
HDFS写数据和读数据流程
HDFS数据存储
HDFS client上传数据到HDFS时,首先,在本地缓存数据,当数据达到一个block大小时。请求NameNode分配一个block。
NameNode会把block所在的DataNode的地址告诉HDFS client。 HDFS client会直接和DataNode通信,把数据写到DataNode节点一个block文件里。
核心类DistributedFileSystem
HDFS写数据流程
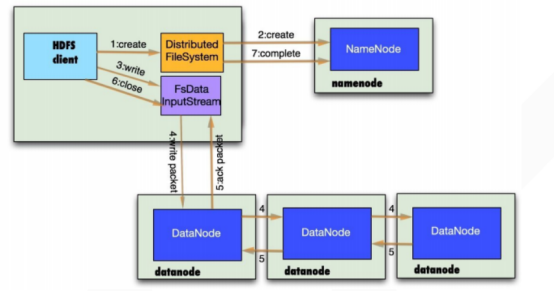
客户端要向HDFS写数据,首先要跟namenode通信以确认可以写文件并获得接收文件block的datanode,然后,
客户端按顺序将文件逐个block传递给相应datanode,并由接收到block的datanode负责向其他datanode复制block的副本。
具体流程如下:
1、与namenode通信请求上传文件,namenode检查目标文件是否已存在,父目录是否存在
2、namenode返回是否可以上传
3、client请求第一个 block该传输到哪些datanode服务器上
4、namenode返回3个datanode服务器ABC
5、client请求3台dn中的一台A上传数据(本质上是一个RPC调用,建立pipeline),A收到请求会继续调用B,然后B调用C,将整个pipeline建立完成,逐级返回客户端
6、client开始往A上传第一个block(先从磁盘读取数据放到一个本地内存缓存),以packet为单位,A收到一个packet就会传给B,B传给C;A每传一个packet会放入一个应答队列等待应答
7、当一个block传输完成之后,client再次请求namenode上传第二个block的服务器。
HDFS读数据流程
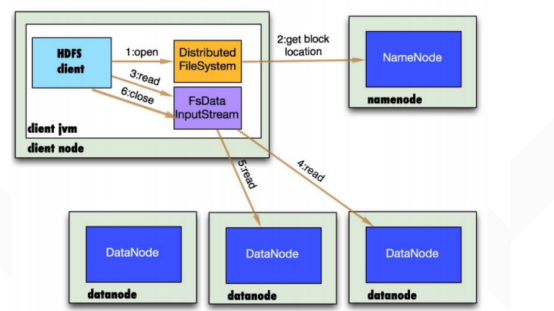
1、 读取文件名称
2、 向namenode获取文件第一批block位置,这个block会根据副本数返回对应数量的locations数,依据网络拓扑结构排序,距离client端的排在前面,
从原理来说,是通过DistributedFileSystem对象调用getFileBlockLocations来获取locations
3、 获取距离clinet最近的datanode并与其建立通信,数据会源源不断的写入clinet端,假设第一个block读取完成,则关闭指向该datanode的连接,接着读取下一个block,以此类推。
假设所有的块都读取完了,则把所有的流都关闭。
实际上,也是通过DistributedFileSystem来open一个流对象,将其封装到DFSInputStream对象当中,block读取可以查看接口BlockReader.
4、如果读取的过程出现DN出现异常(比如通信异常),则会尝试去读取第二个优先位置的datanode,并且记录该错误的datanode,剩余的blocks读取的时候直接跳过该datanode
DFSInputStream也会检查block数据校验和,假设发现一个坏的block,就会先报告到namenode节点,然后DFSInputStream在其它的datanode上读该block的镜像。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号