elasticsearch原理学习笔记
https://mp.weixin.qq.com/s/dn1n2FGwG9BNQuJUMVmo7w
感谢,透彻的讲解
整理笔记
请说出 唐诗中 包含 前 的诗句
......
其实你都会,只是想不起来,
“窗前明月光”
因为在你大脑中的 索引方式是
静夜思---床前明月光,疑是地上霜,举头望明月,低头思故乡
这就需要 倒排索引
倒排索引就是 前---窗前明月光
前--遥望瀑布挂前川
。。。。。。
那样就意味着 所有的文字都要 以这样的方式建立索引喽
这就是搜索引擎的原理!倒排索引
那样文件量是不是会很大呢?
索引会不会很多?如果文字量大(一篇1000字的文章),而且索引的维护量会不会很大啊
没问题,我们想办法,首先
正向压缩, 例如 前 ---静夜思
前--望庐山瀑布
.....
这样,就不用存每首诗的全文了。
还能不能更好呢?
如果是把静夜思 转化成key,是不是更简单。
如果是把所有的诗,搭建一个矩阵 是不是 更简单!
第二步:
建立索引前 要 先分词,然后再见索引 (那要建立多少词啊)
没关系,一篇文章里不用所有的词都建立索引吧, 想 的 是 嗯 等等 这样的词,不用建立索引了吧。
那么 引入 停用词 词库,可以把这些无关紧要的屏蔽掉了。
最后再说 ES的原理,
先有一个 叫 lucene 的库,后来又有人基于lucene进行封装,写出了elasticsearch
es将对搜索引擎的操作 全部封装成为基于restful 的 api,通过 http请求,对其进行操作。
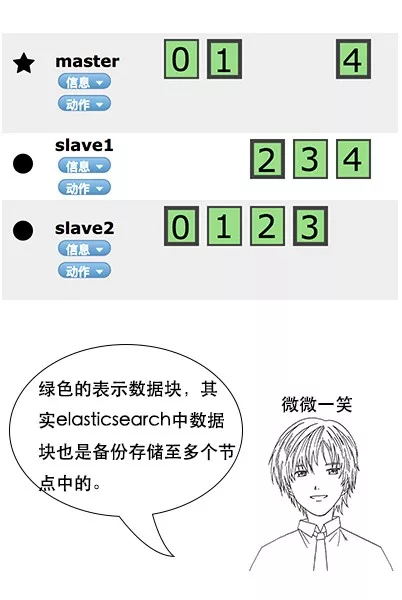
数据量大量呢,还可以通过分布式,搭建多台服务器
怎么把数据存进去呢?
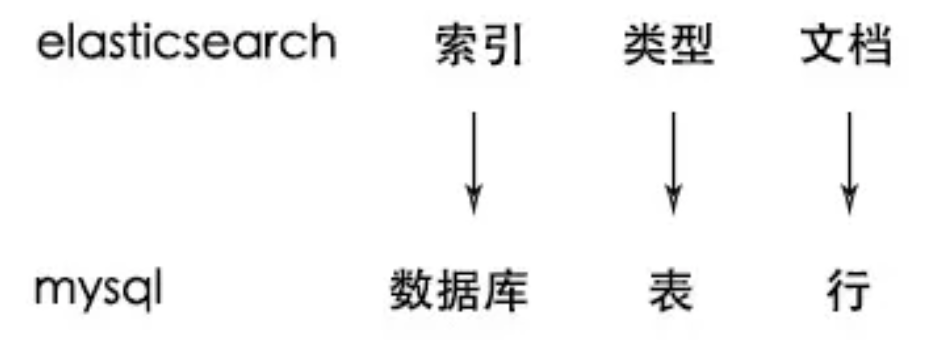
比如一首诗,有诗题、作者、朝代、字数、诗内容等字段,那么首先,我们可以建立一个名叫poems的索引,然后创建一个名叫poem的类型,类型是通过mapping来定义每个字段的类型,比如诗题、作者、朝代都是keyword类型,诗内容是text类型,而字数是integer类型,最后就是把数据组织成json格式存放进去了。

keyword 和text都是字符串类型的,区别就是 keyword 不会被分词,text要被分词。
keyword类型是不会分词的,直接根据字符串内容建立反向索引,text类型在存入elasticsearch的时候,会先分词,然后根据分词后的内容建立反向索引。
elasticsearch分布式原理
es会对数据进行切片,每一个分片会保存多个副本,为了保证分布式环境下的高可用