
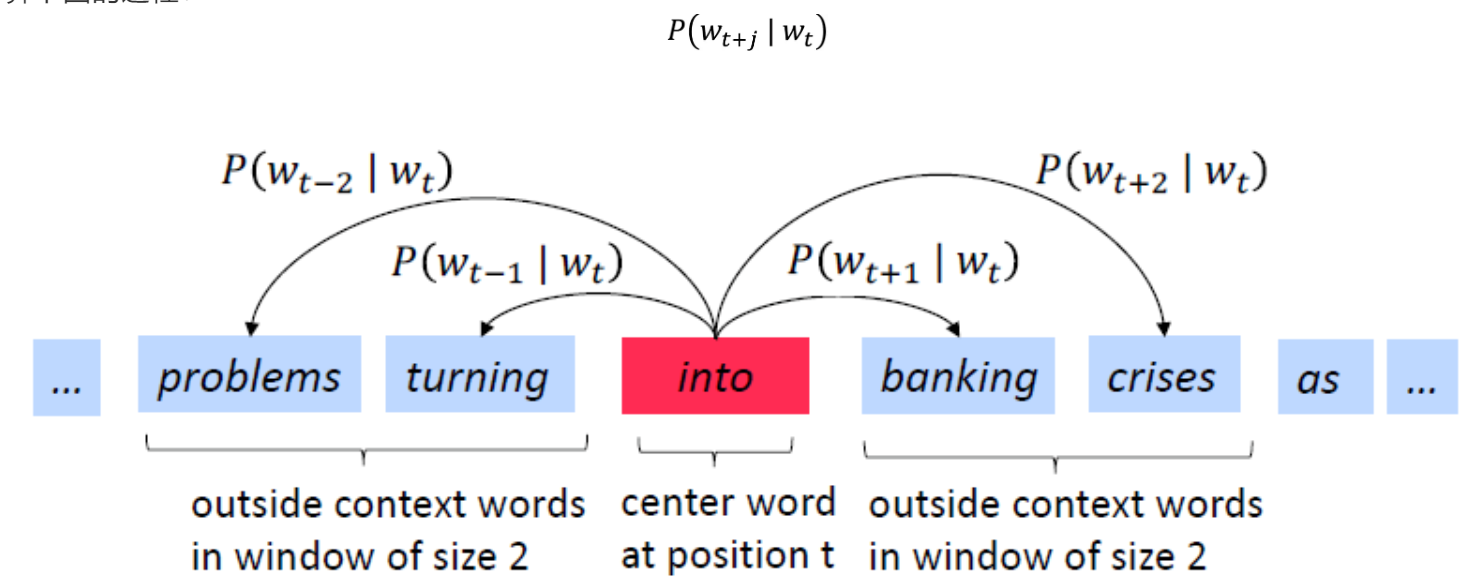
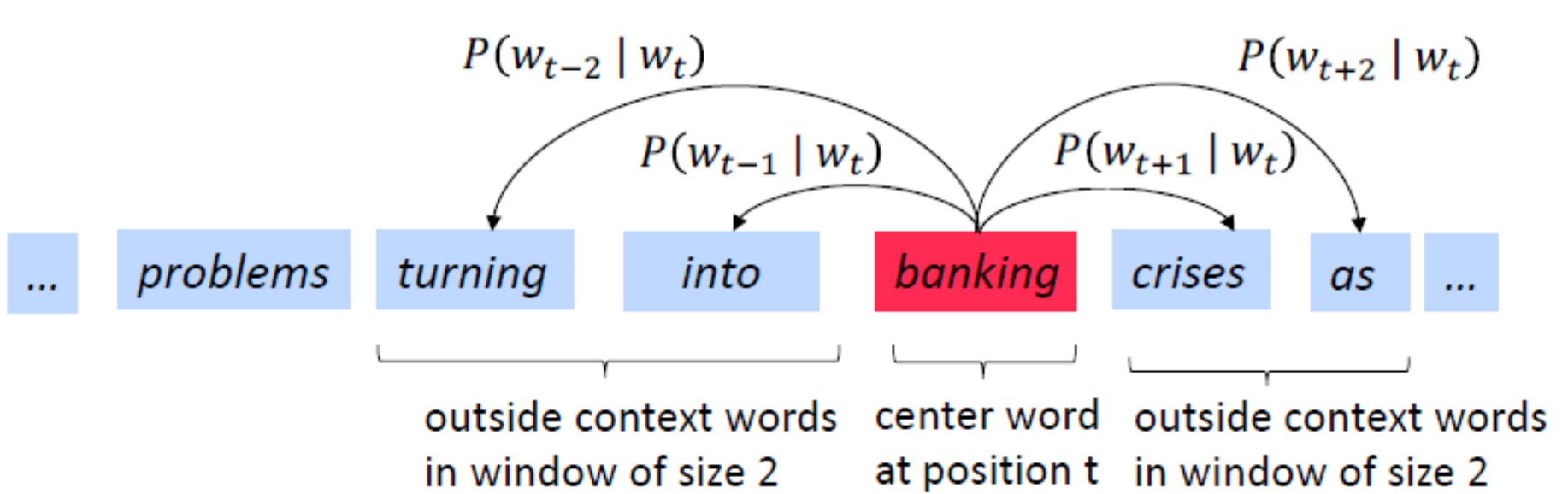
随着深度学习(Deep Learning)在自然语言处理中应用的普及,很多人误以为word2vec是一种深度学习算法。其实word2vec算法的背后是一个浅层神经网络。另外需要强调的一点是,word2vec是一个计算word vector的开源工具。当我们在说word2vec算法或模型的时候,其实指的是其背后用于计算word vector的CBoW模型和Skip-gram模型。很多人以为word2vec指的是一个算法或模型,这也是一种谬误。
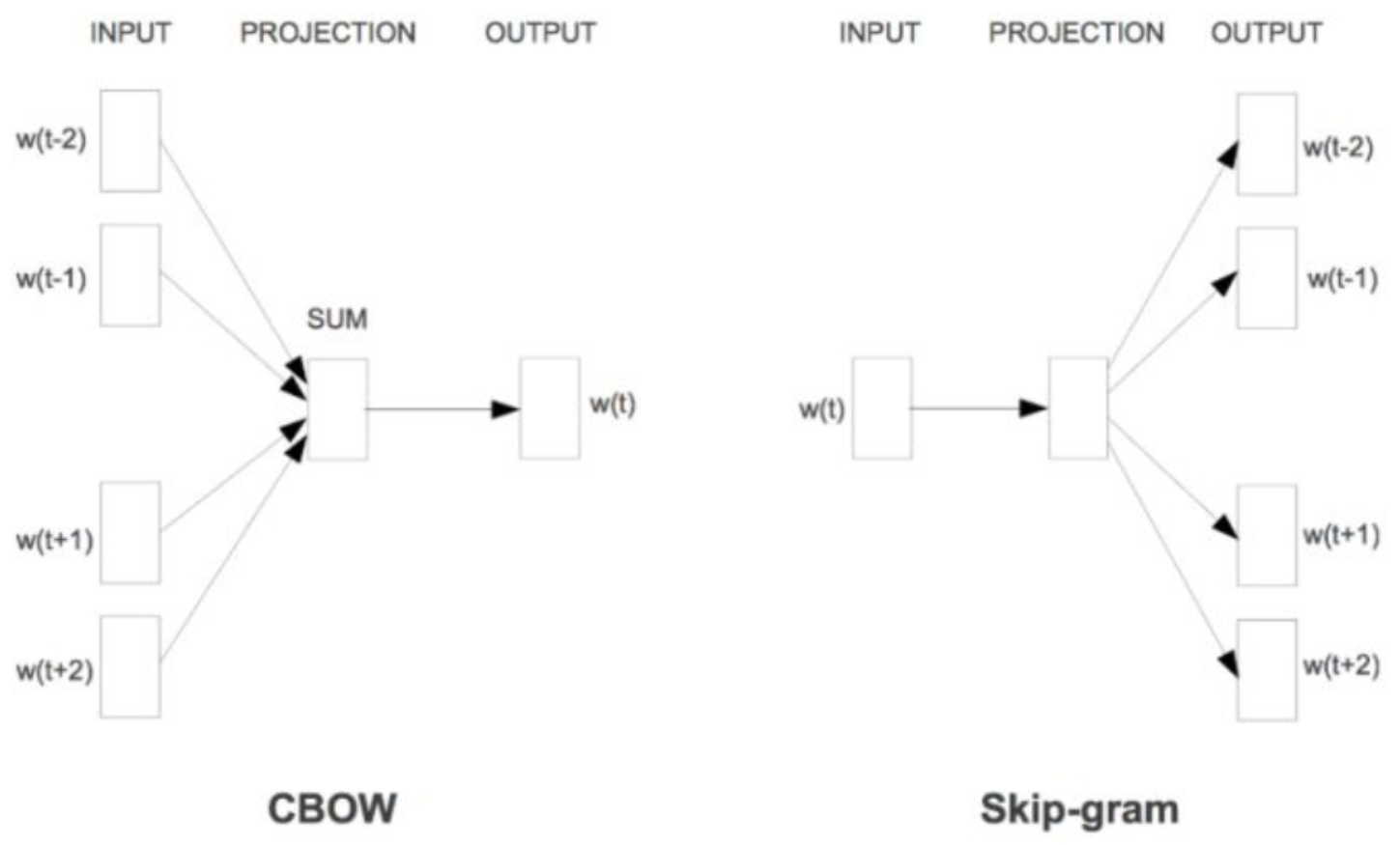
什么是cbow
输入是某一个特征词的上下文相关的词对应的词向量,而输出就是这特定的一个词的词向量,即先验概率。
什么是skip-gram
Skip-Gram模型和CBOW的思路是反着来的,即输入是特定的一个词的词向量,而输出是特定词对应的上下文词向量,即后验概率。
