
SparkStreaming和Kafka的整合
当我们正确地部署好Spark Streaming,我们就可以使用Spark Streaming提供的零数据丢失机制。需要满足以下几个先决条件:
1、输入的数据来自可靠的数据源和可靠的接收器;
2、应用程序的metadata被application的driver持久化了(checkpointed );
3、启用了WAL特性(Write ahead log)。
1. 可靠的数据源和可靠的接收器
可以从接收器挂掉的情况下恢复(或者是接收器运行的Exectuor和服务器挂掉都可以)
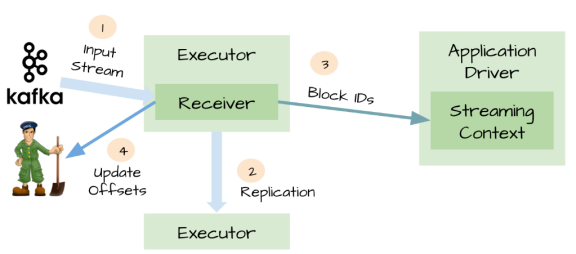
对于一些输入数据源(比如Kafka),Spark Streaming可以对已经接收的数据进行确认。输入的数据首先被接收器(receivers )所接收,
然后存储到Spark中(默认情况下,数据保存到2个执行器中以便进行容错)。数据一旦存储到Spark中,接收器可以对它进行确认
(比如,如果消费Kafka里面的数据时可以更新Zookeeper里面的偏移量)。
这种机制保证了在接收器突然挂掉的情况下也不会丢失数据:
因为数据虽然被接收,但是没有被持久化的情况下是不会发送确认消息的。所以在接收器恢复的时候,数据可以被原端重新发送。
2. 元数据持久化(Metadata checkpointing)
对应用程序的元数据进行Checkpint,Driver可以将应用程序的重要元数据持久化到可靠的存储中(如HDFS)
然后Driver可以利用这些持久化的数据进行恢复。元数据包括:
1、配置;
2、代码;
3、那些在队列中还没有处理的batch(仅仅保存元数据,而不是这些batch中的数据)
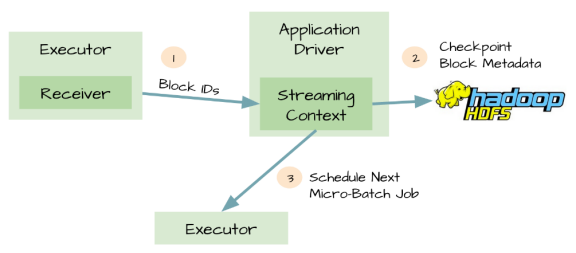
由于有了元数据的Checkpint,所以Driver可以利用他们重构应用程序,而且可以计算出Driver挂掉的时候应用程序执行到什么位置。
3. 可能存在数据丢失的场景
1、两个Exectuor已经从接收器中接收到输入数据,并将它缓存到Exectuor的内存中;
2、接收器通知输入源数据已经接收;
3、Exectuor根据应用程序的代码开始处理已经缓存的数据;
4、这时候Driver突然挂掉了;
5、从设计的角度看,一旦Driver挂掉之后,它维护的Exectuor也将全部被kill;
6、既然所有的Exectuor被kill了,所以缓存到它们内存中的数据也将被丢失。结果,这些已经通知数据源但是还没有处理的缓存数据就丢失了;
7、缓存的时候不可能恢复,因为它们是缓存在Exectuor的内存中,所以数据被丢失了。
4.WAL(Write ahead log)
针对上面情况,Spark Streaming 1.2开始引入了WAL机制。
启用了WAL机制,所以已经接收的数据被接收器写入到容错存储中(如HDFS),Driver可以从失败的点重新读取数据,即使Exectuor中内存的数据已经丢失了
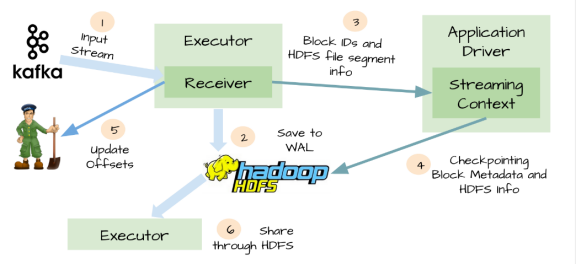
WAL虽然可以办证数据不丢失,但不能保证对数据源exactly-once语义,只读一次数据:
接收器接收数据并存储在WAL中,开始消费数据,在接收器向zookeeper更新偏移量之前,Executor挂掉了,
等Executor恢复会重新读取那些保存到WAL中但未被消费的数据,当从WAL读取完数据后,又开始消费数据,
因为接收器是采用Kafka的High-Level Consumer API实现的,它开始从Zookeeper当前记录的偏移量开始读取数据,
由于Zookeeper的偏移量没有更新,所以有些数据回被重复消费
WAL的缺点:
1、WAL减少了接收器的吞吐量,因为接受到的数据必须保存到可靠的分布式文件系统中。
2、对于一些输入源来说,它会重复相同的数据。比如当从Kafka中读取数据,你需要在Kafka的brokers中保存一份数据,而且你还得在Spark Streaming中保存一份。
5. Kafka direct API
为了解决由WAL引入的性能损失,并且保证 exactly-once 语义,Spark Streaming 1.3中引入了名为Kafka direct API。
Spark driver只需要简单地计算下一个batch需要处理Kafka中偏移量的范围,然后命令Spark Exectuor直接从Kafka相应Topic的分区中消费数据。
换句话说,这种方法把Kafka当作成一个文件系统,然后像读文件一样来消费Topic中的数据。
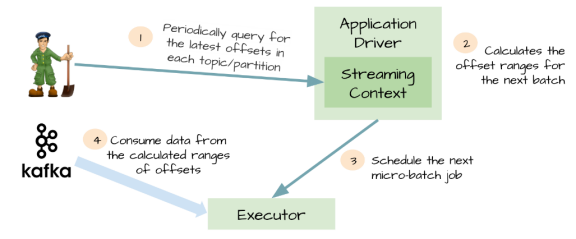
优点:
1、不再需要Kafka接收器,Exectuor直接采用Simple Consumer API从Kafka中消费数据。
2、不再需要WAL机制,我们仍然可以从失败恢复之后从Kafka中重新消费数据;
3、exactly-once语义得以保存,我们不再从WAL中读取重复的数据。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号