

如何生成和分析Dump文件
一、背景介绍
经常定位应用容器问题,会遇到以下问题:
- 容器突然重启,为什么会重启?
- 容器的CPU为什么在不断的冲高?
- 为什么要给容器分配这么多内存,能不能降低一些?
- 怎么获取应用的内存、CPU等信息?
遇到以上的问题,对于纯业务开发人员,感觉两眼摸瞎,不知从和下手,一般就是请教前辈,获取应用的堆栈信息,然后进行分析;但是怎么获取,怎么分析呢?对于新手或者关注业务比较多的开发人员来说,就只能摸着石头过河,不仅慢,而且需要走很多弯路。
针对上面问题,考虑让开发人员能够快速方便的获取应用的堆栈信息,并进行分析。以下介绍EMS的不同部署形式下,dump文件的获取,以及通过一个样例进行分析。
二、解决思路
为解决上述问题,解决方案如下:
首先,从系统的形式化界面出发,需要解决问题是在项目的某个界面可以通过触发某个按钮或者执行什么命令,来实现对应用的堆栈信息dump文件的获取,并进行应用的堆栈和CPU等进行分析;
然后,从容器的角度出发,通过执行相应的命令,产生对应的dump文件,之后取出文件,进行应用的堆栈和CPU等进行分析;
根据EMS的实际情况,发现两钟方式都是可以实现dump文件的获取,但是由于项目的IAAS和PAAS方式部署,获取方式有所不同,需要进行不同的实践;并且目前的项目依赖的JVM是OpenJ9,通过界面获取会存在一些的问题;
最后,对dump的文件分析过程,依赖JCA工具或者MAT都可以,需要对具体的信息做具体的分析;
三、实践情况
1.获取堆栈信息的dump文件
(1) 通过命令终端获取dump文件
使用kill -3 {Pid} 命令,生成对应应用的dump文件;命令很简单,主要是如何获取应用的进程号,并且系统不同的部署方式,获取的进程号方式不同,以下对不同部署方式下,Pid的获取:
方式一(IAAS/PAAS部署通用)
- containerName //1. 获取容器名称
- containerId=$(docker ps | grep ${containerName} | awk ‘print $1’) //2. 获取容器id
- Docker inspect ${containerId} |grep Pid //获取进程号

- Ps -ef | grep ${Pid} //获取虚机的进程号
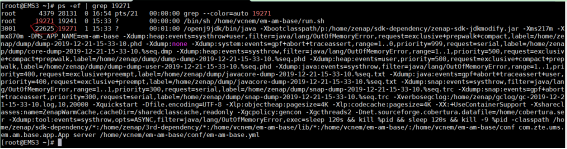
- 最后执行kill -3 {虚机进程号},也就是 kill -3 22625,即可以生成堆栈的快照文件。
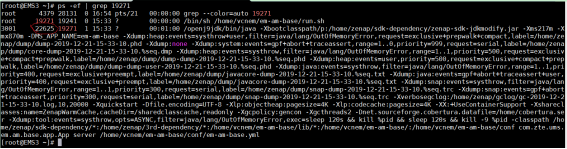
方式二(进入容器内执行)——前提是容器正常可以进入
- 更直接的方式可以直接进入容器内获取对应的进程号,并执行kill -3 ${Pid};
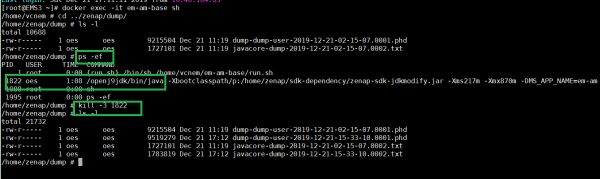
方式三(IAAS部署)
- 在MSB上获取应用的实例端口

