说说GIL
上一篇:线程深入篇引入
Code:https://github.com/lotapp/BaseCode/tree/master/python/5.concurrent/Thread/3.GIL
说说GIL
尽管Python完全支持多线程编程, 但是解释器的C语言实现部分在完全并行执行时并不是线程安全的,所以这时候才引入了GIL
解释器被一个全局解释器锁保护着,它确保任何时候都只有一个Python线程执行(保证C实现部分能线程安全) GIL最大的问题就是Python的多线程程序并不能利用多核CPU的优势 (比如一个使用了多个线程的计算密集型程序只会在一个单CPU上面运行)
注意:GIL只会影响到那些严重依赖CPU的程序(比如计算型的)如果你的程序大部分只会涉及到I/O,比如网络交互,那么使用多线程就很合适 ~ 因为它们大部分时间都在等待(线程被限制到同一时刻只允许一个线程执行这样一个执行模型。GIL会根据执行的字节码行数和时间片来释放GIL,在遇到IO操作的时候会主动释放权限给其他线程)
所以Python的线程更适用于处理I/O和其他需要并发执行的阻塞操作,而不是需要多处理器并行的计算密集型任务(对于IO操作来说,多进程和多线程性能差别不大)【计算密集现在可以用Python的Ray框架】
网上摘取一段关于IO密集和计算密集的说明:(IO密集型可以结合异步)
计算密集型任务的特点是要进行大量的计算,消耗CPU资源,比如计算圆周率、对视频进行高清解码等等,全靠CPU的运算能力。这种计算密集型任务虽然也可以用多任务完成,但是任务越多,花在任务切换的时间就越多,CPU执行任务的效率就越低,所以,要最高效地利用CPU,计算密集型任务同时进行的数量应当等于CPU的核心数。
计算密集型任务由于主要消耗CPU资源,因此,代码运行效率至关重要。Python这样的脚本语言运行效率很低,完全不适合计算密集型任务。对于计算密集型任务,最好用C语言编写。
第二种任务的类型是IO密集型,涉及到网络、磁盘IO的任务都是IO密集型任务,这类任务的特点是CPU消耗很少,任务的大部分时间都在等待IO操作完成(因为IO的速度远远低于CPU和内存的速度)。对于IO密集型任务,任务越多,CPU效率越高,但也有一个限度。常见的大部分任务都是IO密集型任务,比如Web应用。
IO密集型任务执行期间,99%的时间都花在IO上,花在CPU上的时间很少,因此,用运行速度极快的C语言替换用Python这样运行速度极低的脚本语言,完全无法提升运行效率。对于IO密集型任务,最合适的语言就是开发效率最高(代码量最少)的语言,脚本语言是首选,C语言最差。
Process and Thread Test
其实用不用多进程看你需求,不要麻木使用,Linux下还好点,Win下进程开销就有点大了(好在服务器基本上都是Linux,程序员开发环境也大多Linux了)这边只是简单测了个启动时间差距就来了,其他的都不用测试了
测试Code:
from time import sleep
from multiprocessing import Process
def test(i):
sleep(1)
print(i)
def main():
t_list = [Process(target=test, args=(i, )) for i in range(1000)]
for t in t_list:
t.start()
if __name__ == '__main__':
main()
运行时间:
real 0m3.980s
user 0m2.034s
sys 0m3.119s
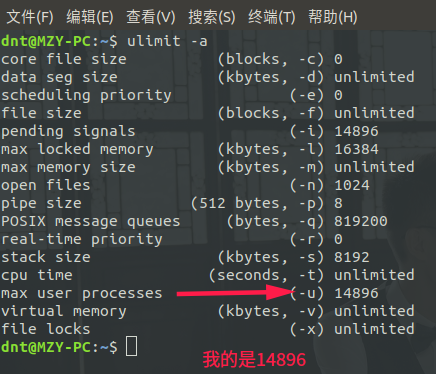
操作系统几千个进程开销还是有点大的(毕竟进程是有上线的)ulimit -a
测试Code:
from time import sleep
from multiprocessing.dummy import Process
def test(i):
sleep(1)
print(i)
def main():
t_list = [Process(target=test, args=(i, )) for i in range(1000)]
for t in t_list:
t.start()
if __name__ == '__main__':
main()
运行时间:
real 0m1.130s
user 0m0.158s
sys 0m0.095s
multiprocessing.dummy里面的Process上面也说过了,就是在线程基础上加点东西使得用起来和multiprocessing的Process编程风格基本一致(本质还是线程)