词袋模型(Bag of Words, BOW)
词袋模型就是将句子分词,然后对每个词进行编码,常见的有one-hot、TF-IDF、Huffman编码,假设词与词之间没有先后关系。
词向量(Word Embedding)模型
词向量模型是用词向量在空间坐标中定位,然后计算cos距离可以判断词于词之间的相似性。
Embedding
是一个将离散变量转为连续向量表示的一个方式
embedding 有以下 3 个主要目的:
- 在 embedding 空间中查找最近邻,这可以很好的用于根据用户的兴趣来进行推荐。
- 作为监督性学习任务的输入。
- 用于可视化不同离散变量之间的关系。
这也就意味对于上面我们所说的维基百科书籍表示而言,使用 Neural Network Embedding,我们可以在维基百科上获取到的所有 37,000 本书,对于每一篇,仅仅用一个包含 50 个数字的向量即可表示。此外,因为 embedding 是可学习的,因此在不断的训练过程中,更相似的书籍的表示在 embedding space 中将彼此更接近。
总结
Embedding 的价值并不仅仅在于 word embedding 或者 entity embedding,这种将类别数据用低维表示且可自学习的思想更存在价值。通过这种方式,我们可以将神经网络,深度学习用于更广泛的领域,Embedding 可以表示更多的东西,而这其中的关键在于要想清楚我们需要解决的问题和应用 Embedding 表示我们得到的是什么。
ELMo
embedding 本身具有局限性,最主要的缺点是无法解决一词多义问题,不同的词在不同的上下文中会有不同的意思,而embedding 对模型中的每个词都分配了一个固定的表示。
什么是viterbi 算法
https://www.zhihu.com/question/20136144/answer/763021768
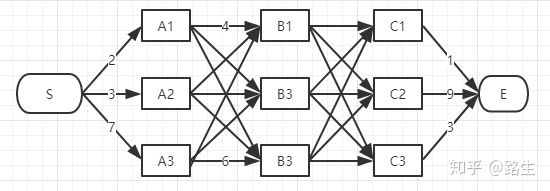
如何找到s到e之间的最短距离?