- netstat -anp | grep ${port } //获取进程号

- 最后执行kill -3 进程号 获取堆栈快照文件
- 分析dump文件信息
通过上面命令获取的dump文件有两种格式javacore-dump-***.txt 和 dump-dump-***.phd。
javacore-dump-***.txt 文件: 通常主要是关于应用的cpu使用情况,以及java进程的快照,主要保存的是应用各个线程在某一时刻的运行的位置,即JVM执行的具体位置,包括类方法和对应的行,即threaddump文件。
dump-dump-***.phd : 通常主要是关于应用memory的详细情况,即对应的heapdump文件,heapdump文件是一个二进制镜像文件,是某个时刻java堆栈的快照,并且保存JVM堆中对象的使用情况。
四、样例分析
以下是通过kill -3 ${进程号} 获取javacore-dump-***.txt文件为例,使用jca工具进行分析(以简单的线程使用情况分析为例):
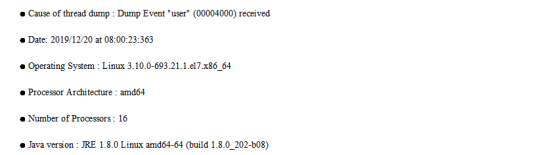
1. 首先,查看改文件产生的原因
如下图,可以看到导致线程快照产生的原因是Dump Event“user”,代表收到SIGQUIT信号(user: SIGQUIT信号,退出信号;gpf:程序一般保护性错误导致系统崩溃systhrow:JVM 内部抛出的异常)
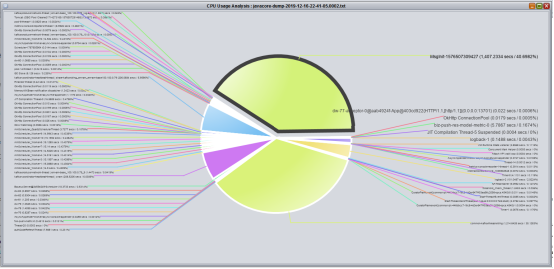
2. 然后,可以查看CPU使用情况
从下图可以看出Msginit线程和kafka 消费线程使用CPU过高,根据对应的代码流程,可以发现在应用启动时,会创建一个初始化线程,需要进行本地IO的读写,外部接口的调用,需要注册都是在该线程进行的处理,需要对其进行优化;kafka消费线程一直保持着比较高的CPU的占用率,主要原因是一个线程注册的主题太多导致;
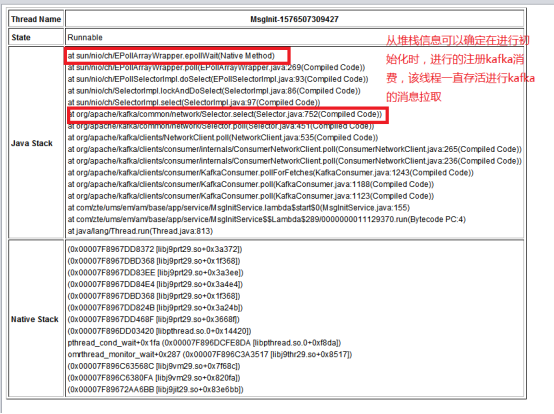
3. 根据上面的两个线程CPU使用过高,查询两个线程的堆栈信息
首先,查看MsgInit线程的堆栈信息,发现从CPU初步分析的结果只是大略的确定线程的问题是本地IO读写,注册等原因,从下图的堆栈可以发现,原因是kafka的注册消费导致的,线程注册kafka后一直在拉取信息进行处理;
然后,从kafka消费线程可以看出消费的消息过多和注册的主题过多导致;
最后,确定都与kafka的消费有关系;
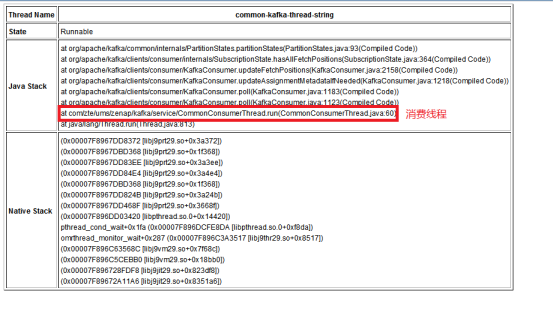
4. 最后,可以确定性能瓶颈出现在kafka消费过程中,可以增加线程对消费过程进行处理。
五、后续思考
- 当前的样例分析很简单,仅是对突出的两个线程使用情况进行分析,没有充分利用dump文件中的其他信息,其中还有一些内存使用情况分析、其他线程堆栈分析,以及线程的比较分析和监控器等。可以发现对JVM使用情况的分析不同的场景以及不同的应用关注点不同,需要分析的内容不同,线程、内存情况、堆栈情况或者堆中的对象使用情况等等各不相同。
- 对dump文件的获取尽量向界面化发展,让分析人员可以在应用界面就可以获取文件进行分析;
- 应总结多种场景的dump文件,并输出不同的样例,以便开发人员能够根据不同场景快速的获取分析流程,以及做出相应的处理;
六、相关链接
l https://www.ibm.com/support/pages/ibm-thread-and-monitor-dump-analyzer-java-tmda
l https://www.cnblogs.com/mu-tou-man/p/5619354.html


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 记一次.NET内存居高不下排查解决与启示
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· 【自荐】一款简洁、开源的在线白板工具 Drawnix