全网独发gensim中similarities.Similarity用法
index = similarities.MatrixSimilarity(lsi[corpus]) #
管网的原文翻译如下:
警告:similarities.MatrixSimilarity类仅仅适合能将所有的向量都在内存中的情况。例如,如果一个百万文档级的语料库使用该类,可能需要2G内存与256维LSI空间。
如果没有足够的内存,你可以使用similarities.Similarity类。该类的操作只需要固定大小的内存,因为他将索引切分为多个文件(称为碎片)存储到硬盘上了。它实际上使用了similarities.MatrixSimilarity和similarities.SparseMatrixSimilarity两个类,因此它也是比较快的,虽然看起来更加复杂了。
现在我就是大语料库,MatrixSimilarity这个类运行,就报错 Memory Error
可是关于similarities.Similarity 用法 在哪里呢??在哪里呢??在哪里呢??在哪里呢??
搜尽全网都没有答案,最可恶的是管网也不提这个用法。你不写参数,我知道咋用啊。
感恩,感恩
https://stackoverflow.com/questions/36578341/how-to-use-similarities-similarity-in-gensim
一位小哥写了这样的答案
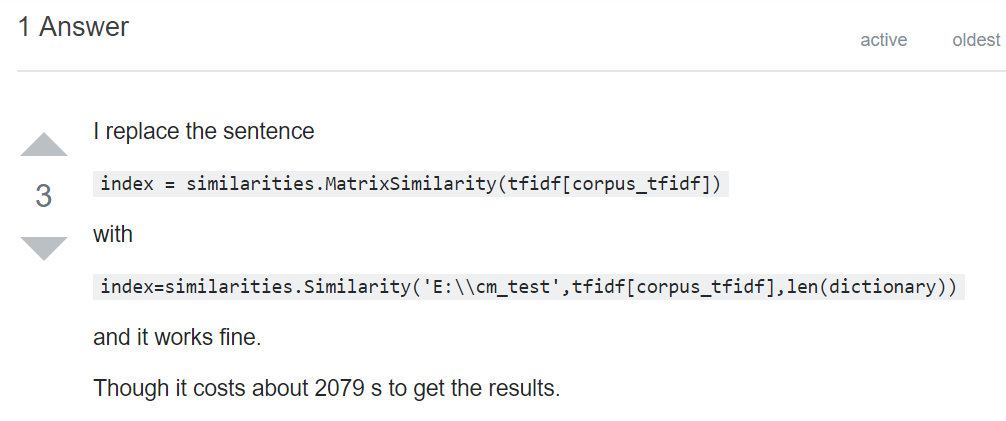
可是可是 三个参数什么意思呢?
猜了半天,终于明白了。
中文解释一下:
第一个参数 就是‘E:\\cm_test’ ,是一个地址,这个地址,我猜是用来存放缓存文件的。
第二个参数 是tfidf向量化的语料库
第三个参数 是你的语料库文本的数量,我的数量是42万多行,如实写上
终于运行通过,


 浙公网安备 33010602011771号
浙公网安备 33010602011771号