
Hbase架构
HBase是一个分布式的、面向列的开源数据库,它不同于一般的关系数据库,是一个适合于非结构化数据存储的数据库。另一个不同的是HBase基于列的而不是基于行的模式。HBase使用和 BigTable非常相同的数据模型。用户存储数据行在一个表里。一个数据行拥有一个可选择的键和任意数量的列,一个或多个列组成一个ColumnFamily,一个Fmaily下的列位于一个HFile中,易于缓存数据。表是疏松的存储的,因此用户可以给行定义各种不同的列。在HBase中数据按主键排序,同时表按主键划分为多个Region。
在分布式的生产环境中,HBase 需要运行在 HDFS 之上,以 HDFS 作为其基础的存储设施。HBase 上层提供了访问的数据的 Java API 层,供应用访问存储在 HBase 的数据。在 HBase 的集群中主要由 Master 和 Region Server 组成,以及 Zookeeper,具体模块如下图所示:
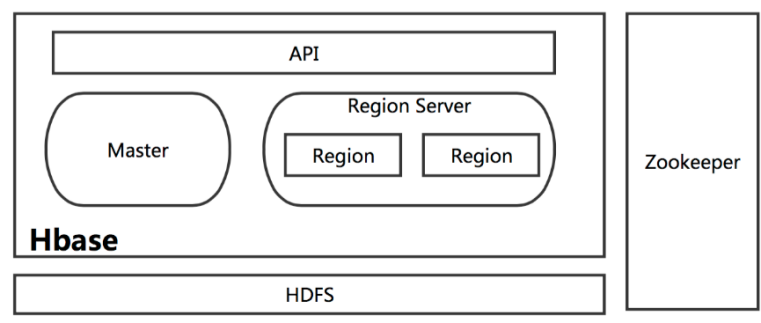
1、两个基本角色:
Hmaster、RegionServer
2、文件系统和数据处理:
依赖于HDFS、MapReduce
3、协调服务:
依赖于Zookeeper
Client职责
包含访问hbase的接口,client维护着一些cache来加快对hbase的访问,比如regione的位置信息。
Zookeeper职责
- 保证任何时刻,集群之中只能有一个master
- 存储所有的Region的寻址入口
- 实时监控Region Server的状态,将Region server的上下线信息实时通知给Master
- 存储Hbase的schema,包括有哪些table,每个table有哪些column family
Hmaster职责
- 为Region server分配region
- 负责region server的负载均衡
- 发现失效的region server并重新分配其上的region
- GFS上的垃圾文件回收
- 处理schema更新请求
Region Server职责
- Region server维护Master分配给它的region,处理对这些region的IO请求
- Region server负责切分在运行过程中变得过大的region
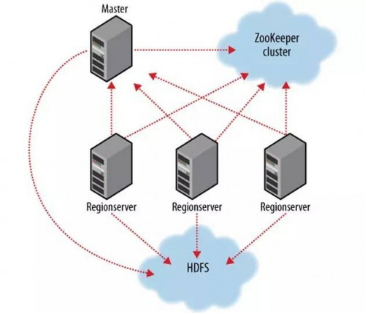
可以看到,client访问hbase上数据的过程并不需要master参与(寻址访问zookeeper和region server,数据读写访问regione server),master仅仅维护者table和region的元数据信息,负载很低。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号