测试Code:
from time import sleep
from multiprocessing.dummy import threading
def test(i):
sleep(1)
print(i)
def main():
t_list = [threading.Thread(target=test, args=(i, )) for i in range(1000)]
for t in t_list:
t.start()
if __name__ == '__main__':
main()
运行时间:
real 0m1.123s
user 0m0.154s
sys 0m0.085s
其实Redis就是使用单线程和多进程的经典,它的性能有目共睹。所谓性能无非看个人能否充分发挥罢了。不然就算给你轰炸机你也不会开啊?扎心不老铁~
PS:线程和进程各有其好处,无需一棍打死,具体啥好处可以回顾之前写的进程和线程篇~
利用共享库来扩展
C系扩展
GIL是Python解释器设计的历史遗留问题,多线程编程,模型复杂,容易发生冲突,必须用锁加以隔离,同时,又要小心死锁的发生。Python解释器由于设计时有GIL全局锁,导致了多线程无法利用多核。计算密集型任务要真正利用多核,除非重写一个不带GIL的解释器(PyPy)如果一定要通过多线程利用多核,可以通过C扩展来实现(Python很多模块都是用C系列写的,所以用C扩展也就不那么奇怪了)
只要用C系列写个简单功能(不需要深入研究高并发),然后使用ctypes导入使用就行了:
#include <stdio.h>
void test()
{
while(1){}
}
编译成共享库:gcc 2.test.c -shared -o libtest.so
使用Python运行指定方法:(太方便了,之前一直以为C#调用C系列最方便,用完Python才知道更简方案)
from ctypes import cdll
from os import cpu_count
from multiprocessing.dummy import Pool
def main():
# 加载C共享库(动态链接库)
lib = cdll.LoadLibrary("./libtest.so")
pool = Pool() # 默认是系统核数
pool.map_async(lib.test, range(cpu_count()))
pool.close()
pool.join()
if __name__ == '__main__':
main()
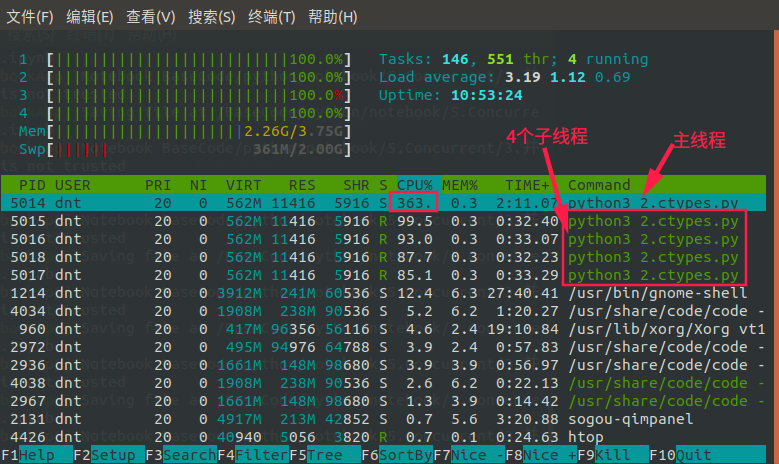
看看这时候HTOP的信息:(充分利用多核)【ctypes在调用C时会自动释放GIL】
Go扩展
利用Go写个死循环,然后编译成so动态链接库(共享库):
package main
import "C"
//export test
func test(){
for true{
}
}
func main() {
test()
}
非常重要的事情://export test一定要写,不然就被自动改成其他名字(我当时被坑过)
Python调用和上面一样:
from ctypes import cdll
from os import cpu_count
from multiprocessing.dummy import Pool
def main():
# 加载动态链接库
lib = cdll.LoadLibrary("./libtestgo.so")
pool = Pool() # 默认是系统核数
pool.map_async(lib.test, range(cpu_count()))
pool.close()
pool.join()
if __name__ == '__main__':
main()
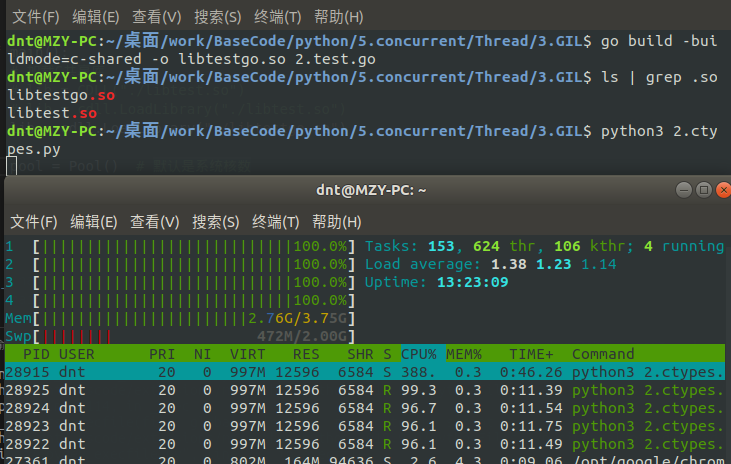
效果:go build -buildmode=c-shared -o libtestgo.so 2.test.go
题外话~如果想等CPython的GIL消失可以先看一个例子:MySQL把大锁改成各个小锁花了5年。在是在MySQL有专门的团队和公司前提下,而Python完全靠社区重构就太慢了
速度方面微软除外,更新快本来是好事,但是动不动断层更新,这学习成本就太大了(这也是为什么Net能深入的人比较少的原因:人家刚深入一个,你就淘汰一个了...)