先分别找到s-b1 、s-b2 、s-b3 的三个最短的距离;然后继续找 s-c1、 s-c2、s-c3 的三个最短距离;最后比较 s-c1-e、s-c2-e、s-c3-e的距离,求的最小距离;
什么是Dropout
我们在前向传播的时候,让某个神经元的激活值以一定的概率p停止工作,这样可以使模型泛化性更强,因为它不会太依赖某些局部的特征
LSTM
LSTM网络,全称是long short term memory。是一种特殊的RNN,与一般的RNN区别是中间的更新状态的方式不同。
https://zhuanlan.zhihu.com/p/38063427
预训练
先用别的大量的语料数据预先训练出通用性强的词向量然后根据需要进行微调或者直接应用到具体任务上去。
词向量一般是通过语言模型训练出来的,一般的训练方法有用上下文预测下一个词(CBOW模型),用中心词预测上下文(skip-gram模型)等。
预训练的方法最初是在图像领域提出的,达到了良好的效果,后来被应用到自然语言处理。预训练一般分为两步,首先用某个较大的数据集训练好模型(这种模型往往比较大,训练需要大量的内存资源),使模型训练到一个良好的状态,然后下一步根据不同的任务,改造预训练模型,用这个任务的数据集在预训练模型上进行微调。
这种做法的好处是训练代价很小,预训练的模型参数可以让新的模型达到更快的收敛速度,并且能够有效地提高模型性能,尤其是对一些训练数据比较稀缺的任务,在神经网络参数十分庞大的情况下,仅仅依靠任务自身的训练数据可能无法训练充分,预训练方法可以认为是让模型基于一个更好的初始状态进行学习,从而能够达到更好的性能。
预训练指提前训练好这种词向量,对应的是一些任务可以输入词id,然后在做具体的任务内部训练词向量,这样出来的词向量不具有通用性,而预训练的词向量,是在极大样本上训练的结果,有很好的通用性,无论什么任务都可以直接拿来用具体的训练方法,从最开始的word2vec,elmo到现在的bert,层出不穷,百度最近也出了个ernie,对标bert。
目前主流的BERT、ELMo、ULMFiT 、OpenAI等 的 词向量预训练 是用大量的别的开放的语料数据训练语言模型的底层特征;我们的语言系统充斥着许多复杂的现象,如语义合成性、多义性、指代、长期依赖、一致性和否定等,这些被认为是语言的浅层表征。因此在对浅层表征进行模型的训练后,才能有完整层次结构,能够到达高级语义概念。
dropout
dropout就是在训练的时候随机的使一部分神经元冻结
正则化
正则化相当于一个惩罚项,可以防止模型变得过于复杂。
1)L0范数
L0范数是指参数矩阵W中含有零元素的个数,L0范数限制了参数的个数不会过多,这也就简化了模型,当然也就能防止过拟合。
2)L1范数
L1范数是参数矩阵W中元素的绝对值之和,L1范数相对于L0范数不同点在于,L0范数求解是NP问题,而L1范数是L0范数的最优凸近似,求解较为容易。L1常被称为LASSO.
3)L2范数
L2范数是参数矩阵W中元素的平方之和,这使得参数矩阵中的元素更稀疏,与前两个范数不同的是,它不会让参数变为0,而是使得参数大部分都接近于0。L1追求稀疏化,从而丢弃了一部分特征(参数为0),而L2范数只是使参数尽可能为0,保留了特征。L2被称为Rigde.
finetune
fine-tune是迁移学习中的一个概念。bert就可以看作是一种迁移学习。
迁移学习就是先用一些通用数据进行训练,再根据实际任务进行单独的训练。
比如bert,bert就是google用维基的中文语料进行的预训练产生的模型。
(就是bert里的那个非常大的ckpt文件)
然后我们在要用的时候再根据自己的任务对模型进行针对性的训练(fine-tune),让它执行针对性的任务。
我的理解是预训练的时候应该是要冻结输出层的,只训练中间层,类似于构造生成词向量的过程。然后我们fine-tune的时候主要是对输出层进行训练,道理类似于根据已有的词向量构造预测的过程。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号