可能还有人不清楚,贴下官方推荐技术吧(NetCore、Orleans、EFCore、ML.Net、CoreRT)
https://github.com/aspnet/AspNetCore
https://github.com/aspnet/EntityFrameworkCore
https://github.com/dotnet/machinelearning
https://github.com/dotnet/orleans
https://github.com/aspnet/Mvc
https://github.com/dotnet/corert
课外拓展:
用go语言给python3开发模块
https://www.jianshu.com/p/40e069954804
https://blog.filippo.io/building-python-modules-with-go-1-5
Python与C/C++相互调用
https://www.cnblogs.com/apexchu/p/5015961.html
使用C/C++代码编写Python模块
https://www.cnblogs.com/silvermagic/p/9087896.html
快速实现python c扩展模块
https://www.cnblogs.com/chengxuyuancc/p/6374239.html
Python的C语言扩展
https://python3-cookbook.readthedocs.io/zh_CN/latest/chapters/p15_c_extensions.html
python调用golang生成的so库
https://studygolang.com/articles/10228
https://www.cnblogs.com/huangguifeng/p/8931837.html
python调用golang并回调
https://blog.csdn.net/gtd138/article/details/79801235
Python3.x AttributeError: libtest.so: undefined symbol: fact
https://www.cnblogs.com/tanglizi/p/8965230.html
运行在其他编译器上
先看最重要的一点,一旦运行在其他编译器意味着很多Python第三方库可能就不能用了,相对来说PyPy兼容性是最好的了
如果是Python2系列我推荐谷歌的grumpy
Grumpy是一个 Python to Go 源代码转换编译器和运行时。旨在成为CPython2.7的近乎替代品。关键的区别在于它将Python源代码编译为Go源代码,然后将其编译为本机代码,而不是字节码。这意味着Grumpy没有VM
已编译的Go源代码是对Grumpy运行时的一系列调用,Go库提供与 Python C API类似的目的
如果是Python3系列,可以使用PyPy PythonNet Jython3 ironpython3等等
PyPy:https://bitbucket.org/pypy/pypy
Net方向:
https://github.com/pythonnet/pythonnet
https://github.com/IronLanguages/ironpython3
Java方向:
https://github.com/jython/jython3
Other:
源码:https://github.com/sbinet/go-python
参考:https://studygolang.com/articles/13019
可惜CoreRT一直没完善,不然就Happy了
https://github.com/dotnet/corert
经验:平时基本上多线程就够用了,如果想多核利用-多进程基本上就搞定了(分布式走起)实在不行一般都是分析一下性能瓶颈在哪,然后写个扩展库
如果需要和其他平台交互才考虑上面说的这些项目。如果是Web项目就更不用担心了,现在哪个公司还不是混用?JavaScript and Python and Go or Java or NetCore。基本上上点规模的公司都会用到Python,之前都是Python and Java搭配使用,这几年开始慢慢变成Python and Go or NetCore搭配使用了~
下集预估:Actor模型 and 消息发布/订阅模型

 浙公网安备 33010602011771号
浙公网安备 33010602011771号